Sci-Phi: A Large Language Model Spatial Audio Descriptor
作者: Xilin Jiang, Hannes Gamper, Sebastian Braun
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-10-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Sci-Phi:首个能完整描述空间音频场景的大语言模型
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间音频 大语言模型 声学场景理解 Ambisonics 音频编码
📋 核心要点
- 现有音频语言模型在声音识别上表现出色,但受限于单通道输入,缺乏对空间信息的理解。
- Sci-Phi通过双空间和频谱编码器,从合成数据中学习,能够估计声源的空间参数和环境特征。
- 实验表明,Sci-Phi在多种复杂场景下表现出良好的鲁棒性,并能推广到真实房间环境。
📝 摘要(中文)
声学场景感知涉及描述声音的类型、时间、方向和距离,以及响度和混响。虽然音频语言模型在声音识别方面表现出色,但单通道输入从根本上限制了空间理解。本文提出了Sci-Phi,一个空间音频大语言模型,它具有双空间和频谱编码器,可以估计所有声源和周围环境的完整参数集。Sci-Phi从超过4000小时的合成一阶Ambisonics录音(包括元数据)中学习,一次性枚举和描述最多四个定向声源,以及非定向背景声音和房间特征。我们使用置换不变协议和15个指标评估模型,这些指标涵盖内容、位置、时间、响度和混响,并分析其在源数量、信噪比、混响水平以及声学、空间或时间上相似的声源的挑战性混合中的鲁棒性。值得注意的是,Sci-Phi可以推广到真实房间脉冲响应,且性能仅略有下降。总的来说,这项工作建立了第一个能够完整描述空间场景的音频LLM,具有强大的实际部署潜力。
🔬 方法详解
问题定义:现有音频语言模型主要关注声音识别,忽略了空间信息,无法完整理解声学场景。缺乏对声源方向、距离、混响等空间属性的建模,限制了其在需要空间感知的应用中的潜力。
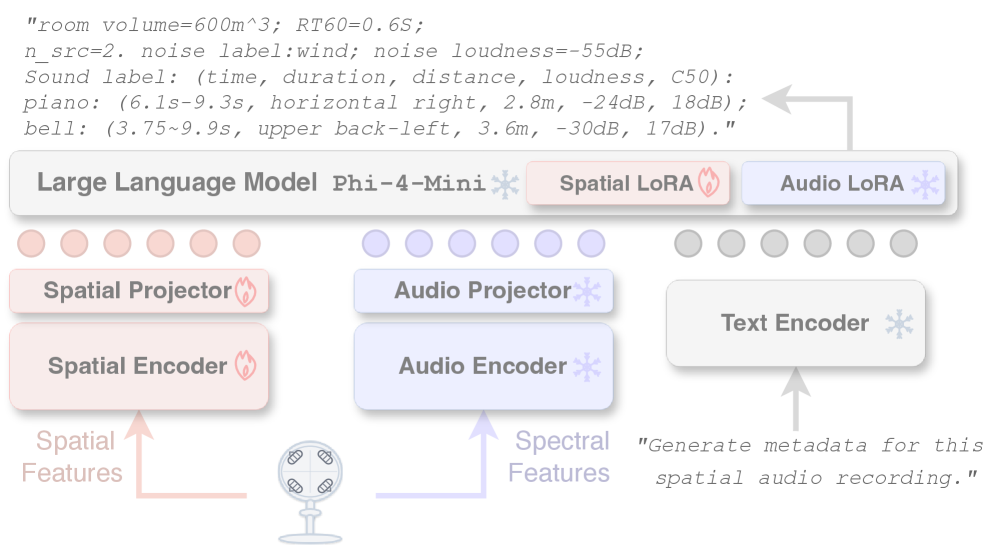
核心思路:Sci-Phi的核心思路是构建一个能够同时处理频谱信息和空间信息的音频大语言模型。通过双编码器结构,分别提取音频的频谱特征和空间特征,并将其融合,从而实现对声学场景的全面理解和描述。
