TeachLM: Post-Training LLMs for Education Using Authentic Learning Data
作者: Janos Perczel, Jin Chow, Dorottya Demszky
分类: cs.CL, cs.AI
发布日期: 2025-10-06
备注: 28 pages, 9 figures
💡 一句话要点
TeachLM:利用真实学习数据后训练LLM,提升教育领域应用效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 教育 后训练 参数高效微调 师生互动 对话生成 个性化学习
📋 核心要点
- 现有LLM在教育领域的应用受限于缺乏高质量的真实学生学习数据,导致教学能力不足。
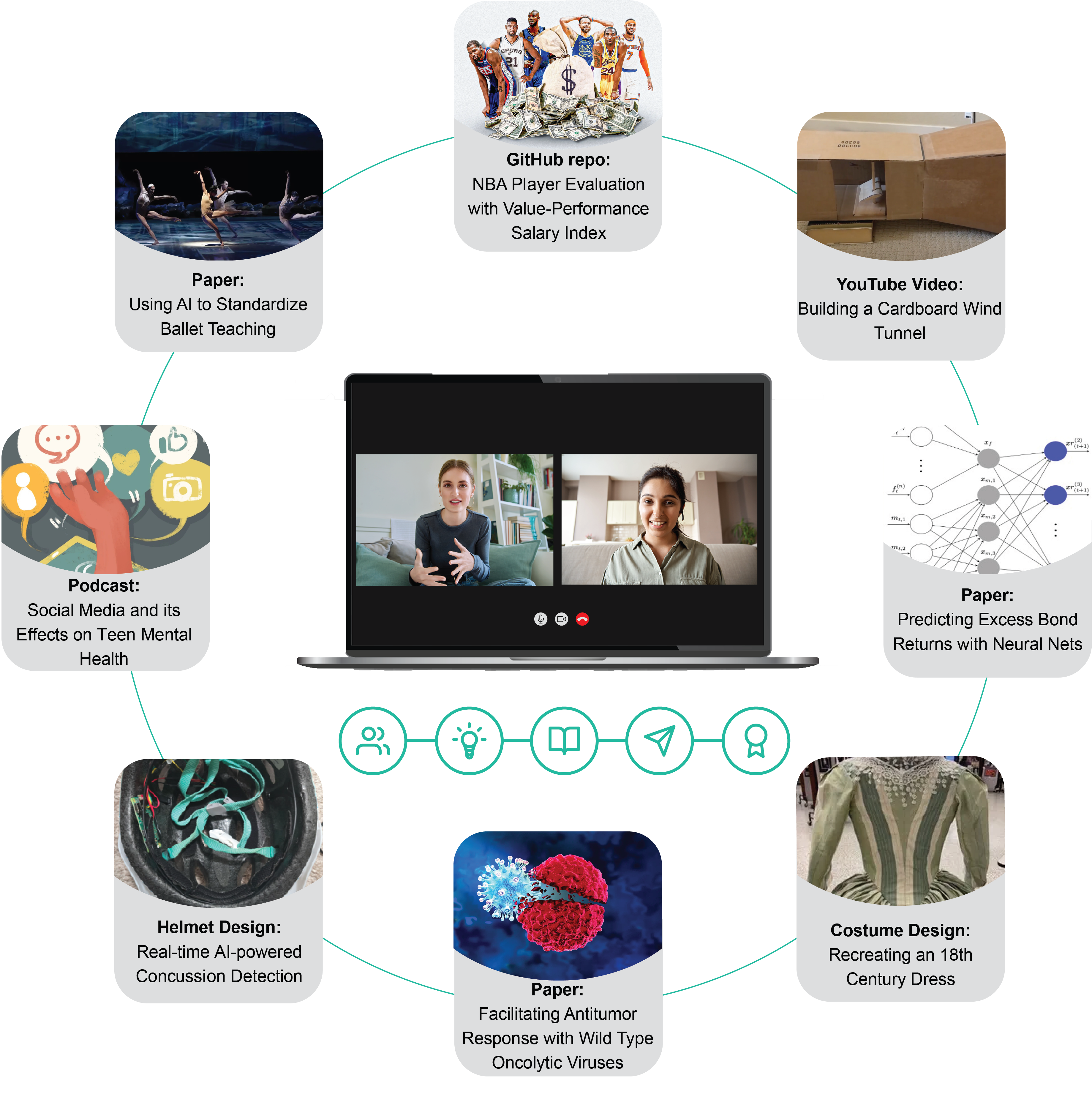
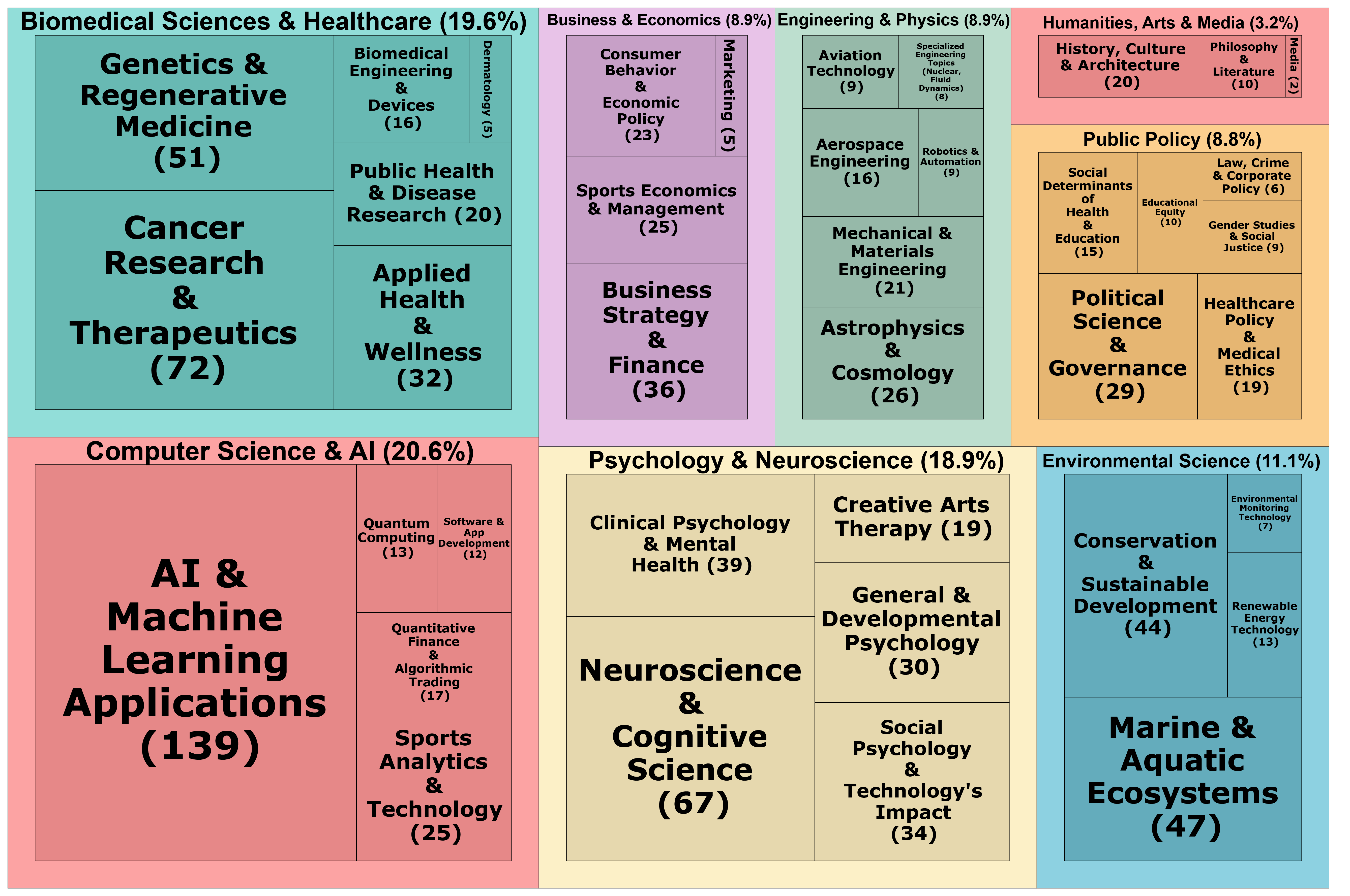
- TeachLM通过在包含10万小时师生互动数据上进行参数高效微调,优化LLM的教学能力。
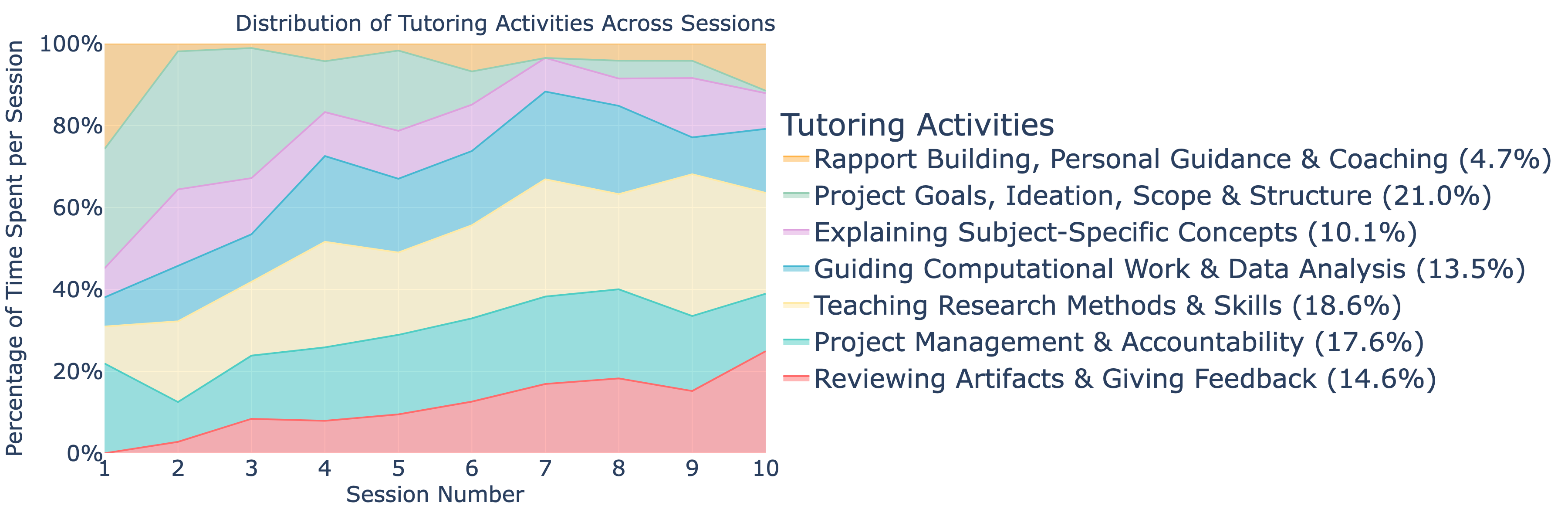
- 实验表明,TeachLM显著提升了对话和教学性能,包括学生发言时间、提问风格和对话轮次。
📝 摘要(中文)
大型语言模型(LLM)在教育领域应用的潜力受到其教学能力的限制。一个主要问题是缺乏反映真实学生学习情况的高质量训练数据。提示工程作为一种临时解决方案,但其在基于规则的自然语言中编码复杂教学策略的能力受到固有限制。为了解决这个问题,我们引入了TeachLM——一种通过对最先进的模型进行参数高效微调来优化教学的LLM。TeachLM在一个由Polygence维护的包含10万小时一对一纵向师生互动的数据集上进行训练,该数据集经过严格的匿名化处理以保护隐私。我们使用参数高效微调来开发一个真实的学⽣模型,该模型能够⽣成⾼保真度的合成师⽣对话。