MADIAVE: Multi-Agent Debate for Implicit Attribute Value Extraction
作者: Wei-Chieh Huang, Cornelia Caragea
分类: cs.CL, cs.AI
发布日期: 2025-10-07 (更新: 2026-01-15)
备注: Accepted by EACL 2026 (Findings)
💡 一句话要点
提出MADIAVE,利用多智能体辩论框架解决电商中隐式属性值抽取难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 辩论框架 隐式属性值抽取 多模态学习 电商 大型语言模型 视觉-文本理解
📋 核心要点
- 多模态数据复杂,视觉-文本理解存在差距,导致隐式属性值抽取(AVE)任务面临挑战。
- MADIAVE框架采用多智能体辩论机制,通过迭代优化,提升推断性能和鲁棒性。
- 实验表明,少量辩论回合即可显著提高AVE准确性,尤其对初始性能较差的属性提升明显。
📝 摘要(中文)
隐式属性值抽取(AVE)对于准确表示电商产品至关重要,它能从多模态数据中推断潜在属性。尽管多模态大型语言模型(MLLM)取得了进展,但由于多维数据的复杂性和视觉-文本理解的差距,隐式AVE仍然具有挑战性。本文提出了MADIAVE,一个多智能体辩论框架,它使用多个MLLM智能体来迭代地改进推断。通过一系列辩论回合,智能体验证和更新彼此的响应,从而提高推断性能和鲁棒性。在ImplicitAVE数据集上的实验表明,即使是几轮辩论也能显著提高准确性,尤其是在初始性能较低的属性上。我们系统地评估了各种辩论配置,包括相同或不同的MLLM智能体,并分析了辩论回合如何影响收敛动态。我们的研究结果突出了多智能体辩论策略在解决单智能体方法局限性方面的潜力,并为多模态电商中的隐式AVE提供了一个可扩展的解决方案。
🔬 方法详解
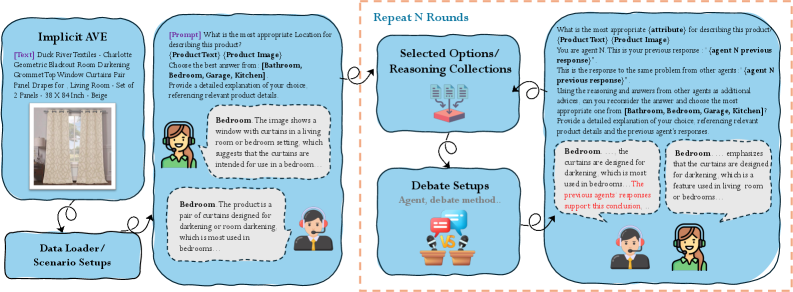
问题定义:论文旨在解决电商领域中隐式属性值抽取(AVE)的问题。现有方法,特别是单智能体的多模态大型语言模型(MLLM),在处理复杂多维数据时,由于视觉-文本理解的局限性,难以准确推断出产品的潜在属性。这些痛点导致产品表示不完整,影响用户体验和推荐效果。
核心思路:论文的核心思路是引入多智能体辩论机制。通过让多个MLLM智能体针对同一问题进行辩论,互相验证和更新彼此的答案,从而模拟人类专家团队协作解决问题的过程。这种方法旨在利用不同智能体的优势,弥补彼此的不足,提高推断的准确性和鲁棒性。
技术框架:MADIAVE框架包含以下主要阶段:1) 初始化:每个智能体独立生成初始答案。2) 辩论回合:每个智能体根据其他智能体的答案,更新自己的答案。这个过程重复多轮。3) 聚合:将所有智能体的最终答案进行聚合,得到最终的预测结果。框架允许配置不同的智能体类型(相同或不同MLLM),以及调整辩论回合数。
关键创新:MADIAVE的关键创新在于将多智能体辩论的思想引入到隐式属性值抽取任务中。与传统的单智能体方法相比,MADIAVE能够通过智能体之间的协作,更有效地利用多模态信息,减少错误推断,提高整体性能。这种方法提供了一种可扩展的解决方案,可以灵活地集成不同的MLLM智能体。
关键设计:论文中,智能体可以是相同的或不同的MLLM模型。辩论回合数是一个关键参数,影响着模型的收敛速度和最终性能。论文分析了不同辩论回合数对模型性能的影响,并探讨了如何选择合适的辩论回合数以达到最佳效果。此外,论文还研究了不同的聚合策略,例如投票或加权平均,以提高最终预测的准确性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MADIAVE框架在ImplicitAVE数据集上显著提升了隐式属性值抽取的准确性。即使经过几轮辩论,性能也得到了显著提高,尤其是在初始性能较低的属性上。例如,与单智能体基线相比,MADIAVE在某些属性上的准确率提升超过10%。实验还验证了不同智能体配置和辩论回合数对模型性能的影响。
🎯 应用场景
MADIAVE可应用于电商平台,提升商品信息的完整性和准确性,从而改善用户搜索体验和商品推荐效果。该方法还可扩展到其他多模态数据分析场景,例如图像描述生成、视频内容理解等,具有广泛的应用前景。未来,可以探索更复杂的智能体交互策略,进一步提升系统性能。
📄 摘要(原文)
Implicit Attribute Value Extraction (AVE) is essential for accurately representing products in e-commerce, as it infers latent attributes from multimodal data. Despite advances in multimodal large language models (MLLMs), implicit AVE remains challenging due to the complexity of multidimensional data and gaps in vision-text understanding. In this work, we introduce MADIAVE, a multi-agent debate framework that employs multiple MLLM agents to iteratively refine inferences. Through a series of debate rounds, agents verify and update each other's responses, thereby improving inference performance and robustness. Experiments on the ImplicitAVE dataset demonstrate that even a few rounds of debate significantly boost accuracy, especially for attributes with initially low performance. We systematically evaluate various debate configurations, including identical or different MLLM agents, and analyze how debate rounds affect convergence dynamics. Our findings highlight the potential of multi-agent debate strategies to address the limitations of single-agent approaches and offer a scalable solution for implicit AVE in multimodal e-commerce.