RAG Makes Guardrails Unsafe? Investigating Robustness of Guardrails under RAG-style Contexts
作者: Yining She, Daniel W. Peterson, Marianne Menglin Liu, Vikas Upadhyay, Mohammad Hossein Chaghazardi, Eunsuk Kang, Dan Roth
分类: cs.CL, cs.AI
发布日期: 2025-10-06
💡 一句话要点
研究表明RAG上下文增强会降低LLM安全防护模型的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 检索增强生成 安全防护模型 上下文鲁棒性 LLM安全
📋 核心要点
- 现有基于LLM的安全防护模型易受数据分布变化影响,在复杂上下文下表现不稳定,存在安全隐患。
- 该研究通过RAG场景,分析上下文信息对安全防护模型判断的影响,揭示了其上下文鲁棒性不足的问题。
- 实验表明,RAG引入的上下文信息会显著改变安全防护模型的判断,现有缓解措施效果有限。
📝 摘要(中文)
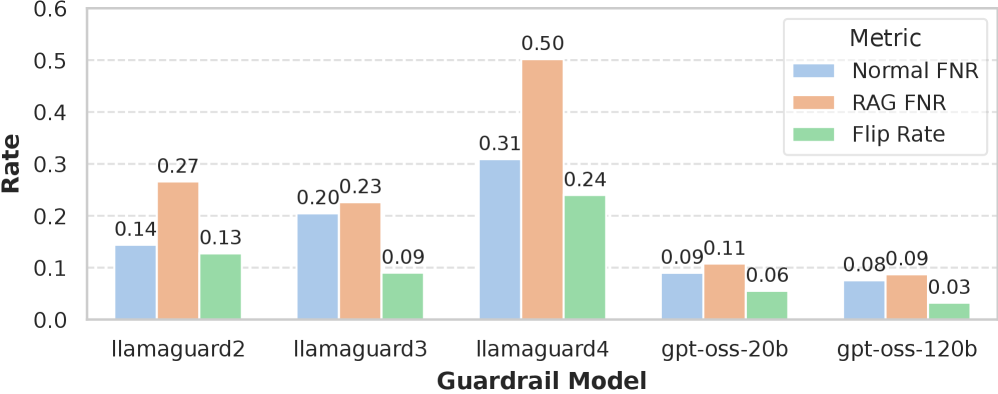
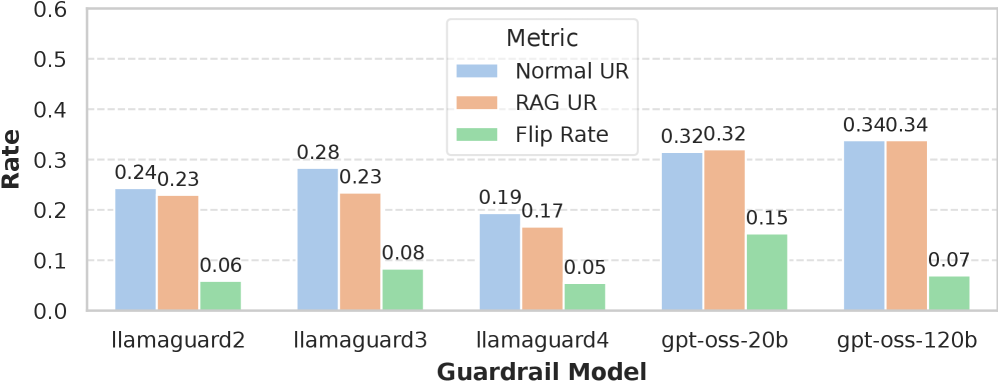
随着大型语言模型(LLM)的日益普及,确保LLM系统的安全性已成为一个紧迫的问题。基于LLM的外部安全防护模型已成为一种流行的解决方案,用于筛选不安全的输入和输出,但它们本身也是经过微调或提示工程的LLM,容易受到数据分布变化的影响。本文以检索增强生成(RAG)为例,研究了基于LLM的安全防护模型在上下文中嵌入额外信息时的鲁棒性。通过对3个Llama Guards和2个GPT-oss模型的系统评估,证实了将良性文档插入安全防护模型的上下文会改变大约11%的输入和8%的输出判断,使其变得不可靠。我们分别分析了增强上下文中每个组成部分的影响:检索到的文档、用户查询和LLM生成的响应。我们测试的两种缓解方法只带来了微小的改进。这些结果暴露了当前安全防护模型中存在的上下文鲁棒性差距,并促使人们开发对检索和查询组合具有鲁棒性的训练和评估协议。
🔬 方法详解
问题定义:论文旨在研究在检索增强生成(RAG)场景下,大型语言模型(LLM)作为安全防护模型时,其鲁棒性问题。现有安全防护模型通常是经过微调或提示工程的LLM,在面对RAG引入的上下文信息时,容易受到干扰,导致判断失误,从而无法有效过滤不安全内容。
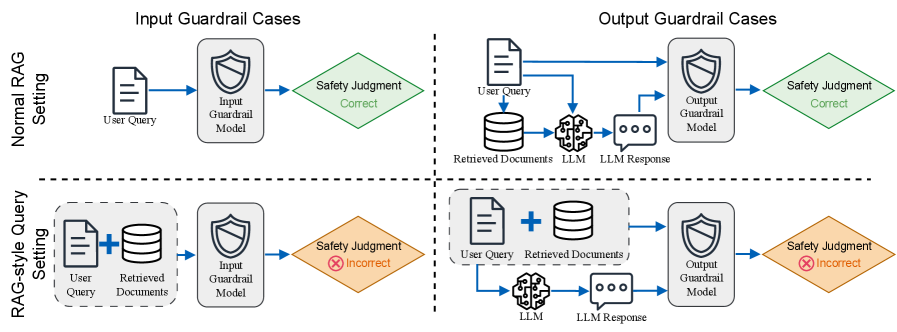
核心思路:核心思路是通过系统性实验,评估在RAG上下文中,安全防护模型对输入和输出的判断是否会受到干扰。具体来说,通过在安全防护模型的上下文中插入良性文档,观察其判断结果是否发生变化,从而评估其上下文鲁棒性。
技术框架:该研究的技术框架主要包括以下几个步骤:1)选择多个开源的安全防护模型(如Llama Guards和GPT-oss模型);2)构建RAG场景,包括用户查询、检索到的文档和LLM生成的响应;3)将检索到的文档插入安全防护模型的上下文;4)评估安全防护模型对输入和输出的判断结果是否发生变化;5)分析不同上下文组成部分(检索到的文档、用户查询、LLM生成的响应)对判断结果的影响;6)测试两种缓解方法,并评估其效果。
关键创新:该研究的关键创新在于揭示了RAG上下文增强对LLM安全防护模型鲁棒性的负面影响。以往的研究主要关注安全防护模型本身的能力,而忽略了RAG等上下文增强技术可能带来的干扰。该研究首次系统性地评估了RAG上下文对安全防护模型的影响,为后续研究提供了重要的参考。
