Distributional Semantics Tracing: A Framework for Explaining Hallucinations in Large Language Models
作者: Gagan Bhatia, Somayajulu G Sripada, Kevin Allan, Jacobo Azcona
分类: cs.CL, cs.AI, cs.CE
发布日期: 2025-10-07 (更新: 2025-10-08)
💡 一句话要点
提出分布语义追踪框架,解释大语言模型中的幻觉现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉 可解释性 分布语义 因果推理
📋 核心要点
- 大语言模型存在幻觉问题,即生成看似合理但错误的陈述,现有方法缺乏对其内在机制的深入理解。
- 论文提出分布语义追踪(DST)框架,结合可解释性技术,构建模型推理的因果图,追踪语义失败。
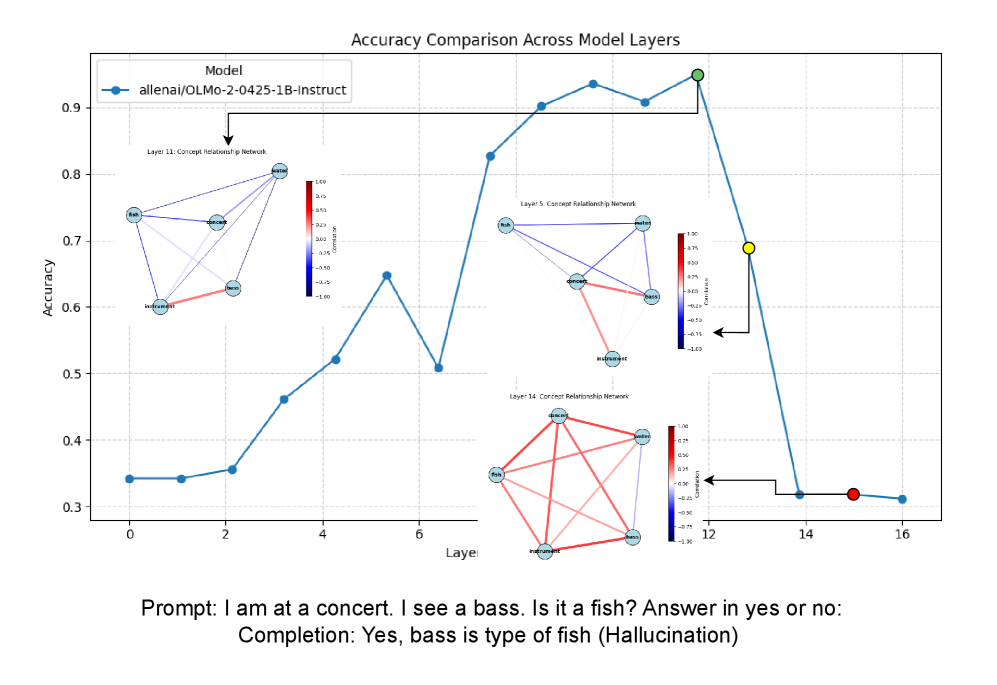
- 研究发现模型存在“承诺层”,内部表示在此层不可逆转地偏离事实,且上下文路径的连贯性与幻觉率呈负相关。
📝 摘要(中文)
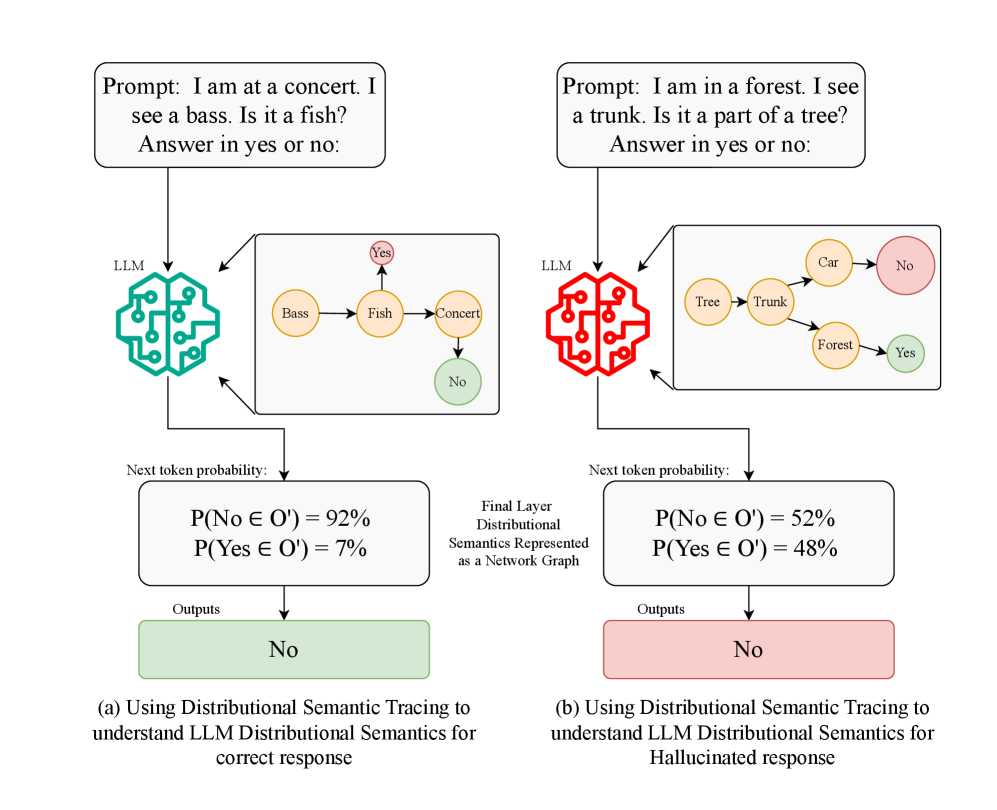
大型语言模型(LLM)容易产生幻觉,即生成看似合理但实际上不正确的陈述。本文通过三个主要贡献,研究了这种失败模式的内在架构根源。首先,为了可靠地追踪内部语义失败,我们提出了分布语义追踪(DST),这是一个统一的框架,它整合了已建立的可解释性技术,以产生模型推理的因果图,将意义视为上下文的函数(分布语义)。其次,我们确定了模型中幻觉变得不可避免的层,识别出一个特定的承诺层,在该层中,模型的内部表示不可逆转地偏离了事实。第三,我们确定了这些失败的潜在机制。我们观察到不同计算路径之间的冲突,我们使用双过程理论的视角来解释这种冲突:一种快速的、启发式的联想路径(类似于系统1)和一种缓慢的、慎重的、上下文路径(类似于系统2),导致可预测的失败模式,例如推理捷径劫持。我们的框架量化上下文路径一致性的能力揭示了与幻觉率的强负相关性(ρ= -0.863),这意味着这些失败是内部语义薄弱的可预测结果。最终,我们对Transformer架构中幻觉如何、何时以及为何发生提供了一个机制性的解释。
🔬 方法详解
问题定义:大语言模型(LLM)的幻觉问题,即生成看似合理但与事实不符的内容。现有方法难以解释幻觉产生的内在机制,无法有效定位和缓解幻觉现象。现有方法缺乏对模型内部语义表示的细粒度追踪能力,难以确定幻觉产生的关键阶段和原因。
核心思路:将意义理解为上下文的函数(分布语义),通过追踪模型内部的语义表示变化,构建模型推理的因果图。核心在于识别模型中语义表示偏离事实的关键层(承诺层),并分析导致这种偏离的潜在机制。利用双过程理论(系统1和系统2)解释模型中不同计算路径之间的冲突,从而理解幻觉的产生原因。
技术框架:DST框架包含以下主要阶段:1) 使用可解释性技术(具体技术未明确说明,但应包含注意力机制分析、梯度分析等)提取模型内部的语义表示;2) 构建模型推理的因果图,追踪语义表示在不同层之间的变化;3) 识别“承诺层”,即语义表示开始偏离事实的关键层;4) 分析导致语义表示偏离的潜在机制,例如不同计算路径之间的冲突。
关键创新:1) 提出分布语义追踪(DST)框架,将可解释性技术与分布语义相结合,实现对模型内部语义失败的可靠追踪;2) 识别出模型中存在“承诺层”,为定位和缓解幻觉问题提供了新的视角;3) 利用双过程理论解释幻觉产生的机制,为理解模型推理过程提供了新的思路。
关键设计:论文未详细说明具体的参数设置、损失函数、网络结构等技术细节。但可以推测,DST框架可能需要设计特定的指标来量化语义表示的偏离程度,并可能需要调整模型结构或训练策略来提高上下文路径的连贯性,从而降低幻觉率。负相关系数(ρ= -0.863)表明上下文路径的连贯性与幻觉率之间存在强烈的关联。
🖼️ 关键图片
📊 实验亮点
