Let it Calm: Exploratory Annealed Decoding for Verifiable Reinforcement Learning
作者: Chenghao Yang, Lin Gui, Chenxiao Yang, Victor Veitch, Lizhu Zhang, Zhuokai Zhao
分类: cs.CL, cs.LG
发布日期: 2025-10-06
备注: Codebase: https://github.com/yangalan123/EAD-RLVR
💡 一句话要点
提出探索性退火解码(EAD),提升可验证强化学习中LLM的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 探索策略 退火解码 可验证奖励 样本效率 推理能力
📋 核心要点
- 现有RLVR方法采用固定温度采样,难以兼顾探索的多样性和训练的稳定性,高温降质,低温受限。
- EAD的核心思想是在序列生成初期进行高强度探索,后期注重利用,通过退火温度平衡探索与利用。
- 实验证明EAD作为即插即用方法,显著提升了RLVR的样本效率,并在多种算法和模型上超越了固定温度采样。
📝 摘要(中文)
可验证奖励强化学习(RLVR)是增强大型语言模型(LLM)推理能力的有效范式,但其成功依赖于有效的探索。理想的探索策略必须应对两个基本挑战:既要保持样本质量,又要确保训练稳定性。标准的固定温度采样虽然简单,但难以平衡这些相互冲突的需求,因为高温会降低样本质量,而低温会限制发现。本文提出了一种更简单有效的策略,即探索性退火解码(EAD),其核心思想是探索对定义序列语义方向的早期token影响最大。EAD通过在生成过程中将采样温度从高到低退火,实现了一种直观的先探索后利用策略。这种动态调度鼓励开始时有意义的高级多样性,然后逐渐降低温度以保持样本质量,并使采样分布接近目标策略,这对于稳定的训练至关重要。实验表明,EAD是一种轻量级的即插即用方法,可显著提高样本效率,并在各种RLVR算法和模型尺寸上始终优于固定温度采样。这项工作表明,将探索与序列生成的自然动态对齐,为提高LLM推理能力提供了一条可靠的途径。
🔬 方法详解
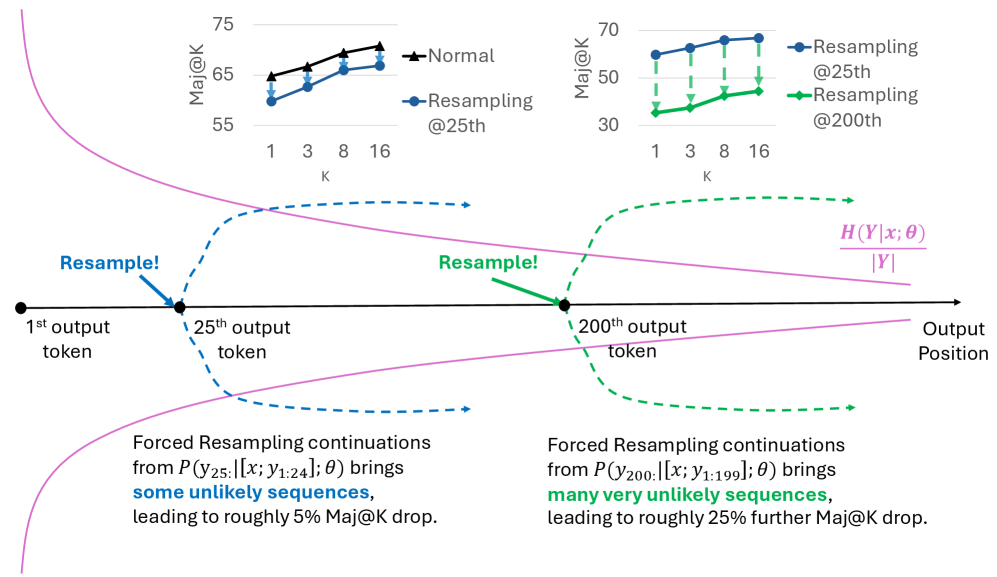
问题定义:论文旨在解决可验证奖励强化学习(RLVR)中,大型语言模型(LLM)探索策略的难题。现有方法,特别是固定温度采样,在探索的多样性和训练的稳定性之间难以取得平衡。高温采样虽然能带来更多样化的样本,但会降低样本质量,导致训练不稳定;而低温采样则限制了探索的范围,可能导致模型陷入局部最优。
核心思路:论文的核心思路是探索性退火解码(EAD),即在序列生成过程中动态调整采样温度。具体来说,在生成的早期阶段使用较高的温度,鼓励模型探索更多可能性,产生更多样化的序列;随着生成的进行,逐渐降低温度,使模型更加关注利用已学到的知识,生成高质量的样本。这种“先探索后利用”的策略旨在兼顾探索的多样性和训练的稳定性。
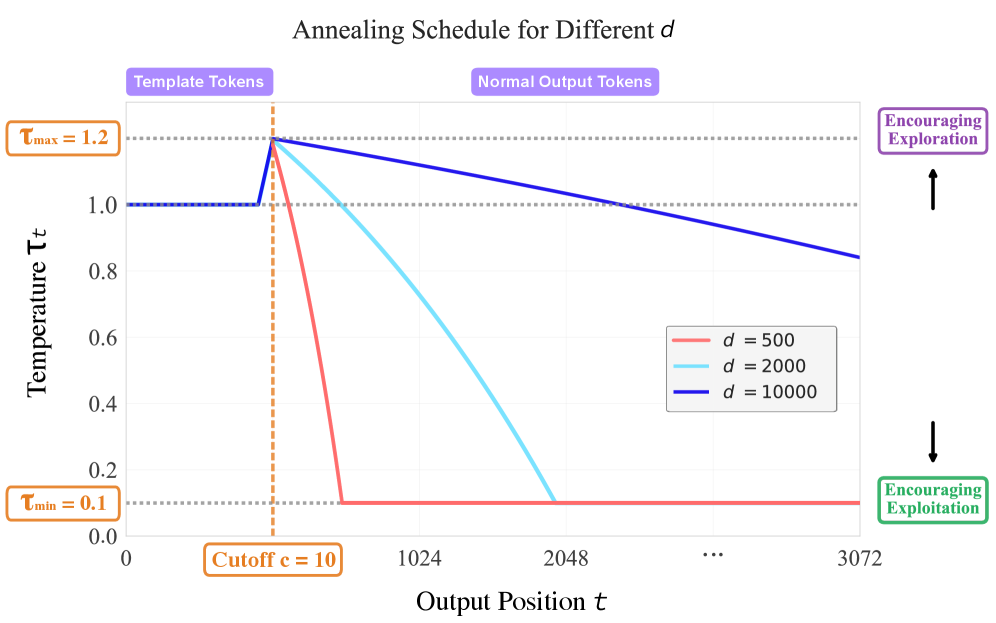
技术框架:EAD的整体框架非常简单,可以作为一个即插即用的模块集成到现有的RLVR算法中。其主要流程是在LLM生成序列的过程中,根据预设的退火策略动态调整采样温度。具体来说,可以采用线性、指数或其他形式的退火函数,将温度从初始的高温逐渐降低到最终的低温。
关键创新:EAD最重要的技术创新点在于其动态调整采样温度的策略。与传统的固定温度采样相比,EAD能够更好地平衡探索与利用,从而提高样本效率和训练稳定性。EAD的核心洞察在于,序列生成早期token的选择对整个序列的语义方向影响最大,因此在早期进行高强度探索能够带来更大的收益。
