Hire Your Anthropologist! Rethinking Culture Benchmarks Through an Anthropological Lens
作者: Mai AlKhamissi, Yunze Xiao, Badr AlKhamissi, Mona Diab
分类: cs.CL, cs.CY
发布日期: 2025-10-07 (更新: 2025-10-22)
备注: 12 pages; 2 figures; First two author contributed equally
💡 一句话要点
通过人类学视角重塑文化基准评测,提升大语言模型文化理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文化评估 大语言模型 人类学 基准测试 文化多样性
📋 核心要点
- 现有文化基准测试将文化简化为静态事实,忽略了文化的动态性和情境性,无法准确评估LLM的文化理解。
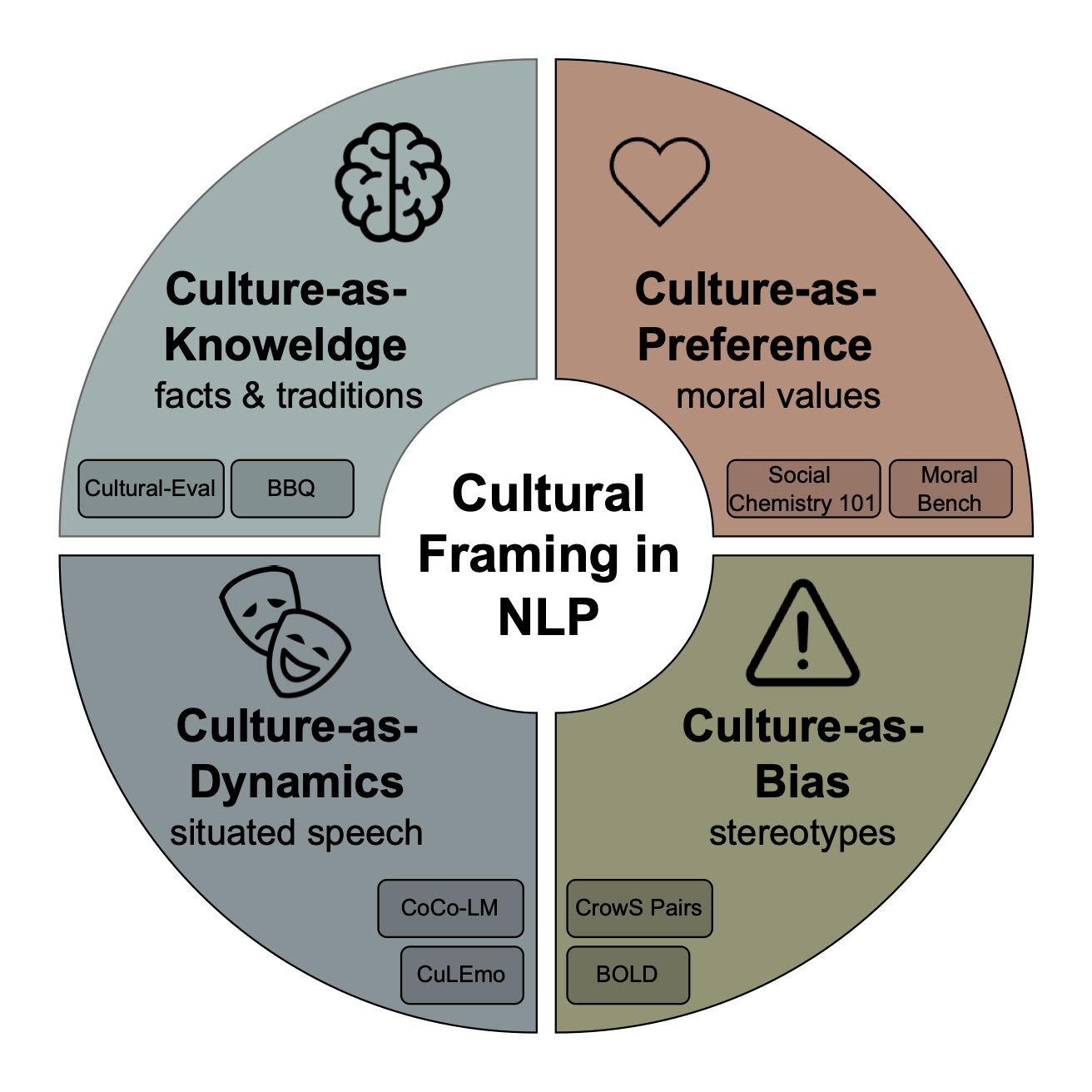
- 论文提出四部分框架,用于分析现有基准测试如何构建文化,并借鉴人类学方法提出改进措施。
- 通过定性分析20个文化基准,识别出六个常见的方法论问题,并提出了具体的改进建议。
📝 摘要(中文)
对大型语言模型进行文化评估变得越来越重要,但当前的基准测试通常将文化简化为静态事实或同质价值观。这种观点与人类学的观点相悖,后者强调文化是动态的、具有历史情境的,并在实践中体现。为了分析这一差距,我们提出了一个四部分框架,对基准测试如何构建文化进行分类,例如知识、偏好、表现或偏见。通过这个视角,我们定性地考察了20个文化基准,并确定了六个反复出现的方法论问题,包括将国家视为文化、忽视文化内部的多样性,以及依赖过于简化的调查形式。借鉴已建立的人类学方法,我们提出了具体的改进措施:纳入真实世界的叙事和情景,让文化社区参与设计和验证,以及在情境中而不是孤立地评估模型。我们的目标是指导文化基准的开发,使其超越静态回忆任务,更准确地捕捉模型对复杂文化情境的反应。
🔬 方法详解
问题定义:现有的大语言模型文化评估基准存在将文化简化为静态知识、忽略文化内部多样性、以及评估方法过于简单化等问题。这些问题导致模型无法真正理解和适应不同文化的复杂性,从而影响其在实际应用中的表现。现有方法缺乏对文化动态性和情境性的考虑,无法有效评估模型在真实文化场景中的表现。
核心思路:论文的核心思路是从人类学的视角重新审视文化评估基准。通过借鉴人类学的方法论,例如民族志研究、参与式观察等,来更全面、深入地理解文化的复杂性和多样性。论文强调文化是动态的、情境化的,需要在具体的社会实践中进行评估。
技术框架:论文提出了一个四部分框架,用于分析现有文化基准测试如何构建文化:1) 文化知识:基准测试关注哪些文化事实?2) 文化偏好:基准测试如何衡量文化价值观?3) 文化表现:基准测试如何评估模型在文化任务中的表现?4) 文化偏见:基准测试如何检测文化偏见?基于此框架,论文对20个文化基准进行了定性分析,识别出常见的方法论问题。
关键创新:论文的关键创新在于将人类学的方法论引入到大语言模型的文化评估中。与传统的基于静态知识的评估方法不同,论文强调文化是动态的、情境化的,需要在具体的社会实践中进行评估。此外,论文还提出了具体的改进措施,例如纳入真实世界的叙事和情景,让文化社区参与设计和验证等。
