Self-Filtered Distillation with LLMs-generated Trust Indicators for Reliable Patent Classification
作者: Yongmin Yoo, Xu Zhang, Longbing Cao
分类: cs.CL
发布日期: 2025-10-06 (更新: 2026-01-05)
💡 一句话要点
提出自过滤蒸馏框架,利用LLM生成的可信度指标提升专利分类可靠性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 专利分类 知识蒸馏 大型语言模型 可信度评估 自过滤蒸馏
📋 核心要点
- 现有方法直接使用LLM生成的解释作为监督信号,易受噪声干扰,影响训练稳定性。
- 提出自过滤蒸馏框架,将LLM生成的解释视为可信度信号,通过可信度指标指导选择性蒸馏。
- 在USPTO-2M数据集上,该方法在准确性、稳定性和可解释性方面优于传统方法。
📝 摘要(中文)
大型语言模型(LLM)越来越多地生成自然语言解释以增强可解释性,但这些解释通常包含逻辑错误、标签不匹配和领域特定的偏差。直接使用这些解释作为监督信号存在传播噪声和破坏训练稳定性的风险。为了解决这个问题,我们提出了一种专为专利分类设计的自过滤蒸馏框架,该框架将LLM生成的解释视为可信度信号,而不是ground-truth监督。该框架采用由三个无监督可信度指标指导的选择性蒸馏:(1)自洽性,衡量LLM生成的解释在多次生成中的稳定性;(2)类别蕴含对齐,评估与专利特定类别定义的语义一致性;(3)LLM一致性评分,验证解释-标签的合理性。这些指标被整合到一个统一的可信度分数中,该分数主要用于加权训练样本,并可选择过滤掉极低可信度的样本,从而实现推理感知的监督。在USPTO-2M数据集上的实验表明,我们的方法在准确性、稳定性和可解释性方面始终优于基于标签的学习和传统蒸馏,为在专利分析中利用推理感知的可信度指标建立了一个可靠的范例。
🔬 方法详解
问题定义:论文旨在解决专利分类任务中,如何有效利用大型语言模型(LLM)生成的自然语言解释进行知识蒸馏的问题。现有方法直接将LLM生成的解释作为ground truth进行监督学习,但这些解释往往包含错误、不一致或与领域知识不符的情况,导致噪声传播,影响模型性能。
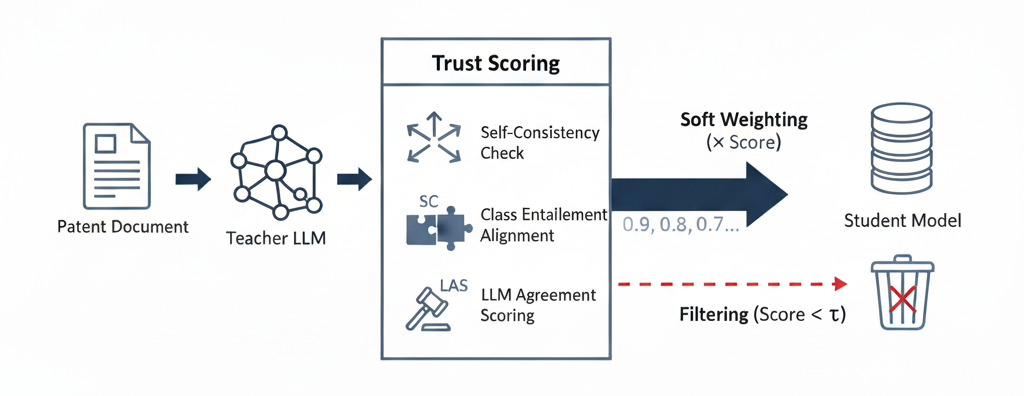
核心思路:论文的核心思路是将LLM生成的解释视为一种“可信度信号”,而不是绝对正确的标签。通过评估这些解释的质量和可靠性,选择性地利用它们进行知识蒸馏。高可信度的解释赋予更高的权重,低可信度的解释则被过滤或降低权重,从而减少噪声的影响。
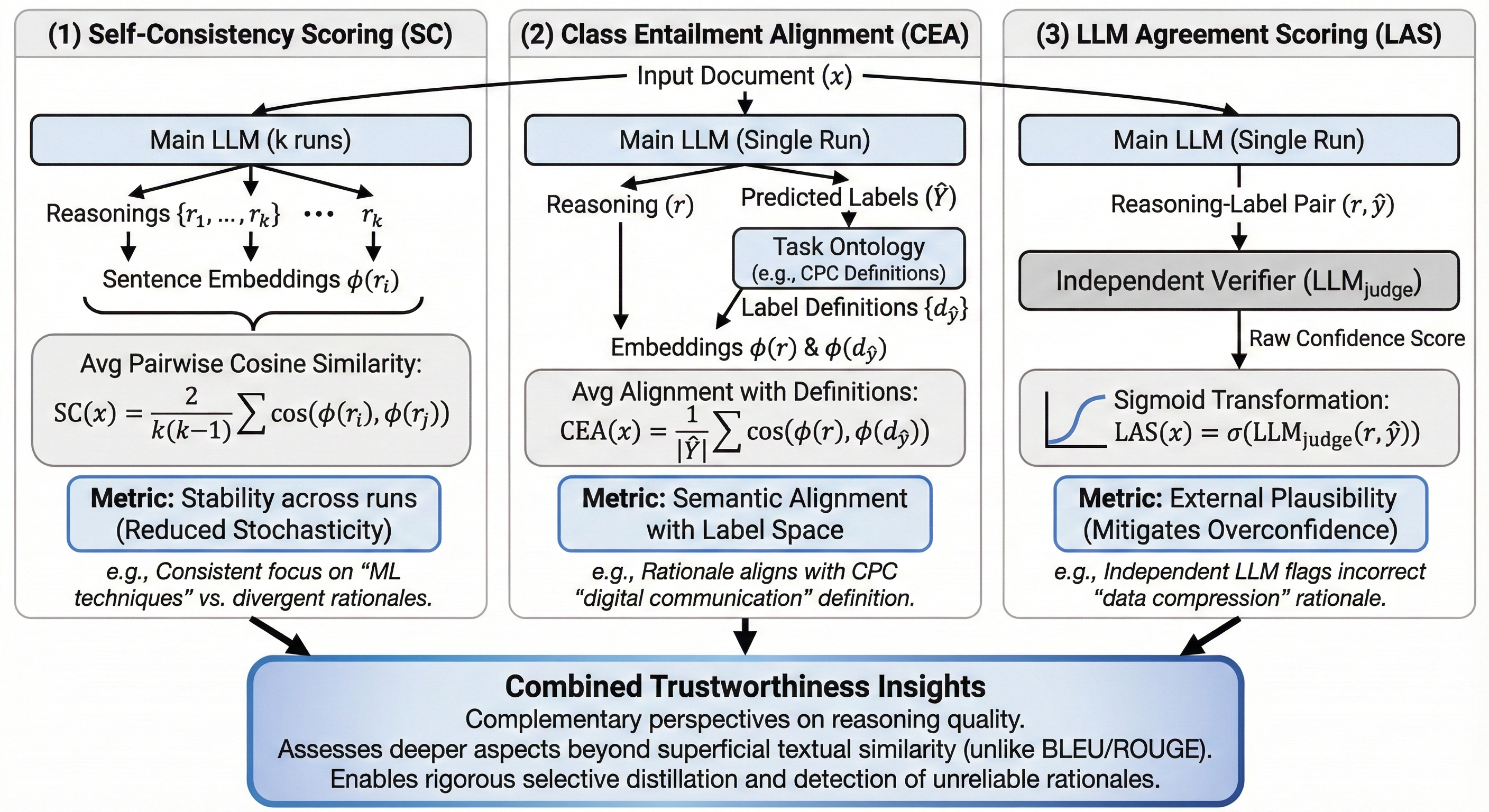
技术框架:该框架主要包含以下几个阶段:1) 使用LLM生成专利文本的解释;2) 计算三个无监督可信度指标:自洽性、类别蕴含对齐和LLM一致性评分;3) 将这些指标整合为统一的可信度分数;4) 使用可信度分数加权训练样本,进行选择性知识蒸馏。可以选择直接过滤掉可信度极低的样本。
关键创新:最重要的创新在于提出了“自过滤蒸馏”的概念,即利用LLM自身的能力来评估其生成的解释的质量,并根据评估结果进行选择性学习。这与传统知识蒸馏方法直接信任教师模型的输出有本质区别。通过引入可信度指标,框架能够更有效地利用LLM的知识,同时避免噪声的负面影响。
关键设计:三个关键的可信度指标分别是:1) 自洽性:通过多次生成解释,计算解释之间的相似度,衡量LLM生成解释的稳定性;2) 类别蕴含对齐:评估LLM生成的解释与专利类别定义的语义一致性,例如使用文本蕴含模型判断解释是否支持所属类别;3) LLM一致性评分:使用另一个LLM判断解释和标签的合理性。这些指标被加权求和,得到最终的可信度分数。训练时,使用可信度分数作为样本权重,并可设置阈值过滤低质量样本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,自过滤蒸馏框架在USPTO-2M数据集上显著优于传统的基于标签的学习和知识蒸馏方法。在准确性方面,该方法取得了明显的提升,同时提高了模型的稳定性和可解释性。具体性能数据未在摘要中明确给出,但强调了其一致性的优越性。
