Luth: Efficient French Specialization for Small Language Models and Cross-Lingual Transfer
作者: Maxence Lasbordes, Sinoué Gad
分类: cs.CL
发布日期: 2025-10-07
备注: 12 pages, 4 figures and 9 tables
💡 一句话要点
Luth:面向法语的小型语言模型高效特化与跨语言迁移
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法语语言模型 小型语言模型 模型特化 后训练 模型合并 跨语言迁移 自然语言处理
📋 核心要点
- 现有大型语言模型主要以英语为中心,导致法语等其他语言在小型语言模型上的性能存在显著差距。
- Luth通过在高质量法语数据上进行针对性的后训练,实现了法语小型语言模型的高效特化。
- 实验表明,Luth在法语基准测试中超越了同等规模的开源模型,并通过模型合并进一步提升了性能。
📝 摘要(中文)
大型语言模型(LLM)的格局仍然以英语为中心,导致其他主要语言(如法语)的性能差距显著,尤其是在小型语言模型(SLM)的背景下。现有的多语言模型在法语方面的表现明显低于英语,并且针对法语的高效适配方法的研究仍然有限。为了解决这个问题,我们推出了 extbf{Luth},一个法语专业SLM系列:通过对精心策划的高质量法语数据进行有针对性的后训练,我们的模型在多个法语基准测试中优于所有同等规模的开源模型,同时保留了其原始的英语能力。我们进一步表明,战略性模型合并可以提高两种语言的性能,从而使Luth成为法语SLM的新技术水平,并为未来的法语研究奠定坚实的基础。
🔬 方法详解
问题定义:论文旨在解决小型语言模型在法语上的性能不足问题。现有的多语言模型在法语上的表现远不如英语,并且缺乏针对法语的高效适配方法。这限制了法语自然语言处理的发展,也使得小型语言模型难以在法语场景中有效应用。
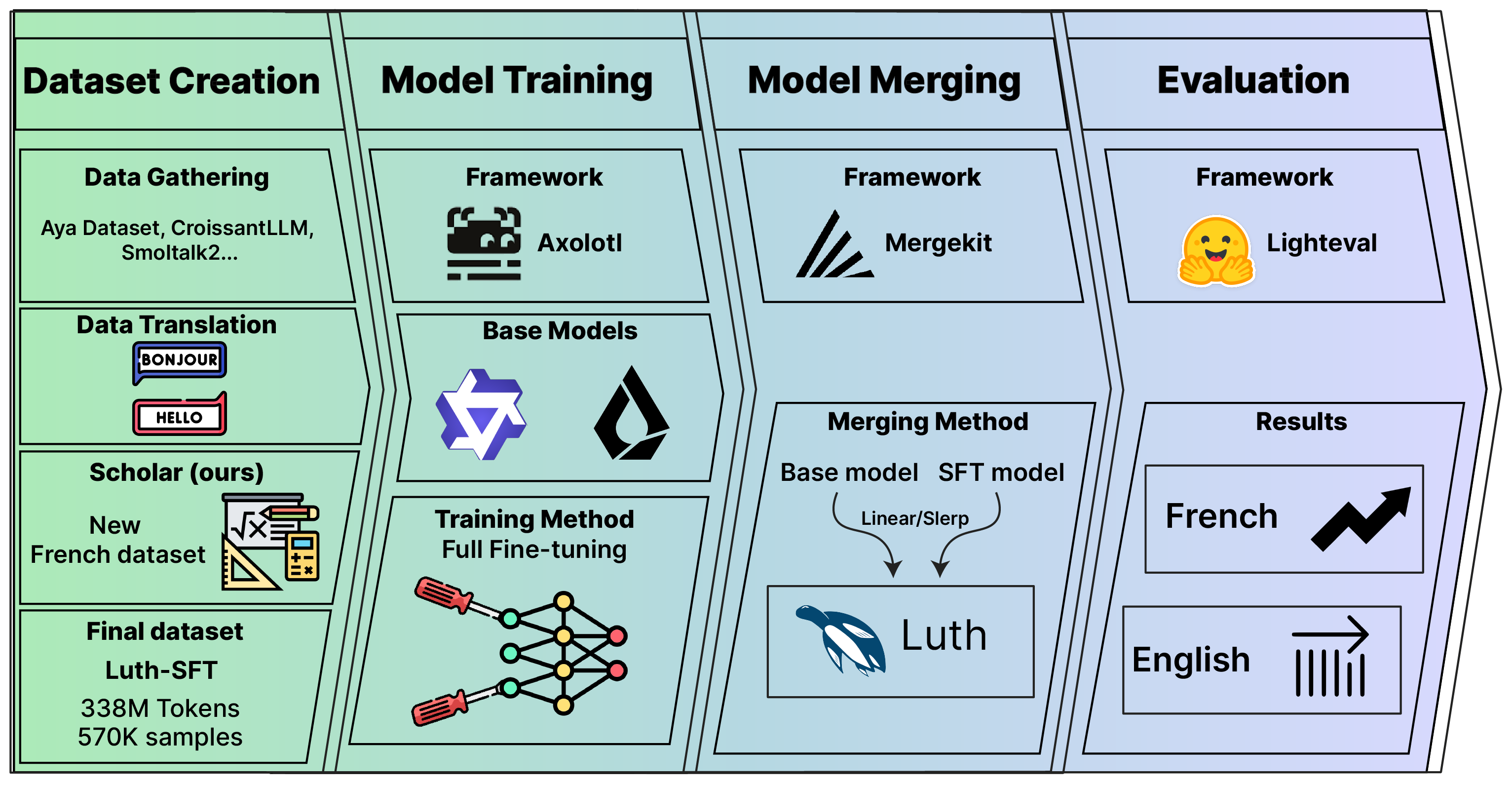
核心思路:论文的核心思路是通过对小型语言模型进行法语数据的针对性后训练,使其更好地适应法语语言的特性。此外,通过模型合并技术,进一步提升模型在法语和英语上的综合性能。这种方法旨在在不显著增加模型大小的情况下,提高法语性能。
技术框架:Luth的训练流程主要包括以下几个阶段:1) 选择一个预训练的小型语言模型作为基础模型。2) 收集和整理高质量的法语数据集。3) 在法语数据集上对基础模型进行后训练,使其适应法语语言的特性。4) 使用模型合并技术,将后训练后的模型与原始模型进行合并,以保留或增强原始模型的英语能力。
关键创新:该论文的关键创新在于针对法语小型语言模型的高效特化方法。通过精心选择和处理法语数据,并结合模型合并技术,Luth能够在不显著增加模型大小的情况下,显著提高法语性能,同时保持或增强英语能力。这种方法为其他低资源语言的模型特化提供了借鉴。
