Exploring Gaps in the APS: Direct Minimal Pair Analysis in LLM Syntactic Assessments
作者: Timothy Pistotti, Jason Brown, Michael Witbrock
分类: cs.CL
发布日期: 2025-10-07
备注: Presented at the https://brigap-workshop.github.io/ Information to be updated after publication of proceedings
💡 一句话要点
通过直接最小对分析揭示LLM句法评估中的差距,提升评估透明度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 句法评估 最小对分析 寄生缺口 填充-缺口依赖 wh-效应 GPT-2 自然语言理解
📋 核心要点
- 现有基于惊讶度的LLM句法能力评估方法结论不一致,缺乏诊断透明度。
- 采用直接最小对分析,通过系统性的wh-效应分析,提升评估的诊断透明度。
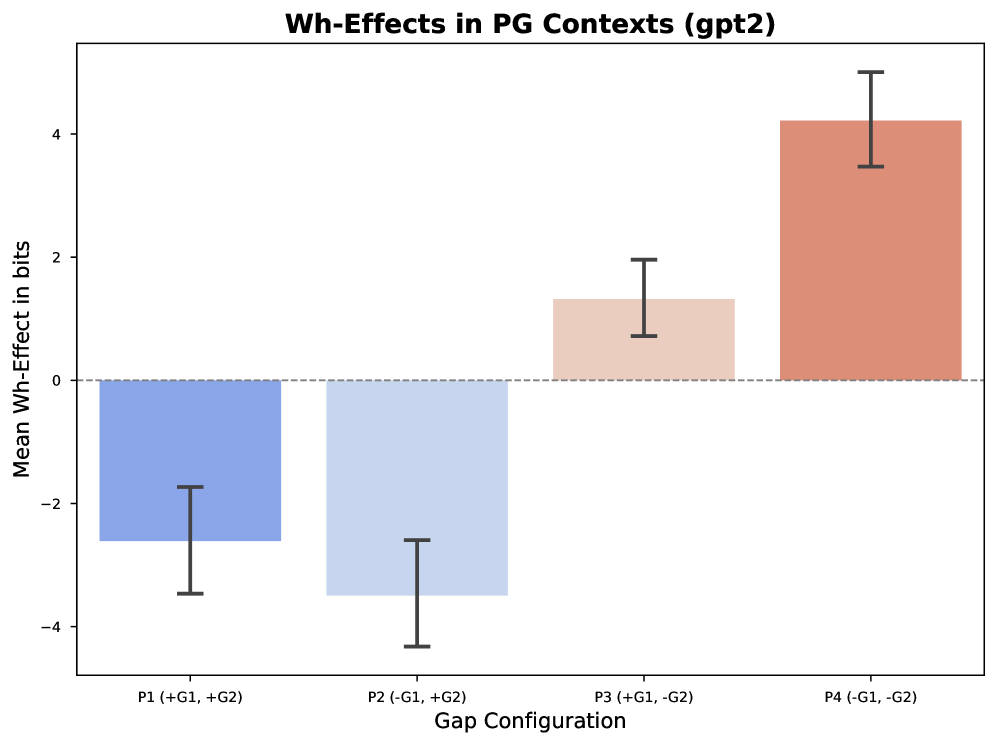
- 实验表明,GPT-2在寄生缺口环境中表现出色,证明了其对填充-缺口许可原则的理解。
📝 摘要(中文)
最近的研究利用“刺激贫乏论证”(APS)来探索大型语言模型(LLM)学习复杂句法的能力,主要通过基于惊讶度的指标。然而,不同的结论引发了对这些指标所提供信息的质疑。Wilcox等人(2024)使用直接最小对比较(“wh-效应”)证明模型成功地泛化了填充-缺口依赖关系知识,而Lan等人(2024)使用差异中的差异(DiD)指标发现模型在寄生缺口(PGs)上表现不佳。本文认为,直接最小对方法提供了更高的诊断透明度。我们通过生成一个完整的8排列范式的精细PG刺激,并使用系统的Wilcox风格的wh-效应分析评估先前研究中使用的GPT-2模型来证明这一点。我们的结果表明,GPT-2在所有四个测试条件下都取得了成功,表明即使在复杂的PG环境中,也具有对填充-缺口许可原则的强大知识。这一发现与DiD风格指标中较为模糊的结果形成对比,表明评估指标的选择对于评估LLM的句法能力至关重要。
🔬 方法详解
问题定义:现有研究在评估大型语言模型(LLM)的句法能力时,使用了基于惊讶度的指标,例如差异中的差异(DiD)。然而,不同研究使用这些指标得出了相互矛盾的结论,这使得我们难以准确判断LLM是否真正掌握了复杂的句法规则。现有方法的痛点在于缺乏诊断透明度,难以确定模型失败的具体原因。
核心思路:本文的核心思路是采用直接最小对分析方法,特别是基于“wh-效应”的分析。这种方法通过比较仅在关键句法结构上存在差异的句子对,直接评估模型对特定句法规则的敏感性。通过系统地操纵刺激,可以更清晰地揭示模型在哪些方面表现良好,哪些方面存在不足。
技术框架:本文的技术框架主要包括以下几个步骤:1)设计精细的寄生缺口(PG)刺激,构建一个完整的8排列范式,涵盖不同的句法变体。2)使用GPT-2模型作为评估对象,该模型也被之前的研究使用。3)采用Wilcox等人提出的wh-效应分析方法,直接比较最小对句子在模型中的惊讶度得分。4)分析实验结果,判断模型是否能够正确处理寄生缺口结构,并推断其对填充-缺口许可原则的理解程度。
关键创新:本文最重要的技术创新点在于强调了直接最小对分析在LLM句法评估中的重要性。与DiD等间接指标相比,直接最小对分析提供了更高的诊断透明度,能够更清晰地揭示模型对特定句法规则的敏感性。通过系统地操纵刺激,可以更准确地评估模型的句法能力,并避免因评估指标选择不当而导致的误判。
