The Valley of Code Reasoning: Scaling Knowledge Distillation of Large Language Models
作者: Muyu He, Muhammad Ali Shafique, Anand Kumar, Tsach Mackey, Nazneen Rajani
分类: cs.CL
发布日期: 2025-10-07
备注: NeurIPS 2025 Workshop on Deep Learning for Code (DL4C), Project page: https://collinear.ai/valley-of-reasoning
💡 一句话要点
揭示代码推理的“山谷”现象:扩展大语言模型知识蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 代码推理 大型语言模型 模型压缩 训练动态
📋 核心要点
- 现有工作缺乏对蒸馏数据量如何影响代码推理能力迁移的深入研究,尤其是在小型模型上。
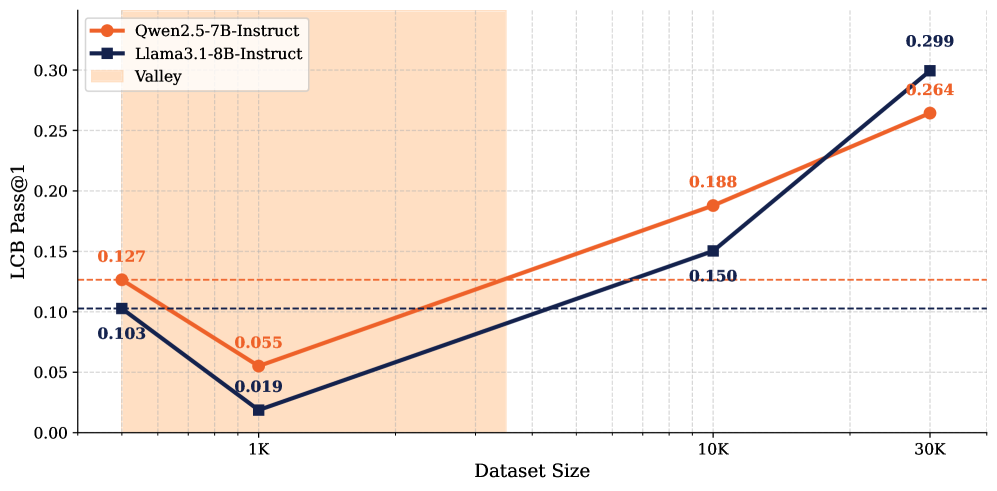
- 该研究通过分析模型在不同数据量下的性能变化,揭示了代码推理能力蒸馏过程中的“山谷”现象。
- 实验表明,在数据量较少时,简单问题更有助于提升小型模型的代码推理能力,且训练数据正确性影响不大。
📝 摘要(中文)
本文研究了将具备推理能力的大型语言模型(LLM)的思维轨迹提炼到小型模型中的扩展趋势。重点关注模型性能如何随蒸馏数据量的变化而变化。研究验证了一个假设,即存在一个“代码推理山谷”:在竞争性编程任务中,随着数据量的增加,下游性能首先下降,然后以超对数线性的方式稳定增长。通过在低数据量和中低数据量阶段对模型进行微调,发现小型模型从简单的编程问题中获益更多。此外,令人惊讶的是,训练数据中输出的正确性对蒸馏结果没有影响。这项工作代表了对直觉之外的代码推理蒸馏训练动态理解的进步。
🔬 方法详解
问题定义:论文旨在研究如何有效地将大型语言模型(LLM)的代码推理能力迁移到小型模型中。现有的知识蒸馏方法虽然有效,但缺乏对蒸馏数据量与模型性能之间关系的深入理解,尤其是在代码推理任务中。现有方法没有充分考虑数据质量和难度对蒸馏效果的影响,可能导致性能下降。
核心思路:论文的核心思路是研究在代码推理任务中,随着蒸馏数据量的增加,小型模型的性能变化趋势。通过观察性能变化,揭示可能存在的“代码推理山谷”现象,即性能先下降后上升。此外,论文还探讨了不同难度和正确性的训练数据对蒸馏效果的影响。
技术框架:该研究主要包含以下几个阶段:1) 使用大型语言模型生成代码推理的训练数据,包括不同难度和正确性的问题及答案。2) 使用这些数据对小型语言模型进行知识蒸馏训练,并监控模型在验证集上的性能。3) 分析模型性能随数据量变化的趋势,验证“代码推理山谷”假设。4) 在不同训练阶段(低数据量和中低数据量)对模型进行微调,以研究不同难度问题的影响。
关键创新:论文最重要的创新点在于发现了代码推理蒸馏中的“山谷”现象,这挑战了传统的直觉,即数据越多越好。此外,论文还发现,在低数据量情况下,简单问题比难题更有助于提升小型模型的代码推理能力,并且训练数据的正确性对蒸馏效果影响不大。
关键设计:论文的关键设计包括:1) 使用两个小型非推理LLM作为学生模型。2) 使用竞争性编程问题作为代码推理任务。3) 通过控制训练数据量来研究性能变化趋势。4) 在不同的训练阶段进行微调,以研究不同难度问题的影响。5) 分析训练数据中输出的正确性对蒸馏结果的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在代码推理任务中存在“山谷”现象,即随着数据量的增加,模型性能先下降后上升。在低数据量和中低数据量阶段,小型模型从简单的编程问题中获益更多。令人惊讶的是,训练数据中输出的正确性对蒸馏结果没有显著影响。这些发现为知识蒸馏的训练策略提供了新的视角。
🎯 应用场景
该研究成果可应用于开发更高效、更轻量级的代码生成和理解模型,例如在资源受限的嵌入式设备或移动设备上部署代码助手。通过理解数据量和难度对蒸馏效果的影响,可以优化训练策略,降低训练成本,并提升小型模型的代码推理能力。未来,该研究可以扩展到其他推理任务,例如数学推理和常识推理。
📄 摘要(原文)
Distilling the thinking traces of a Large Language Model (LLM) with reasoning capabilities into a smaller model has been proven effective. Yet, there is a scarcity of work done on how model performances scale with the quantity of distillation data. In this work, we study the scaling trend of distilling competitive coding skills on two small non-reasoning LLMs. We validate the hypothesis that there is a $\textit{valley of code reasoning}$: downstream performance on competitive coding first drops as data quantity increases, then it steadily increases in a sharper-than-log-linear fashion. Having identified the trend, we further fine-tune the models at two different distillation stages on the same data to ground conclusions on their respective learning phases. We learn that across stages in the low and medium-low data regimes, small models benefit significantly from easier coding questions than from harder ones. We also find that, surprisingly, the correctness of outputs in training data makes no difference to distillation outcomes. Our work represents a step forward in understanding the training dynamics of code reasoning distillation outside intuition