技术框架:Sci-Phi包含双空间和频谱编码器。空间编码器处理Ambisonics音频输入,提取空间特征;频谱编码器处理音频的频谱信息,提取声音内容特征。两个编码器的输出被融合后输入到大语言模型中,模型输出对声源数量、位置、时间、响度和混响等参数的估计。模型训练使用合成的Ambisonics录音数据,包含丰富的元数据信息。
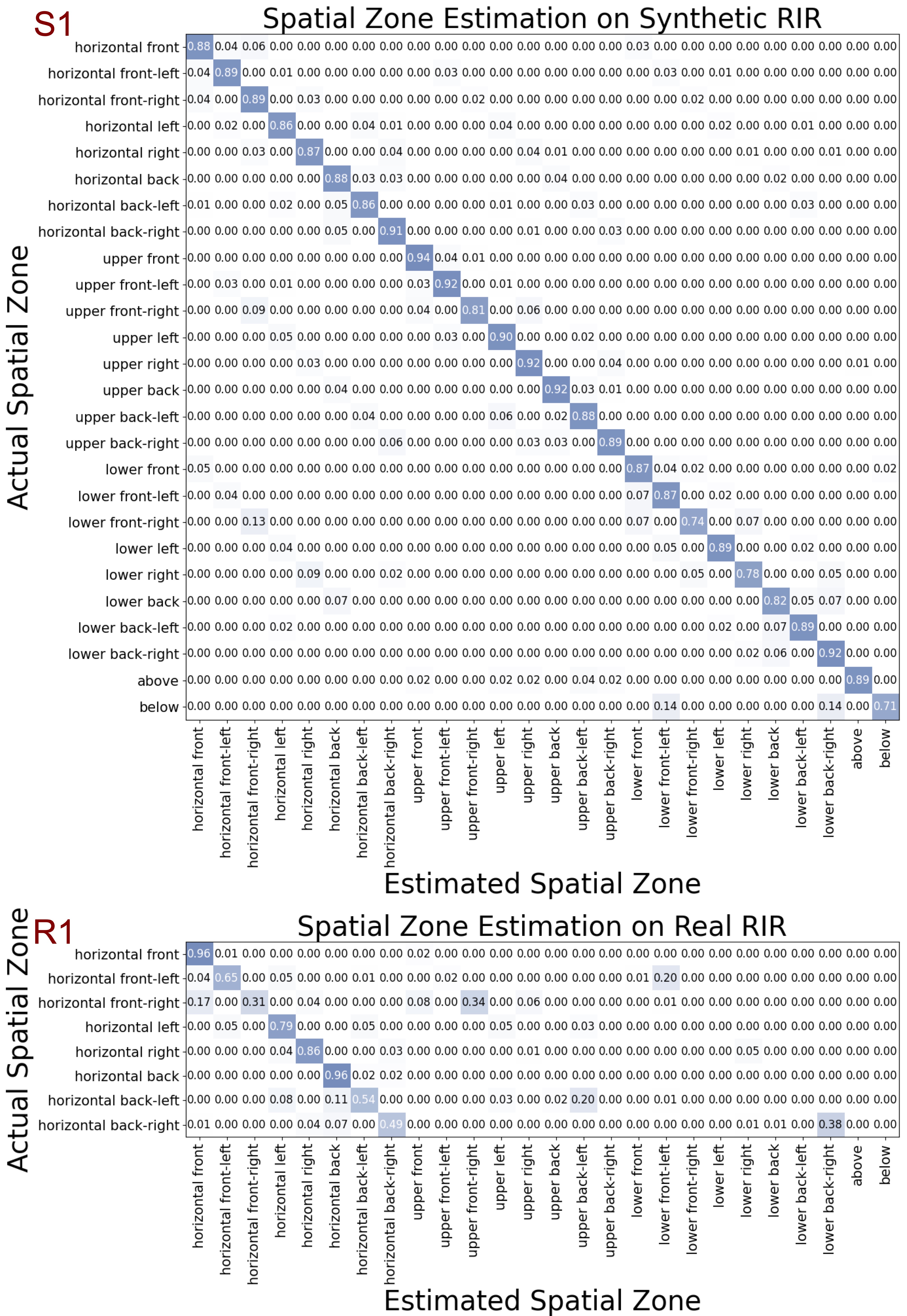
关键创新:Sci-Phi最重要的创新在于其能够同时处理音频的频谱信息和空间信息,从而实现对声学场景的完整描述。这是首个能够完成此任务的音频大语言模型。此外,模型还具有较强的鲁棒性,能够处理复杂的声学场景,并能推广到真实房间环境。
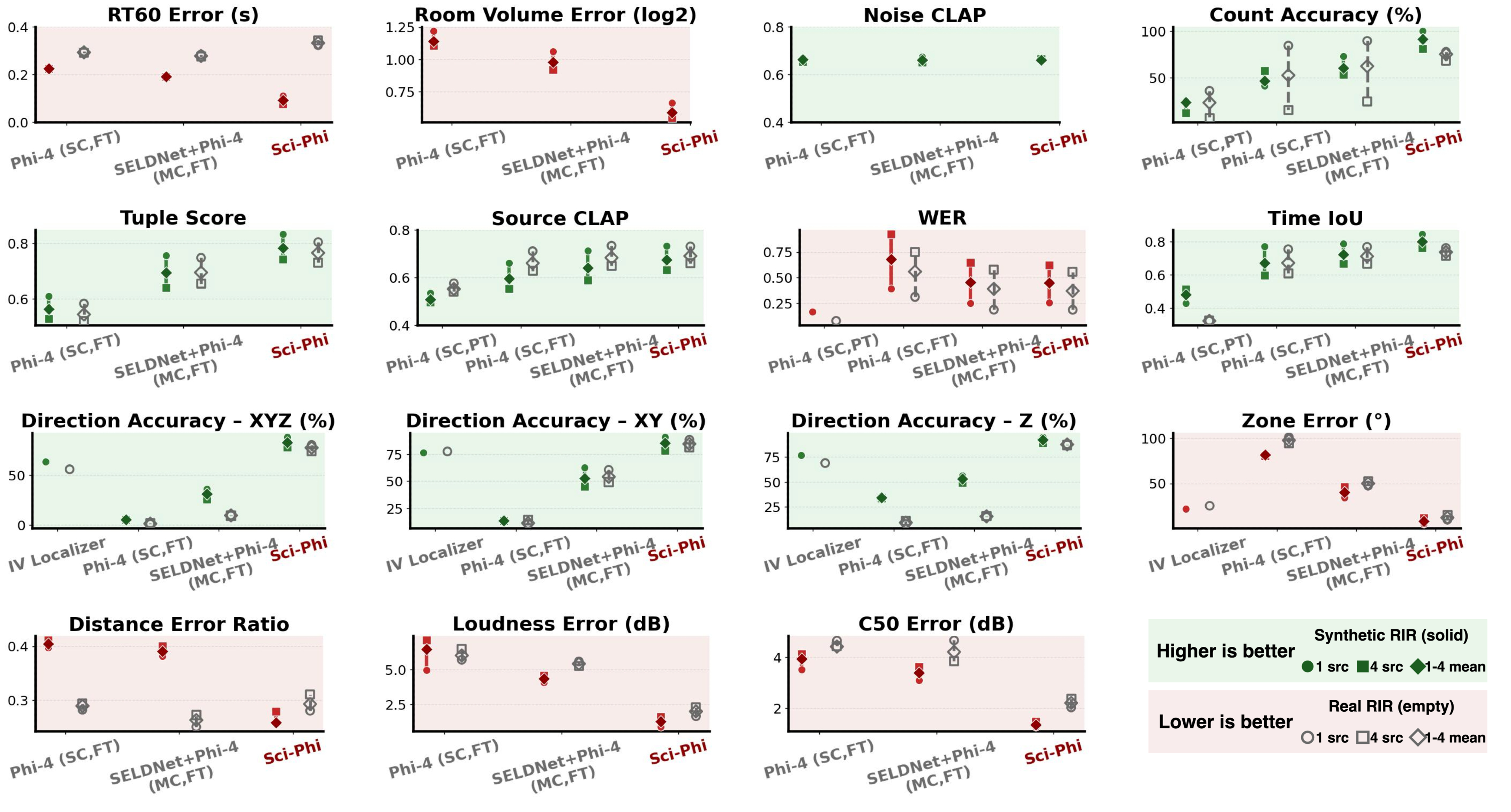
关键设计:模型使用超过4000小时的合成一阶Ambisonics录音进行训练。评估指标包括内容、位置、时间、响度和混响等15个方面。采用置换不变协议来评估模型对声源顺序的鲁棒性。模型在不同信噪比、混响水平以及声学、空间或时间上相似的声源混合场景下进行了测试。
🖼️ 关键图片
📊 实验亮点
Sci-Phi在包含多达四个定向声源的复杂声学场景中表现出色,能够准确估计声源的位置、时间和响度等参数。实验表明,Sci-Phi在真实房间脉冲响应数据上也能保持较好的性能,证明了其在实际应用中的潜力。该模型在各种指标上都取得了显著的成果,为空间音频理解领域树立了新的标杆。
🎯 应用场景
Sci-Phi在虚拟现实、增强现实、游戏、音频编辑、智能家居等领域具有广泛的应用前景。它可以用于创建更逼真的沉浸式音频体验,提高音频编辑的效率,以及实现更智能的声学环境感知和控制。未来,Sci-Phi有望成为智能音频处理和空间音频理解的基础模型。
📄 摘要(原文)
Acoustic scene perception involves describing the type of sounds, their timing, their direction and distance, as well as their loudness and reverberation. While audio language models excel in sound recognition, single-channel input fundamentally limits spatial understanding. This work presents Sci-Phi, a spatial audio large language model with dual spatial and spectral encoders that estimates a complete parameter set for all sound sources and the surrounding environment. Learning from over 4,000 hours of synthetic first-order Ambisonics recordings including metadata, Sci-Phi enumerates and describes up to four directional sound sources in one pass, alongside non-directional background sounds and room characteristics. We evaluate the model with a permutation-invariant protocol and 15 metrics covering content, location, timing, loudness, and reverberation, and analyze its robustness across source counts, signal-to-noise ratios, reverberation levels, and challenging mixtures of acoustically, spatially, or temporally similar sources. Notably, Sci-Phi generalizes to real room impulse responses with only minor performance degradation. Overall, this work establishes the first audio LLM capable of full spatial-scene description, with strong potential for real-world deployment. Demo: https://sci-phi-audio.github.io/demo