WeatherArchive-Bench: Benchmarking Retrieval-Augmented Reasoning for Historical Weather Archives
作者: Yongan Yu, Xianda Du, Qingchen Hu, Jiahao Liang, Jingwei Ni, Dan Qiang, Kaiyu Huang, Grant McKenzie, Renee Sieber, Fengran Mo
分类: cs.CL, cs.AI
发布日期: 2025-10-06
💡 一句话要点
提出WeatherArchive-Bench,用于评估历史天气档案的检索增强推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 历史天气档案 气候变化 社会脆弱性 社会韧性 大型语言模型 基准测试
📋 核心要点
- 现有方法难以将大规模、数字化质量差、语言古老的历史天气档案转化为气候研究的结构化知识。
- 提出WeatherArchive-Bench基准,包含检索和评估两个任务,用于评估RAG系统在历史天气档案上的性能。
- 实验表明,密集检索器在历史术语上表现不佳,LLM对社会脆弱性和韧性概念存在误解。
📝 摘要(中文)
本文提出了WeatherArchive-Bench,这是一个用于评估检索增强生成(RAG)系统在历史天气档案上的性能的基准。历史天气事件档案是持久的第一手资料记录的集合,提供了关于社会如何经历和应对极端天气事件的丰富且未被利用的叙述。这些定性描述提供了对社会脆弱性和韧性的深刻见解,而这些见解在气象记录中很大程度上是缺失的,因此对于气候科学家理解社会反应非常有价值。然而,它们庞大的规模、嘈杂的数字化质量和古老的语言使得将它们转化为气候研究的结构化知识变得困难。WeatherArchive-Bench包含两个任务:WeatherArchive-Retrieval,衡量系统从超过一百万个档案新闻片段中定位历史上相关段落的能力;以及WeatherArchive-Assessment,评估大型语言模型(LLM)是否可以从极端天气叙述中分类社会脆弱性和韧性指标。对稀疏、密集和重排序检索器以及各种LLM的广泛实验表明,密集检索器通常在历史术语上失败,而LLM经常错误地解释脆弱性和韧性概念。这些发现突出了在推理复杂社会指标方面的关键局限性,并为从档案背景设计更强大的以气候为中心的RAG系统提供了见解。构建的数据集和评估框架可在https://anonymous.4open.science/r/WeatherArchive-Bench/公开获取。
🔬 方法详解
问题定义:论文旨在解决如何有效利用历史天气档案中的信息,以理解社会对极端天气事件的反应。现有方法难以处理历史档案的规模、质量和语言复杂性,导致无法从中提取有用的结构化知识。
核心思路:论文的核心思路是通过构建一个基准测试集,评估检索增强生成(RAG)系统在处理历史天气档案方面的能力。通过分析RAG系统在检索相关信息和评估社会脆弱性与韧性指标方面的表现,揭示现有方法的局限性,并为未来研究提供指导。
技术框架:WeatherArchive-Bench包含两个主要任务:WeatherArchive-Retrieval和WeatherArchive-Assessment。WeatherArchive-Retrieval任务评估检索器从大量档案新闻片段中找到相关段落的能力。WeatherArchive-Assessment任务评估LLM从极端天气叙述中分类社会脆弱性和韧性指标的能力。整体流程包括数据预处理、检索模型选择与训练、LLM选择与微调(可选)、评估指标定义和结果分析。
关键创新:该研究的关键创新在于构建了一个专门针对历史天气档案的RAG评估基准。该基准考虑了历史文本的特殊性,例如古老的语言和特定的历史术语,这与通用RAG基准有所不同。此外,该基准关注社会脆弱性和韧性等复杂概念的评估,这对于气候研究具有重要意义。
关键设计:在WeatherArchive-Retrieval任务中,使用了多种检索器,包括稀疏检索器(如TF-IDF、BM25)、密集检索器(如Sentence-BERT、Contriever)和重排序检索器(如Cross-Encoder)。在WeatherArchive-Assessment任务中,使用了多种LLM,包括GPT-3、GPT-4等。评估指标包括检索任务的Recall@K和Assessment任务的准确率、F1值等。数据集包含超过一百万个档案新闻片段,并进行了人工标注。
🖼️ 关键图片


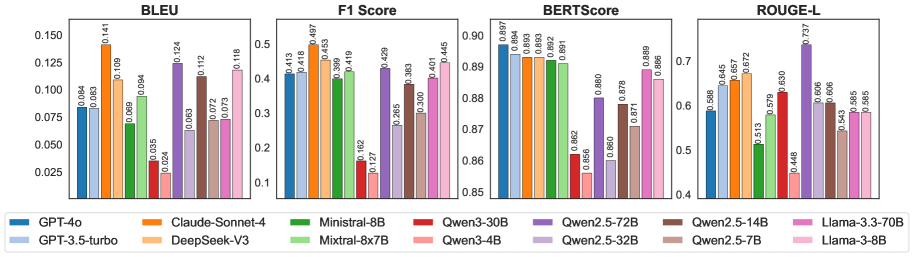
📊 实验亮点
实验结果表明,密集检索器在处理历史术语时表现不佳,而LLM在理解社会脆弱性和韧性概念方面存在困难。例如,密集检索器在WeatherArchive-Retrieval任务上的Recall@K低于稀疏检索器。LLM在WeatherArchive-Assessment任务上的准确率低于人类专家。这些结果揭示了现有RAG系统在处理历史档案和复杂社会概念方面的局限性。
🎯 应用场景
该研究成果可应用于气候变化研究、社会科学研究和历史研究等领域。通过利用历史天气档案中的信息,可以更好地理解社会对极端天气事件的反应,评估社会脆弱性和韧性,并为制定更有效的气候适应策略提供依据。此外,该基准测试集可以促进RAG技术在处理历史文本方面的研究进展。
📄 摘要(原文)
Historical archives on weather events are collections of enduring primary source records that offer rich, untapped narratives of how societies have experienced and responded to extreme weather events. These qualitative accounts provide insights into societal vulnerability and resilience that are largely absent from meteorological records, making them valuable for climate scientists to understand societal responses. However, their vast scale, noisy digitized quality, and archaic language make it difficult to transform them into structured knowledge for climate research. To address this challenge, we introduce WeatherArchive-Bench, the first benchmark for evaluating retrieval-augmented generation (RAG) systems on historical weather archives. WeatherArchive-Bench comprises two tasks: WeatherArchive-Retrieval, which measures a system's ability to locate historically relevant passages from over one million archival news segments, and WeatherArchive-Assessment, which evaluates whether Large Language Models (LLMs) can classify societal vulnerability and resilience indicators from extreme weather narratives. Extensive experiments across sparse, dense, and re-ranking retrievers, as well as a diverse set of LLMs, reveal that dense retrievers often fail on historical terminology, while LLMs frequently misinterpret vulnerability and resilience concepts. These findings highlight key limitations in reasoning about complex societal indicators and provide insights for designing more robust climate-focused RAG systems from archival contexts. The constructed dataset and evaluation framework are publicly available at https://anonymous.4open.science/r/WeatherArchive-Bench/.