DACP: Domain-Adaptive Continual Pre-Training of Large Language Models for Phone Conversation Summarization
作者: Xue-Yong Fu, Elena Khasanova, Md Tahmid Rahman Laskar, Harsh Saini, Shashi Bhushan TN
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-07 (更新: 2025-10-09)
备注: Accepted to the NewSumm Workshop at EMNLP 2025. Equal contribution from the first four authors
💡 一句话要点
提出DACP:领域自适应持续预训练LLM,提升电话对话摘要效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续预训练 领域自适应 大型语言模型 电话对话摘要 自监督学习
📋 核心要点
- 现有LLM在特定领域摘要任务中表现不佳,主要原因是领域差异和缺乏高质量标注数据。
- 论文提出领域自适应持续预训练(DACP)方法,利用大规模无标注数据提升模型性能。
- 实验表明,DACP在领域内和跨领域摘要任务中均有显著提升,并保持了泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在文本摘要方面取得了显著成果,但当应用于与其原始预训练分布不同的特定领域时,性能往往会下降。微调可以提高摘要质量,但通常依赖于昂贵且稀缺的高质量标注数据。本文探索了持续预训练作为一种可扩展的自监督方法,用于调整LLM以适应下游摘要任务,特别是在嘈杂的真实世界对话记录的背景下。我们使用大规模、未标注的商业对话数据进行了广泛的实验,以研究持续预训练是否能增强模型在对话摘要方面的能力。结果表明,持续预训练在领域内和跨领域的摘要基准测试中都产生了显著的收益,同时保持了强大的泛化性和鲁棒性。我们还分析了数据选择策略的影响,为在以摘要为中心的工业应用中应用持续预训练提供了实用的指导。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在电话对话摘要任务中,由于领域差异和缺乏高质量标注数据而导致的性能下降问题。现有方法主要依赖于微调,但微调需要大量标注数据,成本高昂且难以获取。
核心思路:论文的核心思路是利用持续预训练,使LLM能够适应目标领域(电话对话)的特点。通过在大规模无标注的电话对话数据上进行预训练,模型可以学习到该领域的语言模式和知识,从而提高摘要性能。这种自监督的方法避免了对大量标注数据的依赖。
技术框架:DACP的技术框架主要包含以下几个阶段:1) 选择合适的LLM作为基础模型;2) 收集大规模的无标注电话对话数据;3) 设计合适的数据选择策略,从无标注数据中选择有用的样本;4) 使用选择的数据对LLM进行持续预训练;5) 在下游摘要任务上进行微调或直接评估。
关键创新:论文的关键创新在于将持续预训练应用于领域自适应的电话对话摘要任务,并探索了不同的数据选择策略。与传统的微调方法相比,DACP利用无标注数据进行预训练,降低了对标注数据的依赖。此外,论文还分析了数据选择策略对模型性能的影响,为实际应用提供了指导。
关键设计:论文中数据选择策略是一个关键设计。具体的数据选择策略细节未知,但论文强调了其重要性,并分析了不同策略对模型性能的影响。损失函数方面,持续预训练通常采用Masked Language Modeling (MLM) 或因果语言建模 (Causal Language Modeling) 等自监督学习目标。具体的参数设置和网络结构细节未知,但通常会沿用基础LLM的设置,并根据实际情况进行调整。
🖼️ 关键图片


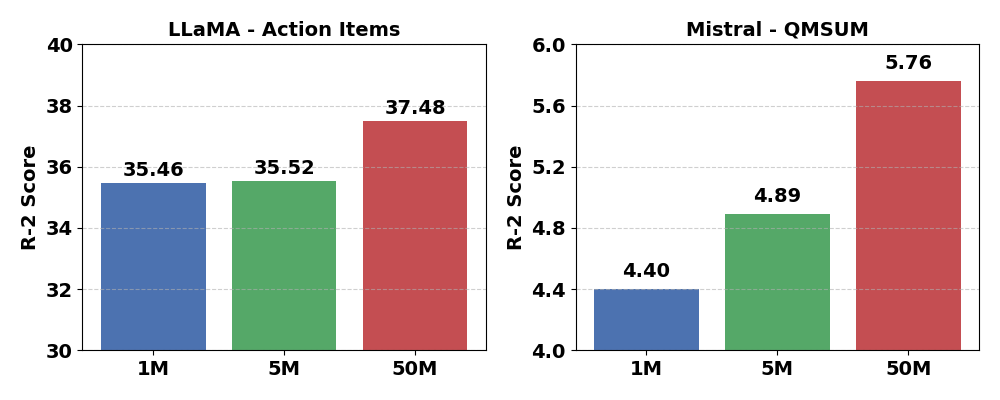
📊 实验亮点
实验结果表明,DACP在电话对话摘要任务中取得了显著的性能提升。具体提升幅度未知,但论文强调了在领域内和跨领域摘要基准测试中均有收益,并保持了良好的泛化性和鲁棒性。此外,论文还分析了数据选择策略对模型性能的影响,为实际应用提供了指导。
🎯 应用场景
该研究成果可应用于客户服务、销售、市场调研等领域,自动生成电话对话摘要,提高信息提取效率,辅助决策。例如,可以自动总结客户投诉内容,帮助客服人员快速了解问题;或者总结销售电话,分析客户需求,提升销售业绩。未来,该技术可进一步扩展到其他类型的对话场景,如会议记录、访谈等。
📄 摘要(原文)
Large language models (LLMs) have achieved impressive performance in text summarization, yet their performance often falls short when applied to specialized domains that differ from their original pre-training distribution. While fine-tuning can improve summarization quality, it typically relies on costly and scarce high-quality labeled data. In this work, we explore continual pre-training as a scalable, self-supervised approach to adapt LLMs for downstream summarization tasks, particularly in the context of noisy real-world conversation transcripts. We conduct extensive experiments using large-scale, unlabeled business conversation data to investigate whether continual pre-training enhances model capabilities in conversational summarization. Our results demonstrate that continual pre-training yields substantial gains in both in-domain and out-of-domain summarization benchmarks, while maintaining strong generalization and robustness. We also analyze the effects of data selection strategies, providing practical guidelines for applying continual pre-training in summarization-focused industrial applications.