MASA: Rethinking the Representational Bottleneck in LoRA with Multi-A Shared Adaptation
作者: Qin Dong, Yuntian Tang, Heming Jia, Yunhang Shen, Bohan Jia, Wenxuan Huang, Lianyue Zhang, Jiao Xie, Shaohui Lin
分类: cs.CL
发布日期: 2025-10-07
备注: 14 pages, 5 figures
💡 一句话要点
MASA:通过多A共享适配重塑LoRA中的表征瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适配 表征瓶颈 多专家集成 大型语言模型
📋 核心要点
- LoRA依赖单一的下投影矩阵A,导致表征能力不足,难以捕捉复杂任务的多样化特征。
- MASA采用多A单B结构,通过多个A矩阵专家集成提取多样特征,再由B矩阵进行整合。
- 实验表明,MASA在多领域泛化、单领域专业化和多任务推理方面均优于LoRA。
📝 摘要(中文)
低秩适配(LoRA)已成为大型语言模型参数高效微调(PEFT)中的主导方法,它通过一个下投影矩阵$A$和一个上投影矩阵$B$来增强Transformer层。然而,LoRA对单个下投影矩阵($A$)的依赖造成了表征瓶颈,因为这个单独的特征提取器本质上不足以捕获复杂任务所需的多样化信号。这促使我们进行架构上的转变,专注于丰富特征适配以提高下游任务的适配能力。我们提出了MASA(多-$A$共享适配),该架构实现了一种多-$A$,单-$B$结构,其中多-$A$专家集成在各层之间非对称共享,以确保参数效率。在MASA中,这些专门的专家捕获不同的特征,然后由一个单一的、特定于层的$B$矩阵集成。通过涵盖多领域泛化、单领域专业化和多任务推理的全面实验,验证了我们方法的有效性和通用性。例如,在MMLU基准测试中,MASA实现了59.62%的平均准确率,优于标准LoRA 1.08个百分点(相对改进1.84%),且具有相当的可学习参数0.52%。
🔬 方法详解
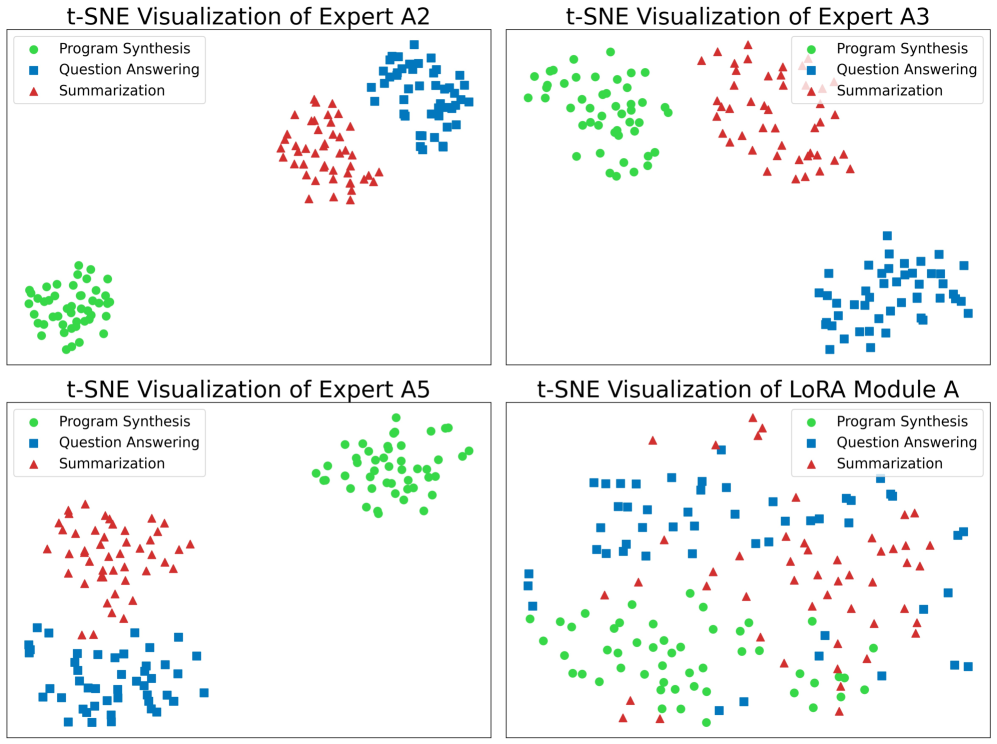
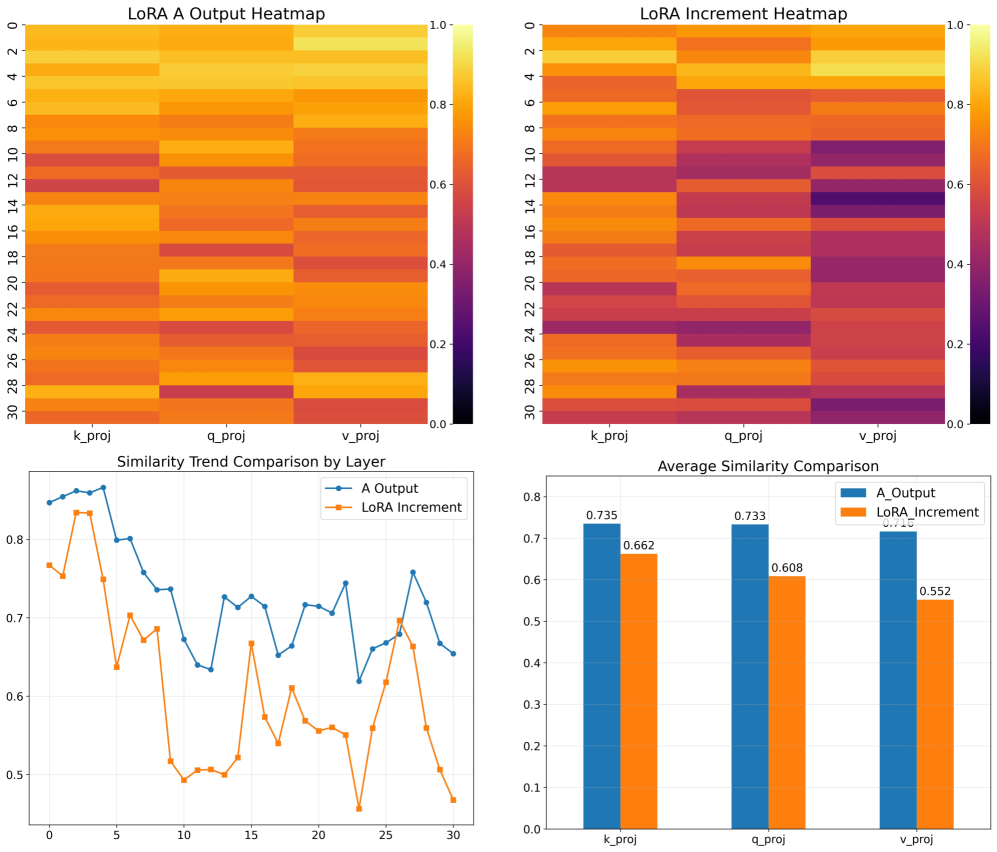
问题定义:LoRA虽然参数效率高,但其核心的下投影矩阵A成为了表征瓶颈。单个A矩阵难以捕捉复杂任务所需的各种特征,限制了模型的性能。因此,论文旨在解决LoRA中表征能力不足的问题,提升模型在下游任务上的适配能力。
核心思路:论文的核心思路是通过引入多个A矩阵(多专家)来增强特征提取能力。每个A矩阵专注于提取不同的特征,形成一个专家集成。这些专家提取的特征随后被一个共享的B矩阵整合,从而在提升表征能力的同时,保持参数效率。
技术框架:MASA的核心架构是多A单B结构。具体来说,对于Transformer的每一层,不再使用单个A矩阵,而是使用多个A矩阵(专家)。这些A矩阵并行地提取特征,然后通过一个共享的B矩阵将这些特征整合起来。为了进一步提高参数效率,这些A矩阵专家在不同的层之间进行非对称共享。
关键创新:MASA最重要的创新点在于其多A单B的结构,以及A矩阵专家在层间的非对称共享机制。这种结构有效地增强了模型的表征能力,使其能够捕捉到更丰富、更细粒度的特征。同时,非对称共享机制保证了参数效率,避免了模型规模的过度增长。
关键设计:MASA的关键设计包括A矩阵专家的数量、A矩阵在层间的共享策略以及B矩阵的初始化方式。论文中可能探讨了不同数量的A矩阵专家对性能的影响,以及不同的共享策略如何影响模型的泛化能力。B矩阵的初始化方式也可能对模型的收敛速度和最终性能产生影响。具体的参数设置和损失函数等细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
