EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget
作者: Liang Chen, Xueting Han, Qizhou Wang, Bo Han, Jing Bai, Hinrich Schutze, Kam-Fai Wong
分类: cs.CL
发布日期: 2025-10-07
💡 一句话要点
提出EEPO,通过采样后遗忘机制增强LLM在强化学习中的探索能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 探索与利用 策略优化 采样后遗忘
📋 核心要点
- 现有RLVR方法过度强调利用,导致探索能力不足,陷入局部最优,无法充分利用LLM的潜力。
- EEPO通过两阶段rollout和自适应遗忘机制,抑制已采样响应,迫使模型探索更多样化的输出空间。
- 实验表明,EEPO在多个推理基准上显著优于GRPO,提升了LLM在强化学习中的性能。
📝 摘要(中文)
在大型语言模型(LLM)的可验证奖励强化学习(RLVR)中,平衡探索与利用仍然是一个核心挑战。现有的RLVR方法通常过度强调利用,导致熵坍塌、探索能力下降,并最终限制性能提升。增加策略随机性的技术虽然可以促进探索,但常常无法摆脱主导行为模式。这会形成一个自我强化的循环——重复采样和奖励主导模式——进一步削弱探索。我们引入了探索增强策略优化(EEPO),该框架通过具有自适应遗忘的两阶段rollout来促进探索。在第一阶段,模型生成一半的轨迹;然后进行轻量级的遗忘步骤,以暂时抑制这些采样的响应,迫使第二阶段探索输出空间的不同区域。这种采样后遗忘机制打破了自我强化循环,并在rollout期间促进更广泛的探索。在五个推理基准测试中,EEPO优于GRPO,在Qwen2.5-3B上实现了平均24.3%的相对收益,在Llama3.2-3B-Instruct上实现了33.0%的相对收益,在Qwen3-8B-Base上实现了10.4%的相对收益。
🔬 方法详解
问题定义:现有基于强化学习的大语言模型优化方法,在探索和利用之间存在不平衡,倾向于过度利用已知的优势策略,导致探索不足,容易陷入局部最优解,限制了模型的性能提升。尤其是在奖励稀疏或者奖励函数设计不合理的情况下,这个问题会更加严重。
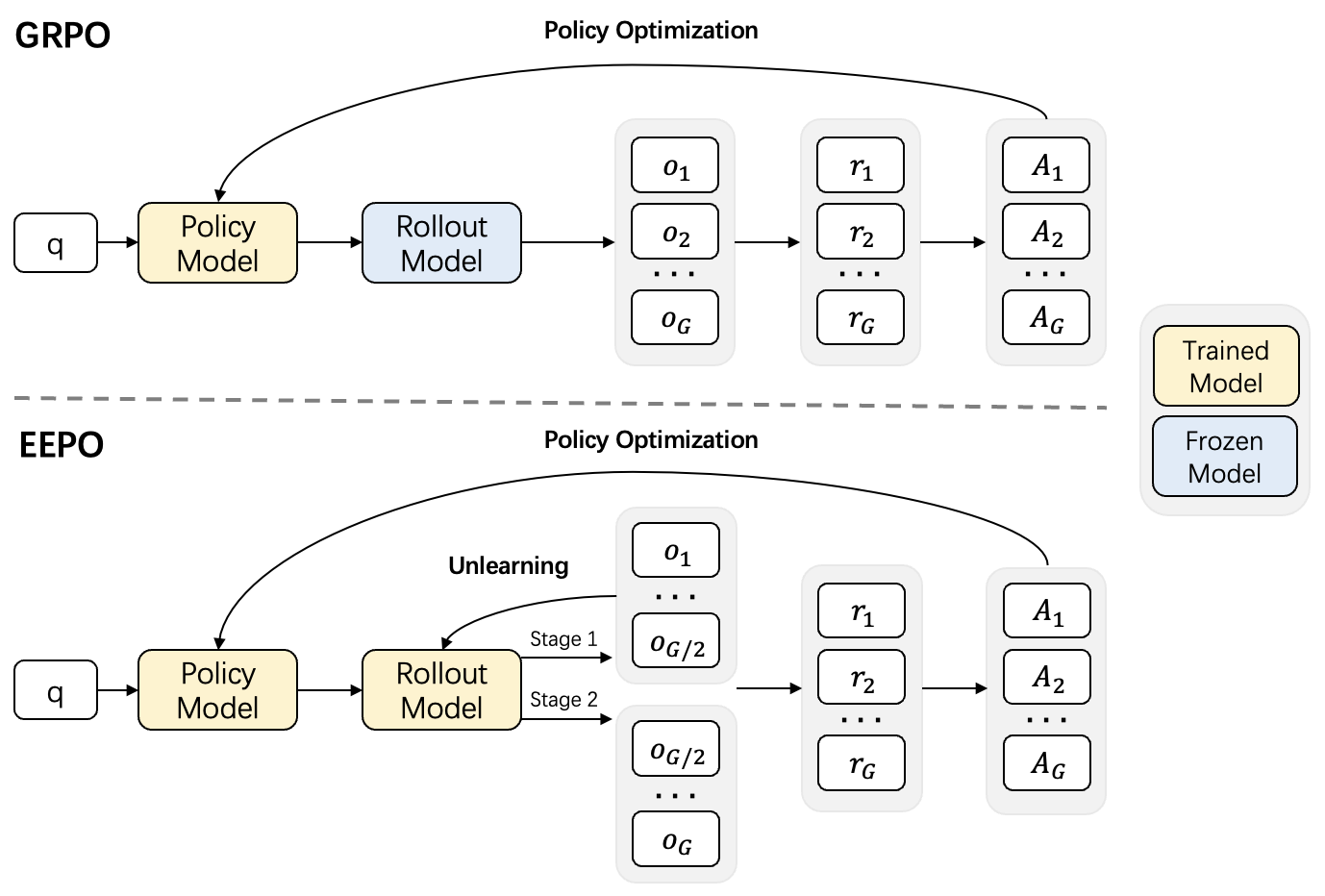
核心思路:EEPO的核心思路是通过“采样后遗忘”机制,打破模型对当前优势策略的过度依赖,鼓励模型探索更多未知的策略空间。具体来说,模型先进行一部分采样,然后通过一个轻量级的“遗忘”步骤,降低这些已采样策略的概率,从而迫使模型在后续的采样中探索不同的行为模式。
技术框架:EEPO包含两个主要的阶段:采样阶段和遗忘阶段。在采样阶段,模型首先生成一部分轨迹(例如,总轨迹的一半)。然后,进入遗忘阶段,对已采样的轨迹进行处理,降低这些轨迹出现的概率。最后,模型再次进行采样,生成剩余的轨迹。这两个阶段生成的轨迹共同用于后续的策略优化。
关键创新:EEPO的关键创新在于其“采样后遗忘”机制。与传统的增加策略随机性的方法不同,EEPO不是简单地增加探索的概率,而是主动抑制已探索过的策略,从而更有效地引导模型探索新的策略空间。这种机制可以有效地打破自我强化的循环,避免模型陷入局部最优。
关键设计:EEPO中的“遗忘”步骤可以通过多种方式实现,例如,可以通过修改模型的损失函数,降低已采样轨迹的权重;也可以通过对模型的参数进行微调,降低已采样轨迹的概率。论文中具体采用哪种方式实现“遗忘”步骤,以及如何自适应地调整遗忘的程度,是影响EEPO性能的关键设计因素。具体的参数设置和损失函数细节需要在论文中查找。
