A novel hallucination classification framework
作者: Maksym Zavhorodnii, Dmytro Dehtiarov, Anna Konovalenko
分类: cs.CL, cs.AI
发布日期: 2025-10-06
备注: 15 pages, 3 figures
💡 一句话要点
提出一种新型幻觉分类框架,用于自动检测大语言模型推理过程中的幻觉。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 提示工程 无监督学习 向量嵌入
📋 核心要点
- 现有大语言模型推理过程中存在幻觉问题,影响模型可靠性,缺乏有效的自动检测方法。
- 通过提示工程系统性地复现各类幻觉,构建幻觉数据集,并利用无监督学习进行分类。
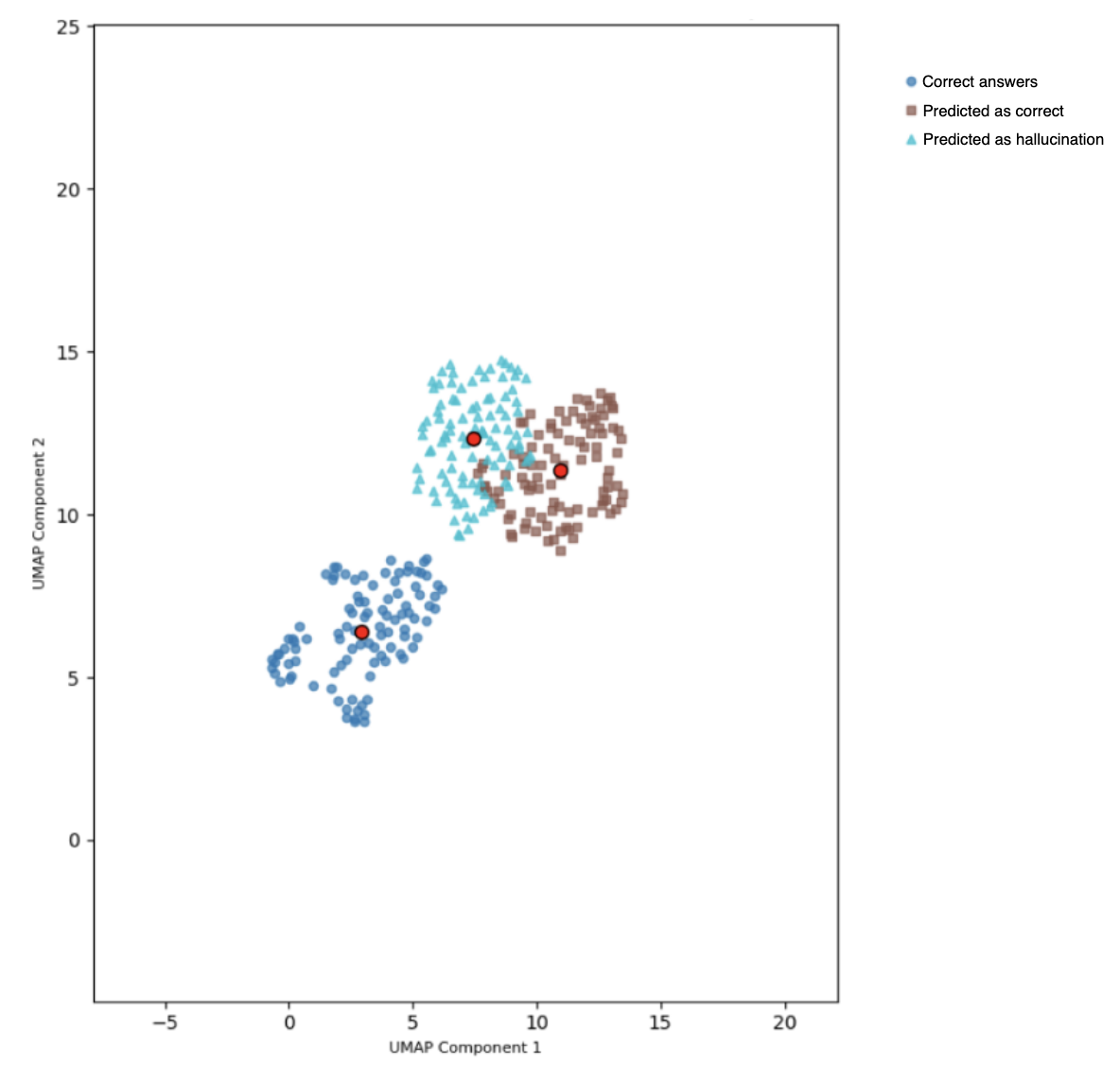
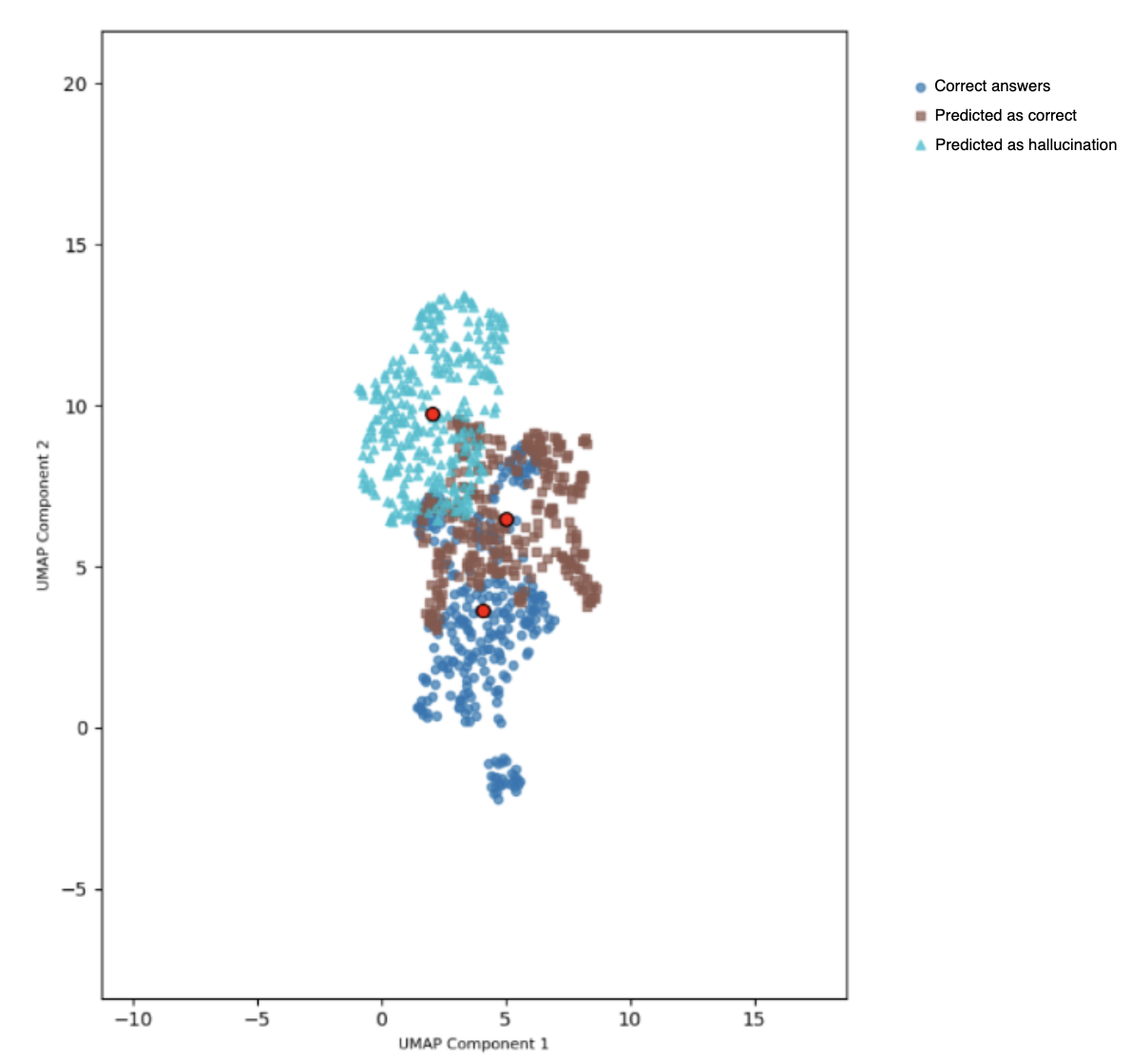
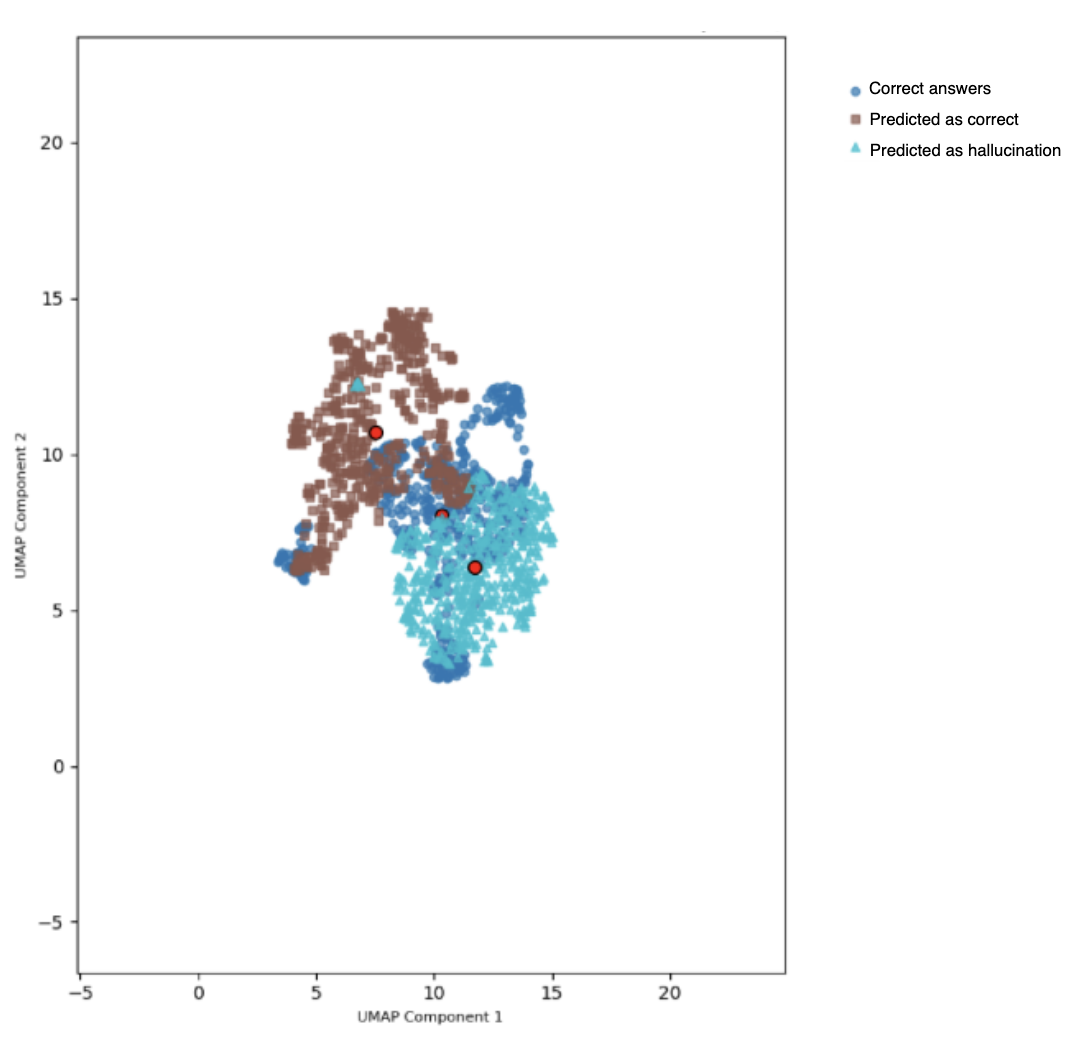
- 实验表明,幻觉的严重程度与其与正确输出的空间距离相关,简单分类器即可有效区分幻觉。
📝 摘要(中文)
本文提出了一种新颖的方法,用于自动检测大语言模型(LLM)推理过程中产生的幻觉。该方法基于系统的分类学,并通过提示工程控制地复现各种幻觉类型。随后,使用嵌入模型将专门构建的幻觉数据集映射到向量空间中,并使用无监督学习技术在幻觉和真实响应的降维表示中进行分析。对类簇中心间距离的定量评估表明,幻觉中信息失真的严重程度与其与正确输出类簇的空间差异之间存在一致的相关性。