Prompt reinforcing for long-term planning of large language models
作者: Hsien-Chin Lin, Benjamin Matthias Ruppik, Carel van Niekerk, Chia-Hao Shen, Michael Heck, Nurul Lubis, Renato Vukovic, Shutong Feng, Milica Gašić
分类: cs.CL, cs.LG
发布日期: 2025-10-07
💡 一句话要点
提出基于强化学习的Prompt优化框架,提升LLM在长期规划任务中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Prompt工程 强化学习 长期规划 多轮交互 文本到SQL 对话系统
📋 核心要点
- 现有LLM在多轮交互任务中表现欠佳,难以跟踪用户目标和进行长期规划。
- 论文提出一种受强化学习启发的prompt优化框架,通过修改任务指令prompt来实现长期规划。
- 实验表明,该方法在文本到SQL和面向任务的对话等任务中取得了显著改进,并具有良好的泛化性。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理任务中取得了显著成功,并且可以通过prompt进行调整。然而,它们在多轮交互中仍然表现不佳,通常依赖于不正确的早期假设,并且无法随时间跟踪用户目标,这使得此类任务特别具有挑战性。对话系统中的先前工作表明,长期规划对于处理交互式任务至关重要。在这项工作中,我们提出了一种受强化学习启发的prompt优化框架,该框架仅通过修改基于LLM的代理的任务指令prompt来实现这种规划。通过生成逐轮反馈并利用经验回放进行prompt重写,我们提出的方法在文本到SQL和面向任务的对话等多轮任务中显示出显着改进。此外,它可以推广到不同的基于LLM的代理,并且可以利用不同的LLM作为元prompt代理。这保证了未来在受强化学习启发的无参数优化方法方面的研究。
🔬 方法详解
问题定义:现有的大型语言模型在处理需要长期规划的多轮交互任务时,存在着无法有效跟踪用户目标、容易受到早期错误假设影响等问题。这导致LLM在对话系统、文本到SQL等任务中的性能受到限制。现有方法缺乏有效的机制来引导LLM进行长期规划,从而难以应对复杂的多轮交互场景。
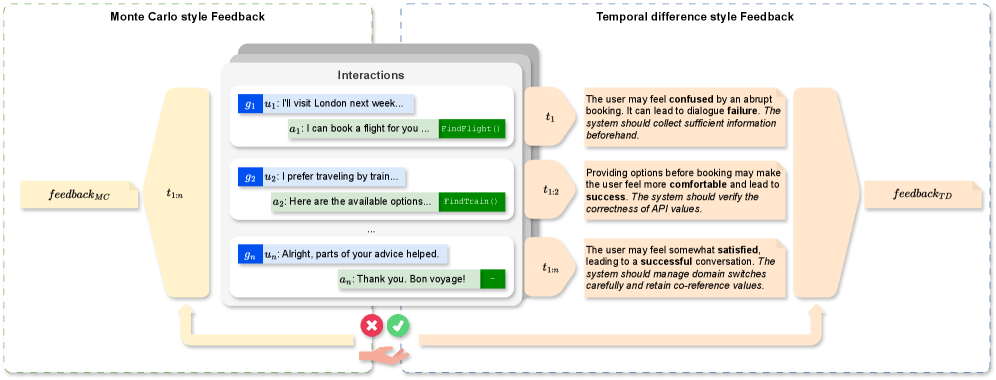
核心思路:论文的核心思路是借鉴强化学习的思想,将prompt优化问题建模为一个强化学习问题。通过生成逐轮反馈(reward)来指导LLM更好地完成任务,并利用经验回放机制来提高prompt优化的效率和稳定性。这种方法的核心在于,通过优化prompt,使得LLM能够更好地理解任务目标,并进行有效的长期规划。
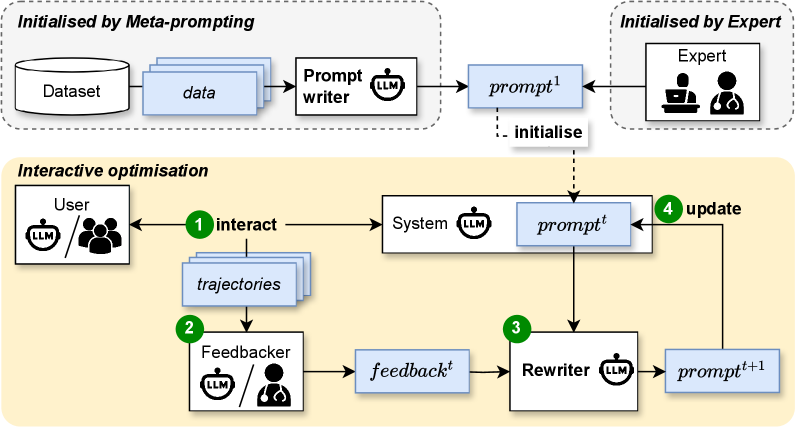
技术框架:整体框架包含以下几个主要模块:1) LLM-based Agent:作为与环境交互的主体,接收prompt并生成回复。2) Environment:模拟真实的任务环境,例如SQL数据库或对话场景。3) Feedback Generator:根据Agent的回复和环境状态,生成反馈信号(reward)。4) Prompt Rewriter:利用经验回放机制,根据历史交互数据和反馈信号,对prompt进行迭代优化。整个流程是一个循环迭代的过程,通过不断优化prompt,提高Agent在任务中的表现。
关键创新:该论文最重要的创新点在于将强化学习的思想引入到prompt优化中,提出了一种无需修改LLM参数的prompt优化方法。与传统的prompt工程方法相比,该方法能够自动地学习到更有效的prompt,从而提高LLM在长期规划任务中的性能。此外,该方法还具有良好的泛化性,可以应用于不同的LLM和任务。