关键设计:本文的关键设计包括:1)构建了包含8种排列的寄生缺口刺激,以全面评估模型在不同句法环境下的表现。2)采用了Wilcox风格的wh-效应分析,直接比较最小对句子的惊讶度得分,以量化模型对特定句法规则的敏感性。3)使用了GPT-2模型,并与之前的研究结果进行对比,以验证直接最小对分析的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-2模型在所有四个测试条件下都成功地处理了寄生缺口结构,表明其对填充-缺口许可原则具有强大的知识。这一发现与使用DiD风格指标的研究结果形成鲜明对比,突显了直接最小对分析在评估LLM句法能力方面的优势。该研究强调了评估指标选择的重要性,并为未来LLM句法能力评估提供了更可靠的方法。
🎯 应用场景
该研究成果可应用于更准确地评估和提升大型语言模型的自然语言理解能力,尤其是在复杂句法结构的处理方面。通过更有效的评估方法,可以指导模型训练,使其更好地掌握语言的内在规律,从而在机器翻译、文本生成、对话系统等领域实现更自然、更流畅的交互。
📄 摘要(原文)
Recent studies probing the Argument from the Poverty of the Stimulus (APS) have applied Large Language Models (LLMs) to test the learnability of complex syntax through surprisal-based metrics. However, divergent conclusions raise questions concerning the insights these metrics offer. While Wilcox et al. (2024) used direct minimal pair comparisons (the "wh-effect") to demonstrate that models successfully generalise knowledge of filler-gap dependencies, Lan et al. (2024) used a Difference-in-Differences (DiD) metric and found that models largely fail on parasitic gaps (PGs). This paper argues that the direct minimal pair approach offers greater diagnostic transparency. We demonstrate this by generating a full 8-permutation paradigm of refined PG stimuli and evaluating the GPT-2 model used in previous studies with a systematic Wilcox-style wh-effect analysis. Our results show that GPT-2 succeeds across all four tested conditions, indicating robust knowledge of filler-gap licensing principles even in complex PG environments. This finding, which contrasts with the more ambiguous results from DiD-style metrics, suggests that the choice of evaluation metric is critical for assessing an LLM's syntactic competence.