在此基础上,我们提出了一种新颖的多轮评估协议,该协议利用合成对话生成来提供对LLM对话能力的快速、可扩展和可重复的评估。我们的评估表明,在真实的学习数据上进行微调可以显著提高对话和教学性能——学生发言时间翻倍,提问风格得到改善,对话轮次增加50%,以及更个性化的教学。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在教育领域应用时,由于缺乏高质量的真实学生学习数据而导致的教学能力不足的问题。现有方法,如提示工程,虽然可以一定程度上缓解这个问题,但其在编码复杂教学策略方面的能力有限,无法充分模拟真实的师生互动。
核心思路:论文的核心思路是利用真实的师生互动数据对LLM进行后训练(post-training),使其能够更好地理解和模拟学生的学习过程,从而提升其教学能力。通过参数高效微调,可以在保持模型原有能力的同时,使其适应教育领域的特定需求。
技术框架:TeachLM的整体框架包括以下几个主要阶段:1) 数据收集与预处理:收集Polygence平台上的师生互动数据,并进行严格的匿名化处理。2) 模型选择与微调:选择先进的LLM作为基础模型,并使用参数高效微调技术(具体方法未知)在处理后的数据上进行训练。3) 对话生成与评估:利用微调后的模型生成合成的师生对话,并设计多轮评估协议来评估模型的对话和教学能力。
关键创新:论文的关键创新在于:1) 利用大规模的真实师生互动数据进行LLM的后训练,这与以往主要依赖通用语料或人工设计的教学语料的方法不同。2) 提出了一种基于合成对话生成的多轮评估协议,可以快速、可扩展地评估LLM的对话能力,而无需大量的人工标注。3) 使用参数高效微调,在保证模型效果的同时,降低了训练成本。
关键设计:论文中关于参数设置、损失函数、网络结构等技术细节描述较少,具体实现未知。但可以推测,参数高效微调可能采用了诸如LoRA、Adapter等技术,以减少需要训练的参数量。