关键设计:论文的关键设计包括:1) Feedback Generator的设计:如何设计有效的反馈信号来指导LLM进行长期规划是一个关键问题。论文中可能采用了基于规则、基于模型或基于人工标注等多种方式来生成反馈信号。2) Prompt Rewriter的设计:如何利用经验回放机制来提高prompt优化的效率和稳定性是一个关键问题。论文中可能采用了不同的prompt重写策略,例如基于梯度下降、基于进化算法或基于规则等。
🖼️ 关键图片
📊 实验亮点
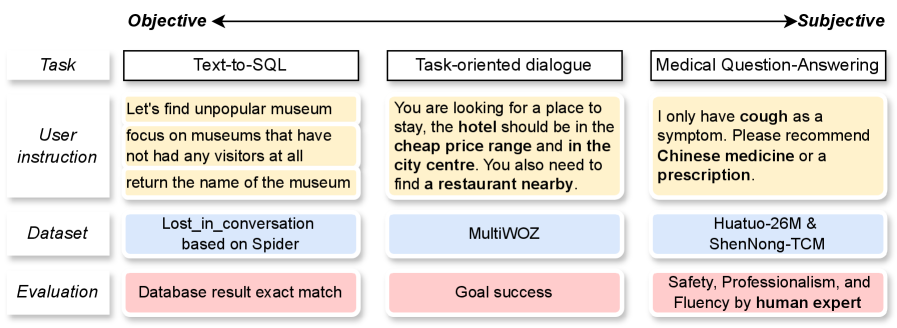
实验结果表明,该方法在文本到SQL和面向任务的对话等任务中取得了显著的性能提升。具体而言,与基线方法相比,该方法在任务完成率、对话轮数等方面均有明显改善。此外,实验还验证了该方法具有良好的泛化性,可以应用于不同的LLM和任务。
🎯 应用场景
该研究成果可广泛应用于对话系统、智能助手、文本到SQL等需要长期规划和多轮交互的场景。通过优化LLM的prompt,可以显著提升这些应用的用户体验和性能。未来,该方法还可以扩展到其他领域,例如机器人控制、游戏AI等,为实现更智能、更自主的AI系统提供新的思路。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable success in a wide range of natural language processing tasks and can be adapted through prompting. However, they remain suboptimal in multi-turn interactions, often relying on incorrect early assumptions and failing to track user goals over time, which makes such tasks particularly challenging. Prior works in dialogue systems have shown that long-term planning is essential for handling interactive tasks. In this work, we propose a prompt optimisation framework inspired by reinforcement learning, which enables such planning to take place by only modifying the task instruction prompt of the LLM-based agent. By generating turn-by-turn feedback and leveraging experience replay for prompt rewriting, our proposed method shows significant improvement in multi-turn tasks such as text-to-SQL and task-oriented dialogue. Moreover, it generalises across different LLM-based agents and can leverage diverse LLMs as meta-prompting agents. This warrants future research in reinforcement learning-inspired parameter-free optimisation methods.