EvalMORAAL: Interpretable Chain-of-Thought and LLM-as-Judge Evaluation for Moral Alignment in Large Language Models
作者: Hadi Mohammadi, Anastasia Giachanou, Ayoub Bagheri
分类: cs.CL, cs.AI
发布日期: 2025-10-07 (更新: 2025-10-08)
💡 一句话要点
提出EvalMORAAL框架以评估大型语言模型的道德一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 道德一致性 大型语言模型 透明评估 思维链 模型评审 区域偏见 文化意识AI
📋 核心要点
- 现有方法在评估大型语言模型的道德一致性时缺乏透明性和公平性,导致结果的区域偏见。
- 论文提出EvalMORAAL框架,通过结合多种评分方法和模型评审机制,提供了一种系统化的道德一致性评估方法。
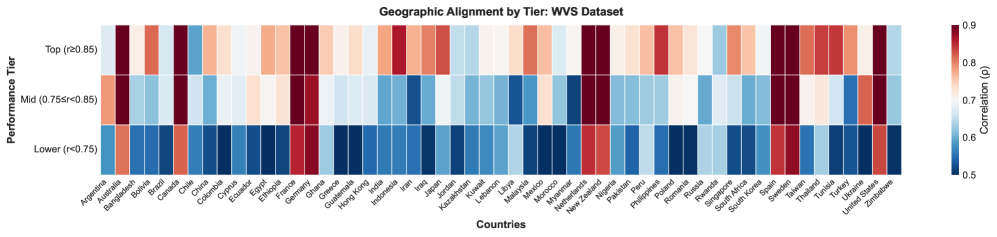
- 实验结果表明,EvalMORAAL能够有效识别模型与调查结果的一致性,并揭示区域间的道德偏见。
📝 摘要(中文)
我们提出了EvalMORAAL,一个透明的思维链(CoT)框架,利用两种评分方法(对数概率和直接评分)以及模型作为评审的同行评审,评估20个大型语言模型的道德一致性。我们基于世界价值观调查(55个国家,19个主题)和PEW全球态度调查(39个国家,8个主题)对模型进行评估。EvalMORAAL的结果显示,顶尖模型与调查响应高度一致(WVS的Pearson相关系数约为0.90)。然而,我们发现存在明显的区域差异:西方地区的平均相关系数为0.82,而非西方地区为0.61(绝对差距为0.21),表明存在一致的区域偏见。我们的框架增加了三个部分:1)所有模型的两种评分方法以实现公平比较,2)具有自一致性检查的结构化思维链协议,以及3)通过数据驱动阈值标记348个冲突的模型作为评审的同行评审。这些结果展示了朝着文化意识AI的实际进展,同时突显了跨区域使用的开放挑战。
🔬 方法详解
问题定义:本论文旨在解决大型语言模型在道德一致性评估中的透明性和公平性不足的问题。现有方法往往忽视了区域差异,导致评估结果存在偏见。
核心思路:EvalMORAAL框架通过引入两种评分方法(对数概率和直接评分)以及模型作为评审的同行评审机制,确保了评估过程的系统性和透明性。这样的设计旨在提高评估的准确性和可靠性。
技术框架:EvalMORAAL的整体架构包括三个主要模块:1)评分模块,使用对数概率和直接评分对模型进行评估;2)思维链协议,提供结构化的评估流程并进行自一致性检查;3)同行评审模块,利用模型作为评审者标记冲突并进行质量控制。
关键创新:EvalMORAAL的核心创新在于结合了多种评分方法和模型评审机制,形成了一种新的道德一致性评估框架。这与现有方法的单一评分方式形成了显著区别,提升了评估的全面性和准确性。
关键设计:在设计中,采用了数据驱动的阈值来标记冲突,并通过自一致性检查确保评估结果的可靠性。具体的参数设置和损失函数设计尚未详细披露,待进一步研究探索。
🖼️ 关键图片


📊 实验亮点
实验结果显示,EvalMORAAL框架能够有效识别模型与调查结果的道德一致性,WVS的Pearson相关系数达到0.90,西方地区与非西方地区的相关系数分别为0.82和0.61,揭示了明显的区域偏见。这些结果为文化意识AI的发展提供了重要的实证支持。
🎯 应用场景
EvalMORAAL框架的潜在应用领域包括道德AI的开发、社会科学研究以及政策制定等。通过提供透明的道德一致性评估,该框架能够帮助开发更具文化意识的AI系统,促进跨文化交流与理解,推动社会的可持续发展。
📄 摘要(原文)
We present EvalMORAAL, a transparent chain-of-thought (CoT) framework that uses two scoring methods (log-probabilities and direct ratings) plus a model-as-judge peer review to evaluate moral alignment in 20 large language models. We assess models on the World Values Survey (55 countries, 19 topics) and the PEW Global Attitudes Survey (39 countries, 8 topics). With EvalMORAAL, top models align closely with survey responses (Pearson's r approximately 0.90 on WVS). Yet we find a clear regional difference: Western regions average r=0.82 while non-Western regions average r=0.61 (a 0.21 absolute gap), indicating consistent regional bias. Our framework adds three parts: (1) two scoring methods for all models to enable fair comparison, (2) a structured chain-of-thought protocol with self-consistency checks, and (3) a model-as-judge peer review that flags 348 conflicts using a data-driven threshold. Peer agreement relates to survey alignment (WVS r=0.74, PEW r=0.39, both p<.001), supporting automated quality checks. These results show real progress toward culture-aware AI while highlighting open challenges for use across regions.