研究发现上下文路径的连贯性与幻觉率之间存在强烈的负相关性(ρ= -0.863),表明可以通过提高上下文路径的连贯性来降低幻觉率。该研究识别出模型中存在“承诺层”,为定位和缓解幻觉问题提供了关键线索。这些发现为改进大语言模型的设计和训练提供了新的思路。
🎯 应用场景
该研究成果可应用于提升大语言模型的可靠性和可信度,例如在问答系统、文本生成、机器翻译等领域。通过降低幻觉率,可以提高模型输出的准确性和实用性。此外,该研究提出的DST框架可以作为一种通用的模型诊断工具,用于分析和改进其他类型的神经网络模型。
📄 摘要(原文)
Large Language Models (LLMs) are prone to hallucination, the generation of plausible yet factually incorrect statements. This work investigates the intrinsic, architectural origins of this failure mode through three primary contributions. First, to enable the reliable tracing of internal semantic failures, we propose Distributional Semantics Tracing (DST), a unified framework that integrates established interpretability techniques to produce a causal map of a model's reasoning, treating meaning as a function of context (distributional semantics). Second, we pinpoint the model's layer at which a hallucination becomes inevitable, identifying a specific commitment layer where a model's internal representations irreversibly diverge from factuality. Third, we identify the underlying mechanism for these failures. We observe a conflict between distinct computational pathways, which we interpret using the lens of dual-process theory: a fast, heuristic associative pathway (akin to System 1) and a slow, deliberate, contextual pathway (akin to System 2), leading to predictable failure modes such as Reasoning Shortcut Hijacks. Our framework's ability to quantify the coherence of the contextual pathway reveals a strong negative correlation ($ρ= -0.863$) with hallucination rates, implying that these failures are predictable consequences of internal semantic weakness. The result is a mechanistic account of how, when, and why hallucinations occur within the Transformer architecture.