MASA在MMLU基准测试中取得了显著的性能提升,平均准确率达到59.62%,相比标准LoRA提高了1.08个百分点(相对提升1.84%),并且参数量相当(0.52%)。这一结果表明,MASA在提升模型性能的同时,保持了参数效率,验证了其有效性。
🎯 应用场景
MASA具有广泛的应用前景,可用于各种大型语言模型的参数高效微调。例如,可以将其应用于自然语言处理的各个领域,如文本分类、机器翻译、文本生成等。此外,MASA还可以用于迁移学习,将预训练模型快速适应到新的任务和领域。该研究的实际价值在于提升了模型的性能,同时保持了参数效率,降低了计算成本。未来,MASA有望成为一种通用的PEFT方法,推动大型语言模型在更多领域的应用。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) has emerged as a dominant method in Parameter-Efficient Fine-Tuning (PEFT) for large language models, which augments the transformer layer with one down-projection $A$ and one up-projection $B$. However, LoRA's reliance on a single down-projection matrix ($A$) creates a representational bottleneck, as this solitary feature extractor is inherently insufficient for capturing the diverse signals required by complex tasks. This motivates our architectural shift to focus on enriching the feature adaptation to improve the downstream task adaptation ability. We propose MASA (Multi-$A$ Shared Adaptation), an architecture that implements a multi-$A$, single-$B$ structure where the multi-$A$ expert ensemble is asymmetrically shared across layers to ensure parameter efficiency. In MASA, these specialized experts capture diverse features, which are then integrated by a single, layer-specific $B$-matrix. The effectiveness and versatility of our method are validated through a comprehensive suite of experiments spanning multi-domain generalization, single-domain specialization, and multi-task reasoning. For example, on the MMLU benchmark, MASA achieves an average accuracy of 59.62%, outperforming the standard LoRA by 1.08 points (a relative improvement of 1.84%) with comparable learnable parameters of 0.52%.