🖼️ 关键图片
📊 实验亮点
EEPO在五个推理基准测试中表现出色,显著优于GRPO。具体而言,在Qwen2.5-3B上实现了平均24.3%的相对收益,在Llama3.2-3B-Instruct上实现了33.0%的相对收益,在Qwen3-8B-Base上实现了10.4%的相对收益。这些结果表明,EEPO能够有效地增强LLM在强化学习中的探索能力,并提高其性能。
🎯 应用场景
EEPO方法具有广泛的应用前景,可以应用于各种需要探索和利用平衡的强化学习任务中,尤其是在奖励稀疏或奖励函数设计不完善的情况下。例如,可以应用于机器人控制、游戏AI、自动驾驶等领域,提高智能体的学习效率和性能。
📄 摘要(原文)
Balancing exploration and exploitation remains a central challenge in reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs). Current RLVR methods often overemphasize exploitation, leading to entropy collapse, diminished exploratory capacity, and ultimately limited performance gains. Although techniques that increase policy stochasticity can promote exploration, they frequently fail to escape dominant behavioral modes. This creates a self-reinforcing loop-repeatedly sampling and rewarding dominant modes-that further erodes exploration. We introduce Exploration-Enhanced Policy Optimization (EEPO), a framework that promotes exploration via two-stage rollouts with adaptive unlearning. In the first stage, the model generates half of the trajectories; it then undergoes a lightweight unlearning step to temporarily suppress these sampled responses, forcing the second stage to explore different regions of the output space. This sample-then-forget mechanism disrupts the self-reinforcing loop and promotes wider exploration during rollouts. Across five reasoning benchmarks, EEPO outperforms GRPO, achieving average relative gains of 24.3% on Qwen2.5-3B, 33.0% on Llama3.2-3B-Instruct, and 10.4% on Qwen3-8B-Base.