损失函数可能包括语言模型损失和一些针对教学场景的定制化损失函数(具体形式未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在真实的学习数据上进行微调后,TeachLM的对话和教学性能显著提升。具体表现为:学生发言时间翻倍,提问风格得到改善,对话轮次增加50%,以及更个性化的教学。这些数据表明,TeachLM能够更好地模拟真实的师生互动,并为学生提供更有效的学习支持。
🎯 应用场景
TeachLM的研究成果可应用于智能辅导系统、个性化学习平台、教育机器人等领域。通过模拟真实的师生互动,TeachLM可以为学生提供更加个性化、高效的学习体验。此外,该研究提出的评估方法也可以用于评估其他教育类LLM的性能,推动教育领域AI技术的发展。
📄 摘要(原文)
The promise of generative AI to revolutionize education is constrained by the pedagogical limits of large language models (LLMs). A major issue is the lack of access to high-quality training data that reflect the learning of actual students. Prompt engineering has emerged as a stopgap, but the ability of prompts to encode complex pedagogical strategies in rule-based natural language is inherently limited. To address this gap we introduce TeachLM - an LLM optimized for teaching through parameter-efficient fine-tuning of state-of-the-art models. TeachLM is trained on a dataset comprised of 100,000 hours of one-on-one, longitudinal student-tutor interactions maintained by Polygence, which underwent a rigorous anonymization process to protect privacy. We use parameter-efficient fine-tuning to develop an authentic student model that enables the generation of high-fidelity synthetic student-tutor dialogues. Building on this capability, we propose a novel multi-turn evaluation protocol that leverages synthetic dialogue generation to provide fast, scalable, and reproducible assessments of the dialogical capabilities of LLMs. Our evaluations demonstrate that fine-tuning on authentic learning data significantly improves conversational and pedagogical performance - doubling student talk time, improving questioning style, increasing dialogue turns by 50%, and greater personalization of instruction.