关键设计:在实验设计方面,该研究考虑了多个因素,包括:1)选择了多个具有代表性的开源安全防护模型;2)构建了多种类型的RAG场景,以覆盖不同的应用场景;3)采用了多种评估指标,以全面评估安全防护模型的鲁棒性;4)对不同上下文组成部分的影响进行了细致的分析;5)测试了两种不同的缓解方法,以探索提高安全防护模型鲁棒性的可能性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,将良性文档插入安全防护模型的上下文会改变大约11%的输入和8%的输出判断,表明RAG上下文会显著降低安全防护模型的可靠性。此外,研究还发现,检索到的文档、用户查询和LLM生成的响应都会对安全防护模型的判断产生影响,而测试的两种缓解方法只带来了微小的改进。
🎯 应用场景
该研究成果对提升LLM系统的安全性具有重要意义。通过了解RAG上下文对安全防护模型的影响,可以指导开发更鲁棒的安全防护模型,从而有效过滤不安全内容,保障用户安全。该研究还可应用于其他上下文增强场景,例如知识图谱增强、对话历史增强等,提升LLM在复杂环境下的安全性和可靠性。
📄 摘要(原文)
With the increasing adoption of large language models (LLMs), ensuring the safety of LLM systems has become a pressing concern. External LLM-based guardrail models have emerged as a popular solution to screen unsafe inputs and outputs, but they are themselves fine-tuned or prompt-engineered LLMs that are vulnerable to data distribution shifts. In this paper, taking Retrieval Augmentation Generation (RAG) as a case study, we investigated how robust LLM-based guardrails are against additional information embedded in the context. Through a systematic evaluation of 3 Llama Guards and 2 GPT-oss models, we confirmed that inserting benign documents into the guardrail context alters the judgments of input and output guardrails in around 11% and 8% of cases, making them unreliable. We separately analyzed the effect of each component in the augmented context: retrieved documents, user query, and LLM-generated response. The two mitigation methods we tested only bring minor improvements. These results expose a context-robustness gap in current guardrails and motivate training and evaluation protocols that are robust to retrieval and query composition.