关键设计:论文的关键设计包括:1) 四部分框架:用于分析现有基准测试如何构建文化。2) 定性分析方法:对20个文化基准进行深入分析,识别出常见的方法论问题。3) 改进措施:提出具体的改进建议,例如纳入真实世界的叙事和情景,让文化社区参与设计和验证等。这些设计旨在提升文化评估基准的有效性和可靠性。
🖼️ 关键图片

📊 实验亮点
论文通过定性分析20个文化基准,揭示了现有方法在文化评估方面的局限性,例如将国家等同于文化、忽视文化内部多样性等。研究强调了文化评估中情境化和动态性的重要性,并提出了具体的改进建议,为未来文化基准的开发提供了指导。
🎯 应用场景
该研究成果可应用于提升大语言模型在跨文化交流、内容生成、智能客服等领域的表现。通过更准确地理解和适应不同文化,模型可以更好地服务于全球用户,避免文化误解和冒犯,并促进跨文化交流与合作。未来,该研究可推动开发更智能、更负责任的AI系统。
📄 摘要(原文)
Cultural evaluation of large language models has become increasingly important, yet current benchmarks often reduce culture to static facts or homogeneous values. This view conflicts with anthropological accounts that emphasize culture as dynamic, historically situated, and enacted in practice. To analyze this gap, we introduce a four-part framework that categorizes how benchmarks frame culture, such as knowledge, preference, performance, or bias. Using this lens, we qualitatively examine 20 cultural benchmarks and identify six recurring methodological issues, including treating countries as cultures, overlooking within-culture diversity, and relying on oversimplified survey formats. Drawing on established anthropological methods, we propose concrete improvements: incorporating real-world narratives and scenarios, involving cultural communities in design and validation, and evaluating models in context rather than isolation. Our aim is to guide the development of cultural benchmarks that go beyond static recall tasks and more accurately capture the responses of the models to complex cultural situations.