Activation-Informed Pareto-Guided Low-Rank Compression for Efficient LLM/VLM
作者: Ryan Solgi, Parsa Madinei, Jiayi Tian, Rupak Swaminathan, Jing Liu, Nathan Susanj, Zheng Zhang
分类: cs.CL, cs.LG
发布日期: 2025-10-07
💡 一句话要点
提出PGSVD,通过激活感知的Pareto引导低秩压缩高效压缩LLM/VLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩压缩 模型压缩 Pareto优化 激活感知 大型语言模型 视觉语言模型 模型优化 奇异值分解
📋 核心要点
- LLM/VLM部署面临内存和计算挑战,现有低秩压缩方法缺乏对激活信息的有效利用。
- 提出PGSVD框架,通过激活信息指导Pareto最优秩选择,实现更高效的低秩压缩。
- 实验表明,PGSVD在LLM和VLM上实现了更好的精度和推理加速,优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)和视觉语言模型(VLM)虽然取得了最先进的性能,但在部署时面临着巨大的内存和计算挑战。为了解决这一挑战,我们提出了一种新颖的低秩压缩框架。首先,我们通过逐层激活的压缩误差来限制网络损失的变化,填补了文献中的一个理论空白。然后,我们将低秩模型压缩公式化为一个双目标优化问题,并证明单一的均匀容差可以产生替代Pareto最优的异构秩。基于我们的理论见解,我们提出了Pareto引导奇异值分解(PGSVD),这是一个零样本pipeline,通过Pareto引导的秩选择和交替最小二乘实现来改进激活感知的压缩。我们将PGSVD应用于LLM和VLM,在相同的压缩水平和推理加速下显示出更好的准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)和视觉语言模型(VLM)在部署时面临的内存和计算资源瓶颈问题。现有的低秩压缩方法通常忽略了模型中不同层激活值的差异,导致压缩后的模型性能下降,无法充分利用压缩潜力。
核心思路:论文的核心思路是利用模型各层的激活信息来指导低秩压缩过程,从而在压缩模型大小的同时,尽可能地保留模型的性能。具体来说,通过分析各层激活值对模型损失的影响,自适应地选择每一层的秩,实现Pareto最优的压缩效果。
技术框架:PGSVD框架主要包含以下几个阶段:1) 激活信息分析:计算模型各层的激活值,并估计其对模型损失的影响。2) Pareto引导的秩选择:基于激活信息,将低秩压缩问题转化为一个双目标优化问题,目标是最小化模型大小和最大化模型性能。利用Pareto优化算法,找到一组Pareto最优的秩配置。3) 交替最小二乘实现:使用交替最小二乘法(Alternating Least Squares, ALS)来求解低秩分解后的模型参数。
关键创新:论文的关键创新在于提出了激活感知的Pareto引导秩选择方法。与传统的均匀秩选择方法相比,PGSVD能够根据模型各层的激活信息,自适应地选择每一层的秩,从而在压缩模型大小的同时,更好地保留模型的性能。此外,论文还从理论上证明了单一的均匀容差可以产生替代Pareto最优的异构秩。
关键设计:在Pareto引导的秩选择中,论文将低秩压缩问题建模为一个双目标优化问题,目标函数包括模型大小和模型性能。模型大小可以通过压缩后的参数数量来衡量,模型性能可以通过验证集上的损失函数来衡量。论文使用了一种基于梯度的Pareto优化算法来求解该问题。在交替最小二乘实现中,论文使用了一种高效的ALS算法来求解低秩分解后的模型参数,并采用了一些技巧来加速收敛。
🖼️ 关键图片


📊 实验亮点
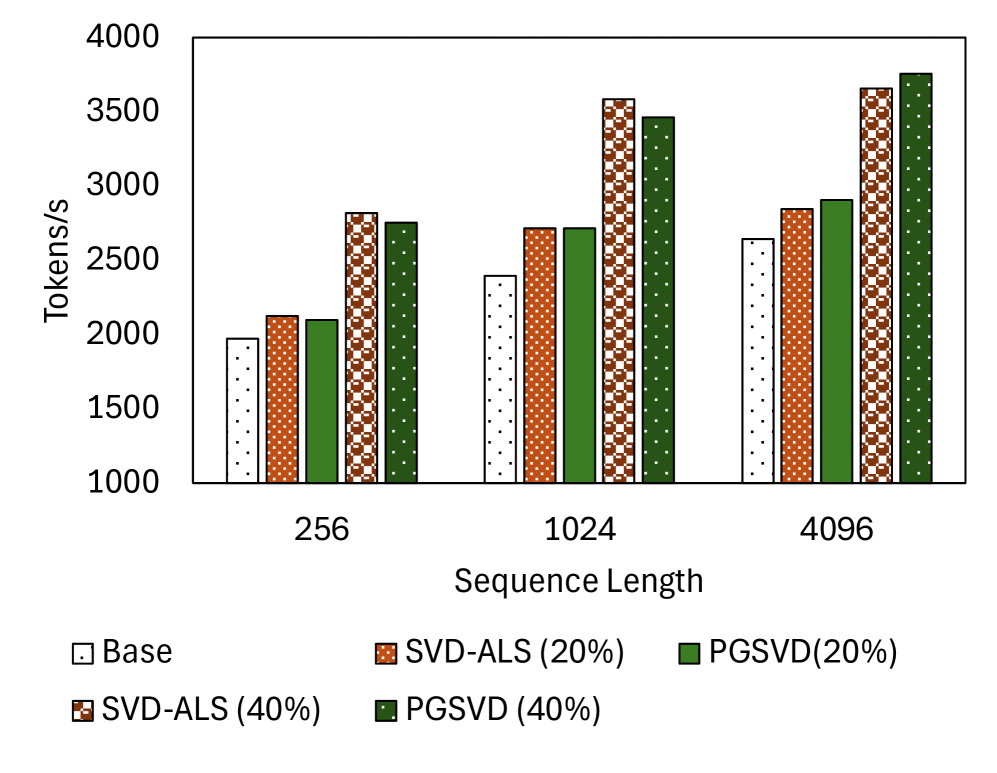
PGSVD在LLM和VLM上均取得了显著的性能提升。例如,在LLM上,PGSVD在相同压缩率下,精度优于现有方法;在VLM上,PGSVD实现了推理速度的提升,同时保持了较高的精度。实验结果表明,PGSVD是一种有效的LLM/VLM压缩方法。
🎯 应用场景
该研究成果可应用于各种需要高效部署LLM/VLM的场景,例如移动设备、边缘计算设备和资源受限的服务器。通过降低模型大小和计算复杂度,可以使这些模型在资源有限的环境中运行,从而扩展其应用范围,例如智能助手、自动驾驶和医疗诊断。
📄 摘要(原文)
Large language models (LLM) and vision-language models (VLM) have achieved state-of-the-art performance, but they impose significant memory and computing challenges in deployment. We present a novel low-rank compression framework to address this challenge. First, we upper bound the change of network loss via layer-wise activation-based compression errors, filling a theoretical gap in the literature. We then formulate low-rank model compression as a bi-objective optimization and prove that a single uniform tolerance yields surrogate Pareto-optimal heterogeneous ranks. Based on our theoretical insights, we propose Pareto-Guided Singular Value Decomposition (PGSVD), a zero-shot pipeline that improves activation-aware compression via Pareto-guided rank selection and alternating least-squares implementation. We apply PGSVD to both LLM and VLM, showing better accuracy at the same compression levels and inference speedup.