这些发现提供了理论和经验证据,表明即使是简单的分类算法也可以可靠地区分单个LLM中的幻觉和准确响应,从而为提高模型可靠性提供了一个轻量级但有效的框架。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)在推理过程中产生幻觉的问题。现有的方法通常依赖于人工评估或复杂的外部知识库,效率低且成本高。该论文关注的是如何自动、高效地检测LLM产生的幻觉,从而提高模型的可靠性和可用性。
核心思路:论文的核心思路是通过系统地构建包含各种类型幻觉的数据集,并利用无监督学习的方法,在向量空间中区分幻觉和真实响应。其基本假设是,不同类型的幻觉在语义空间中具有不同的分布,并且幻觉的严重程度与真实响应的距离相关。
技术框架:该框架主要包含以下几个阶段:1) 幻觉类型定义:基于分类学,定义多种类型的幻觉。2) 提示工程:通过精心设计的提示,控制性地生成各种类型的幻觉。3) 数据集构建:收集生成的幻觉和对应的真实响应,构建幻觉数据集。4) 向量嵌入:使用预训练的嵌入模型(如Sentence-BERT)将数据集映射到向量空间。5) 无监督学习:使用聚类算法(如K-means)对向量空间中的数据进行聚类,区分幻觉和真实响应。6) 评估:通过计算类簇中心间距离,评估幻觉的严重程度。
关键创新:该论文的关键创新在于:1) 提出了一种系统性的幻觉分类方法,为幻觉的控制性生成和分析提供了基础。2) 利用无监督学习的方法,在向量空间中自动区分幻觉和真实响应,避免了人工评估和外部知识库的依赖。3) 揭示了幻觉的严重程度与其与真实响应的空间距离之间的相关性,为幻觉检测提供了理论依据。
