ASPO: Asymmetric Importance Sampling Policy Optimization
作者: Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, Kun Gai
分类: cs.CL
发布日期: 2025-10-07
🔗 代码/项目: GITHUB
💡 一句话要点
ASPO:非对称重要性采样策略优化,提升LLM在强化学习中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 重要性采样 策略优化 非对称学习 token级别裁剪 结果监督强化学习
📋 核心要点
- 现有基于强化学习的LLM后训练方法依赖token级别裁剪,但正向优势token的重要性采样比率不匹配,导致权重不平衡。
- ASPO通过翻转正向优势token的IS比率,使其更新方向与负向token对齐,从而解决权重不平衡问题。
- 实验表明,ASPO能有效缓解过早收敛,提升训练稳定性,并在编码和数学推理任务上超越现有基线。
📝 摘要(中文)
本文针对大型语言模型(LLM)后训练中基于强化学习(RL)的token级别裁剪机制的缺陷进行了研究。作者发现,在结果监督强化学习(OSRL)范式中,正向优势token的重要性采样(IS)比率存在不匹配,导致正向和负向token的权重不平衡。这种不匹配抑制了低概率token的更新,同时过度放大已经高概率的token。为了解决这个问题,作者提出了非对称重要性采样策略优化(ASPO),它采用了一种简单而有效的策略,即翻转正向优势token的IS比率,使其更新方向与负向token的学习动态对齐。ASPO还结合了一种软双裁剪机制,以稳定极端更新,同时保持梯度流动。在编码和数学推理基准上的综合实验表明,ASPO显著缓解了过早收敛,提高了训练稳定性,并增强了最终性能,优于强大的基于GRPO的基线。作者的分析为token级别权重在OSRL中的作用提供了新的见解,并强调了纠正LLM RL中IS的关键重要性。
🔬 方法详解
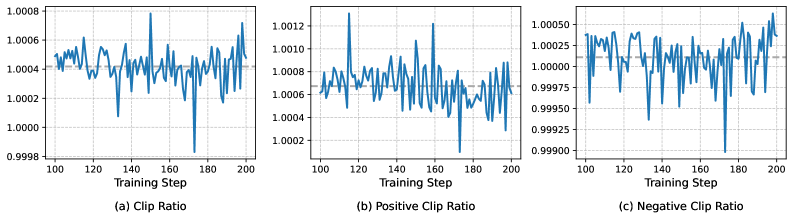
问题定义:现有基于Outcome-Supervised RL (OSRL) 的LLM后训练方法,在token级别进行裁剪,但正向优势token的重要性采样(IS)比率存在不匹配。这种不匹配导致正向和负向token的权重更新不平衡,抑制了低概率token的学习,同时过度放大了高概率token,最终导致过早收敛和性能下降。
核心思路:ASPO的核心思路是纠正正向优势token的IS比率。通过翻转这些token的IS比率,使其更新方向与负向token的学习动态对齐,从而平衡正向和负向token的权重,促进更有效的学习。这种非对称处理旨在解决现有方法中存在的偏差,并鼓励模型探索更多样化的token序列。
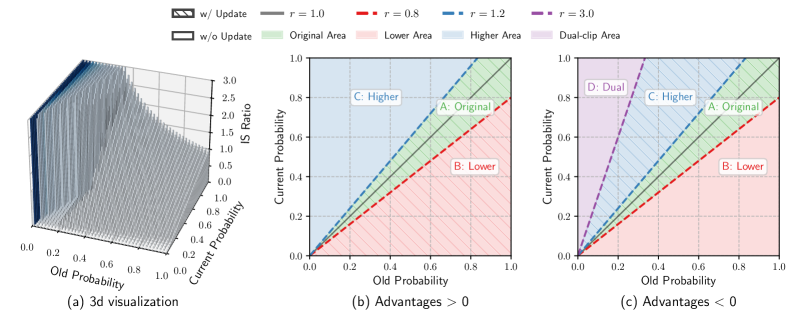
技术框架:ASPO的整体框架仍然基于现有的OSRL流程,但在策略更新阶段引入了非对称重要性采样。具体来说,对于每个token,首先计算其优势函数。然后,根据优势函数的符号,决定是否翻转其IS比率。对于正向优势token,IS比率被翻转;对于负向优势token,IS比率保持不变。此外,ASPO还包含一个软双裁剪机制,用于稳定训练过程,防止极端更新。
关键创新:ASPO最关键的创新在于其非对称重要性采样策略。与现有方法对称地处理所有token不同,ASPO根据token的优势函数,有选择性地调整其IS比率。这种非对称处理能够更有效地平衡正向和负向token的权重,从而提高学习效率和性能。此外,软双裁剪机制也增强了训练的稳定性。
关键设计:ASPO的关键设计包括:1) 优势函数的计算方式(通常使用GAE等方法);2) IS比率的翻转策略(直接取倒数);3) 软双裁剪机制的参数设置(裁剪阈值等)。软双裁剪机制通过引入两个裁剪阈值,分别限制IS比率的上限和下限,从而防止极端更新。裁剪是“软”的,意味着梯度仍然可以流过裁剪操作,避免梯度消失问题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ASPO在代码生成和数学推理任务上显著优于基于GRPO的基线方法。例如,在某些基准测试中,ASPO的性能提升超过10%。此外,ASPO还表现出更强的训练稳定性,能够更快地收敛到更好的性能水平。这些结果验证了ASPO在纠正IS偏差和提高LLM强化学习性能方面的有效性。
🎯 应用场景
ASPO可应用于各种需要利用强化学习进行LLM后训练的场景,例如代码生成、数学推理、对话系统等。通过提高训练稳定性和最终性能,ASPO能够帮助LLM更好地完成特定任务,提升用户体验,并降低训练成本。该方法在教育、金融、客服等领域具有广泛的应用潜力。
📄 摘要(原文)
Recent Large Language Model (LLM) post-training methods rely on token-level clipping mechanisms during Reinforcement Learning (RL). However, we identify a fundamental flaw in this Outcome-Supervised RL (OSRL) paradigm: the Importance Sampling (IS) ratios of positive-advantage tokens are mismatched, leading to unbalanced token weighting for positive and negative tokens. This mismatch suppresses the update of low-probability tokens while over-amplifying already high-probability ones. To address this, we propose Asymmetric Importance Sampling Policy Optimization (ASPO), which uses a simple yet effective strategy that flips the IS ratios of positive-advantage tokens, aligning their update direction with the learning dynamics of negative ones. AIS further incorporates a soft dual-clipping mechanism to stabilize extreme updates while maintaining gradient flow. Comprehensive experiments on coding and mathematical reasoning benchmarks demonstrate that ASPO significantly mitigates premature convergence, improves training stability, and enhances final performance over strong GRPO-based baselines. Our analysis provides new insights into the role of token-level weighting in OSRL and highlights the critical importance of correcting IS in LLM RL. The code and models of ASPO are available at https://github.com/wizard-III/Archer2.0.