关键设计:论文的关键设计包括:1) 精心策划的高质量法语数据集,保证了后训练的有效性。2) 针对法语语言特性的后训练策略,例如调整学习率、训练轮数等。3) 模型合并策略,例如使用平均权重或更复杂的合并算法,以平衡法语和英语的性能。
🖼️ 关键图片

📊 实验亮点
Luth在多个法语基准测试中优于所有同等规模的开源模型,证明了其在法语小型语言模型领域的领先地位。通过战略性模型合并,Luth不仅提高了法语性能,还保留了其原始的英语能力,实现了跨语言性能的提升。这些实验结果表明,Luth是法语小型语言模型的新技术水平。
🎯 应用场景
Luth的潜在应用领域包括法语自然语言处理的各个方面,例如机器翻译、文本摘要、情感分析、问答系统等。它可以作为法语小型语言模型的基础,为各种下游任务提供支持。此外,Luth的研究方法也可以推广到其他低资源语言的模型特化,促进多语言自然语言处理的发展。Luth的发布将促进法语自然语言处理的研究和应用,并为未来的法语语言模型发展奠定基础。
📄 摘要(原文)
The landscape of Large Language Models (LLMs) remains predominantly English-centric, resulting in a significant performance gap for other major languages, such as French, especially in the context of Small Language Models (SLMs). Existing multilingual models demonstrate considerably lower performance in French compared to English, and research on efficient adaptation methods for French remains limited. To address this, we introduce \textbf{Luth}, a family of French-specialized SLMs: through targeted post-training on curated, high-quality French data, our models outperform all open-source counterparts of comparable size on multiple French benchmarks while retaining their original English capabilities. We further show that strategic model merging enhances performance in both languages, establishing Luth as a new state of the art for French SLMs and a robust baseline for future French-language research.