关键设计:EAD的关键设计在于退火策略的选择。论文中可能探讨了不同的退火函数形式(如线性、指数等)以及退火参数的设置(如初始温度、最终温度、退火步长等)。这些参数的选择会直接影响EAD的性能,需要根据具体的任务和模型进行调整。此外,EAD可以与不同的采样方法(如Top-k采样、Nucleus采样等)结合使用,以进一步提高样本质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EAD在各种RLVR算法和模型尺寸上均优于固定温度采样。EAD能够显著提高样本效率,这意味着在相同的训练资源下,EAD可以使LLM更快地学习到更好的策略。具体的性能提升数据未知,但论文强调了EAD的一致性和显著性。
🎯 应用场景
EAD可应用于各种需要LLM进行推理和决策的任务,例如代码生成、文本摘要、对话系统等。通过提高LLM的探索能力和训练稳定性,EAD可以帮助LLM更好地完成这些任务,并降低训练成本。该方法具有广泛的应用前景,有望推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) is a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs), yet its success hinges on effective exploration. An ideal exploration strategy must navigate two fundamental challenges: it must preserve sample quality while also ensuring training stability. While standard fixed-temperature sampling is simple, it struggles to balance these competing demands, as high temperatures degrade sample quality and low temperatures limit discovery. In this work, we propose a simpler and more effective strategy, Exploratory Annealed Decoding (EAD), grounded in the insight that exploration is most impactful on early tokens which define a sequence's semantic direction. EAD implements an intuitive explore-at-the-beginning, exploit-at-the-end strategy by annealing the sampling temperature from high to low during generation. This dynamic schedule encourages meaningful, high-level diversity at the start, then gradually lowers the temperature to preserve sample quality and keep the sampling distribution close to the target policy, which is essential for stable training. We demonstrate that EAD is a lightweight, plug-and-play method that significantly improves sample efficiency, consistently outperforming fixed-temperature sampling across various RLVR algorithms and model sizes. Our work suggests that aligning exploration with the natural dynamics of sequential generation offers a robust path to improving LLM reasoning.