Probing the Difficulty Perception Mechanism of Large Language Models
作者: Sunbowen Lee, Qingyu Yin, Chak Tou Leong, Jialiang Zhang, Yicheng Gong, Shiwen Ni, Min Yang, Xiaoyu Shen
分类: cs.CL, cs.AI
发布日期: 2025-10-07 (更新: 2025-10-12)
🔗 代码/项目: GITHUB
💡 一句话要点
探究大语言模型难度感知机制,实现自动难度标注。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 难度感知 线性探针 注意力机制 自动标注
📋 核心要点
- 现有方法缺乏对LLM内部评估问题难度的能力的研究,这阻碍了LLM在自适应推理和资源分配方面的应用。
- 通过线性探针和注意力头分析,揭示LLM内部表征中蕴含的问题难度信息,并定位关键的注意力头。
- 实验证明LLM可以有效感知问题难度,并可作为自动难度标注器,降低人工标注成本。
📝 摘要(中文)
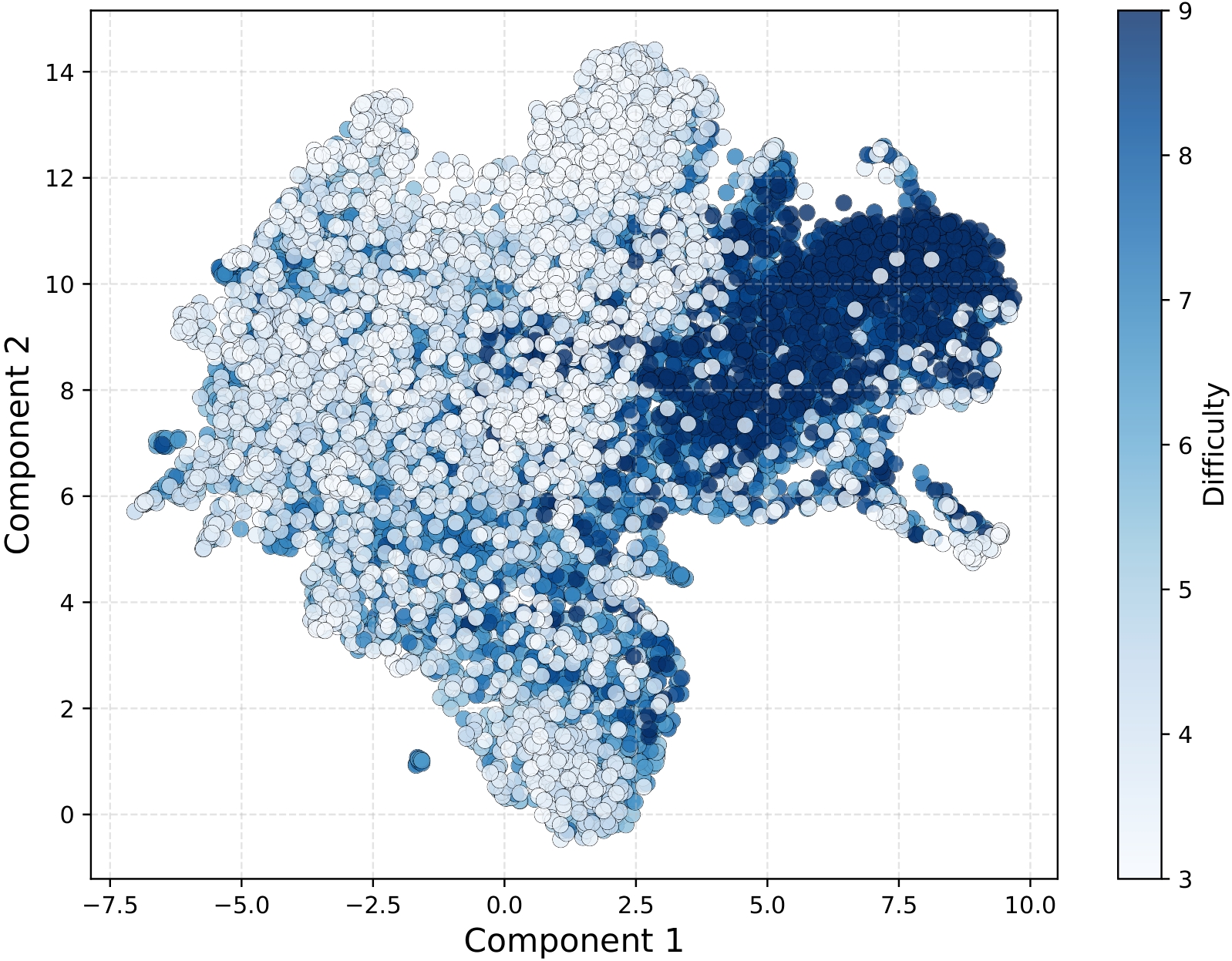
本文研究了大语言模型(LLM)在复杂推理任务中评估问题难度的能力,这是自适应推理和高效资源分配的关键。我们通过线性探针分析LLM最终token的表征,证明数学问题的难度级别可以被线性建模。进一步定位了Transformer最后一层中特定的注意力头,这些注意力头对简单和困难的问题具有相反的激活模式,从而实现难度感知。消融实验验证了定位的准确性。实验结果表明,LLM可以作为自动难度标注器,从而减少基准构建和课程学习中对昂贵的人工标注的依赖。此外,我们还发现token级别的熵和难度感知存在显著差异。这项研究揭示了LLM中的难度感知不仅存在,而且具有结构化的组织,为未来的研究提供了新的理论见解和实践方向。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)是否具备感知问题难度的能力,以及如何利用这种能力的问题。现有方法主要依赖人工标注来评估问题难度,成本高昂且效率低下。此外,缺乏对LLM内部如何表征和处理问题难度的深入理解。
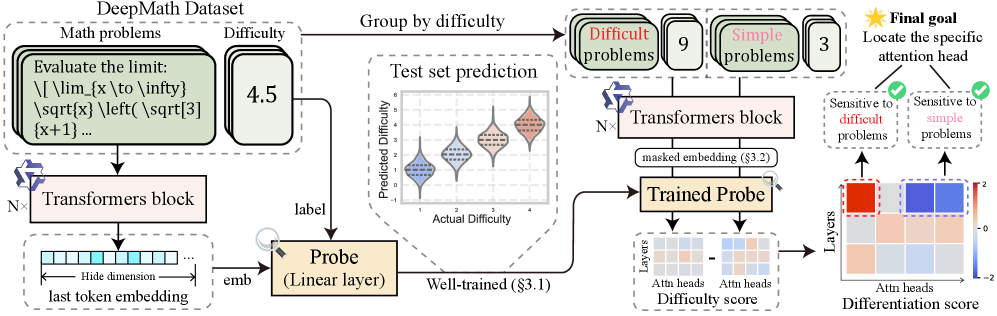
核心思路:论文的核心思路是假设LLM在处理问题时,其内部表征会隐式地编码问题的难度信息。通过分析LLM的内部表征,特别是最终token的表征和注意力头的激活模式,可以揭示LLM如何感知和区分不同难度的问题。这种思路基于LLM强大的表征学习能力,并试图通过可解释性的方法来理解其内部机制。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据准备:收集包含不同难度级别的数学问题数据集。2) LLM推理:使用LLM对问题进行推理,并记录最终token的表征和注意力头的激活值。3) 线性探针:使用线性模型对最终token的表征进行训练,以预测问题的难度级别。4) 注意力头分析:分析Transformer最后一层中不同注意力头的激活模式,寻找对问题难度敏感的注意力头。5) 消融实验:通过移除或修改特定的注意力头,验证其对难度感知的重要性。
关键创新:论文的关键创新在于揭示了LLM内部存在结构化的难度感知机制。具体来说,通过线性探针和注意力头分析,证明了LLM可以有效地感知问题难度,并且这种难度感知与特定的注意力头相关联。此外,论文还提出了利用LLM作为自动难度标注器的想法,这可以显著降低人工标注的成本。