关键设计:在提示工程方面,论文设计了多种类型的提示,以诱导不同类型的幻觉。在向量嵌入方面,选择了合适的预训练模型,以保证语义信息的准确表达。在无监督学习方面,选择了合适的聚类算法,并对聚类结果进行了定量评估。具体的参数设置和网络结构信息未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够有效地将幻觉与真实响应区分开来。通过定量评估类簇中心间距离,发现幻觉中信息失真的严重程度与其与正确输出类簇的空间差异之间存在一致的相关性。即使使用简单的分类算法,也能在单个LLM中可靠地区分幻觉和准确响应,从而验证了该框架的有效性。
🎯 应用场景
该研究成果可应用于各种需要大语言模型提供可靠信息的场景,例如智能客服、内容生成、知识问答等。通过自动检测和过滤幻觉,可以提高LLM的输出质量,增强用户信任度,并降低因错误信息带来的风险。未来,该方法可以进一步扩展到多语言环境和更复杂的LLM架构中。
📄 摘要(原文)
This work introduces a novel methodology for the automatic detection of hallucinations generated during large language model (LLM) inference. The proposed approach is based on a systematic taxonomy and controlled reproduction of diverse hallucination types through prompt engineering. A dedicated hallucination dataset is subsequently mapped into a vector space using an embedding model and analyzed with unsupervised learning techniques in a reduced-dimensional representation of hallucinations with veridical responses. Quantitative evaluation of inter-centroid distances reveals a consistent correlation between the severity of informational distortion in hallucinations and their spatial divergence from the cluster of correct outputs. These findings provide theoretical and empirical evidence that even simple classification algorithms can reliably distinguish hallucinations from accurate responses within a single LLM, thereby offering a lightweight yet effective framework for improving model reliability.