🎯 应用场景
该研究成果可应用于专利分析、法律文本理解、科技情报挖掘等领域。通过提升专利分类的准确性和可解释性,可以帮助研究人员、律师和企业更有效地检索、分析和利用专利信息,加速技术创新和知识产权保护。未来,该方法可以推广到其他需要利用LLM生成解释的文本分类任务中。
📄 摘要(原文)
Large language models (LLMs) increasingly generate natural language rationales to enhance interpretability, but these often contain logical errors, label mismatches, and domain-specific misalignments. Directly using such rationales as supervision risks propagating noise and undermining training stability. To address this challenge, we introduce Self-Filtered Distillation, a framework tailored for patent classification that treats LLM-generated rationales as trust signals rather than ground-truth supervision. The framework employs selective distillation guided by three unsupervised trust metrics: (1) Self-Consistency, which measures the stability of LLM-generated rationales across multiple generations; (2) Class Entailment Alignment, which assesses semantic coherence with patent-specific class definitions; and (3) LLM Agreement Scoring, which validates rationale-label plausibility. These metrics are integrated into a unified trust score that primarily weights training samples while optionally filtering out extremely low-trust cases, enabling reasoning-aware supervision. Experiments on the USPTO-2M dataset show that our method consistently outperforms label-based learning and conventional distillation in accuracy, stability, and interpretability across diverse student architectures, establishing a reliable paradigm for leveraging reasoning-aware trust indicators in patent analytics.