DecEx-RAG: Boosting Agentic Retrieval-Augmented Generation with Decision and Execution Optimization via Process Supervision
作者: Yongqi Leng, Yikun Lei, Xikai Liu, Meizhi Zhong, Bojian Xiong, Yurong Zhang, Yan Gao, Yi Wu, Yao Hu, Deyi Xiong
分类: cs.CL
发布日期: 2025-10-07
🔗 代码/项目: GITHUB
💡 一句话要点
DecEx-RAG:通过过程监督优化决策与执行,提升Agentic RAG性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic RAG 检索增强生成 强化学习 马尔可夫决策过程 过程监督 任务分解 知识检索
📋 核心要点
- 现有Agentic RAG方法依赖结果监督强化学习,但存在探索效率低、奖励稀疏和反馈模糊等问题。
- DecEx-RAG将RAG建模为MDP,结合决策和执行,并提出剪枝策略优化数据扩展,实现过程级策略优化。
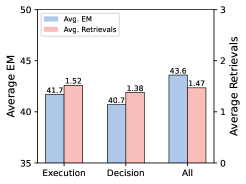
- 实验结果表明,DecEx-RAG在多个数据集上显著优于现有基线,并大幅提升了数据构建效率。
📝 摘要(中文)
Agentic RAG通过动态检索和自适应工作流增强了复杂任务的处理能力。现有方法(如Search-R1)采用结果监督强化学习,但存在探索效率低、奖励信号稀疏和全局奖励反馈模糊等问题。为了解决这些挑战,我们提出了DecEx-RAG,它将RAG建模为包含决策和执行的马尔可夫决策过程(MDP),并引入高效的剪枝策略来优化数据扩展。通过全面的过程级策略优化,DecEx-RAG显著增强了大型语言模型(LLM)的自主任务分解、动态检索和高质量答案生成能力。实验表明,DecEx-RAG在六个数据集上的平均绝对性能提升了6.2%,明显优于现有基线。此外,剪枝策略将数据构建效率提高了近6倍,为过程监督RAG训练提供了一种高效的解决方案。代码已开源。
🔬 方法详解
问题定义:现有Agentic RAG方法在处理复杂任务时,依赖于结果监督的强化学习,这导致了探索效率低下,奖励信号稀疏,以及全局奖励反馈模糊的问题。这些问题限制了模型在复杂任务中的学习和优化能力。
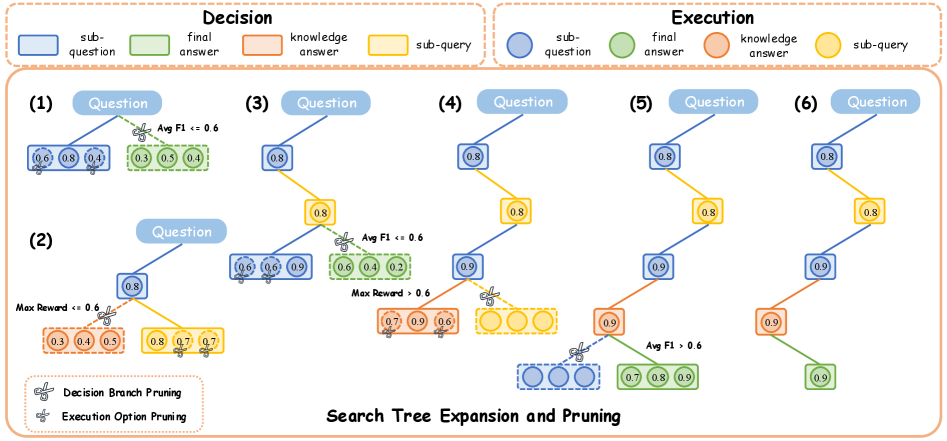
核心思路:DecEx-RAG的核心思路是将RAG过程建模为一个马尔可夫决策过程(MDP),显式地考虑决策(检索、任务分解等)和执行(生成答案)两个环节。通过过程监督,为每个环节提供更细粒度的反馈,从而提高学习效率和性能。此外,引入剪枝策略来优化数据扩展,减少训练成本。
技术框架:DecEx-RAG的整体框架包括以下几个主要模块:1) 任务分解模块:将复杂任务分解为更小的子任务。2) 检索模块:根据当前子任务,从知识库中检索相关信息。3) 执行模块:利用检索到的信息生成答案。4) 决策模块:决定下一步的动作,例如继续分解任务、检索信息或生成最终答案。整个过程被建模为MDP,通过强化学习进行优化。
关键创新:DecEx-RAG的关键创新在于:1) 将RAG过程建模为MDP,显式地考虑决策和执行环节,实现过程监督。2) 引入高效的剪枝策略,优化数据扩展,提高训练效率。3) 通过过程级策略优化,增强了LLM的自主任务分解、动态检索和高质量答案生成能力。与现有方法相比,DecEx-RAG不再仅仅依赖最终结果的奖励,而是对整个过程进行监督和优化。
关键设计:DecEx-RAG的关键设计包括:1) 状态表示:定义MDP的状态,包括当前任务、已检索到的信息等。2) 动作空间:定义MDP的动作,包括任务分解、检索、生成答案等。3) 奖励函数:设计过程级别的奖励函数,为每个环节提供反馈。4) 剪枝策略:设计高效的剪枝策略,减少数据扩展的规模,提高训练效率。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DecEx-RAG在六个数据集上取得了显著的性能提升,平均绝对性能提升了6.2%,明显优于现有基线。此外,剪枝策略将数据构建效率提高了近6倍,为过程监督RAG训练提供了一种高效的解决方案。这些结果验证了DecEx-RAG的有效性和高效性。
🎯 应用场景
DecEx-RAG具有广泛的应用前景,可以应用于智能客服、问答系统、知识图谱问答等领域。通过增强LLM的自主任务分解、动态检索和高质量答案生成能力,可以显著提升这些应用的用户体验和效率。未来,该方法还可以扩展到更复杂的任务中,例如自动化报告生成、智能决策支持等。
📄 摘要(原文)
Agentic Retrieval-Augmented Generation (Agentic RAG) enhances the processing capability for complex tasks through dynamic retrieval and adaptive workflows. Recent advances (e.g., Search-R1) have shown that outcome-supervised reinforcement learning demonstrate strong performance. However, this approach still suffers from inefficient exploration, sparse reward signals, and ambiguous global reward feedback. To address these challenges, we propose DecEx-RAG, which models RAG as a Markov Decision Process (MDP) incorporating decision-making and execution, while introducing an efficient pruning strategy to optimize data expansion. Through comprehensive process-level policy optimization, DecEx-RAG significantly enhances the autonomous task decomposition, dynamic retrieval, and high-quality answer generation capabilities of large language models (LLMs). Experiments show that DecEx-RAG achieves an average absolute performance improvement of $6.2\%$ across six datasets, significantly outperforming existing baselines. Moreover, the pruning strategy improves data construction efficiency by nearly $6 \times$, providing an efficient solution for process-supervised RAG training. The code is available at https://github.com/sdsxdxl/DecEx-RAG.