关键设计:论文的关键设计包括:1) 使用线性探针来分析LLM的内部表征,这是一种简单而有效的方法,可以揭示LLM是否编码了特定的信息。2) 关注Transformer最后一层的注意力头,因为这些注意力头通常负责高级的推理和决策。3) 设计消融实验来验证特定注意力头对难度感知的重要性。4) 探索token级别的熵和难度感知之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM的最终token表征可以通过线性模型有效地预测问题难度。特定的注意力头对简单和困难的问题具有相反的激活模式,表明这些注意力头在难度感知中起着关键作用。消融实验验证了这些注意力头的重要性。实验还发现token级别的熵与难度感知之间存在显著差异。
🎯 应用场景
该研究成果可应用于自动课程学习、自适应测试、教育资源推荐等领域。通过利用LLM自动评估问题难度,可以构建更有效的学习路径,为学生提供个性化的学习体验。此外,该研究还可以用于改进LLM的推理能力,使其能够更好地处理复杂问题。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed on complex reasoning tasks, yet little is known about their ability to internally evaluate problem difficulty, which is an essential capability for adaptive reasoning and efficient resource allocation. In this work, we investigate whether LLMs implicitly encode problem difficulty in their internal representations. Using a linear probe on the final-token representations of LLMs, we demonstrate that the difficulty level of math problems can be linearly modeled. We further locate the specific attention heads of the final Transformer layer: these attention heads have opposite activation patterns for simple and difficult problems, thus achieving perception of difficulty. Our ablation experiments prove the accuracy of the location. Crucially, our experiments provide practical support for using LLMs as automatic difficulty annotators, potentially substantially reducing reliance on costly human labeling in benchmark construction and curriculum learning. We also uncover that there is a significant difference in entropy and difficulty perception at the token level. Our study reveals that difficulty perception in LLMs is not only present but also structurally organized, offering new theoretical insights and practical directions for future research. Our code is available at https://github.com/Aegis1863/Difficulty-Perception-of-LLMs.