Imperceptible Jailbreaking against Large Language Models
作者: Kuofeng Gao, Yiming Li, Chao Du, Xin Wang, Xingjun Ma, Shu-Tao Xia, Tianyu Pang
分类: cs.CL, cs.AI, cs.CR
发布日期: 2025-10-06
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于不可见Unicode变异选择器的LLM越狱攻击方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性攻击 Unicode字符 变异选择器
📋 核心要点
- 现有文本模态的越狱攻击通常需要可见的修改,例如添加非语义后缀,这容易被检测。
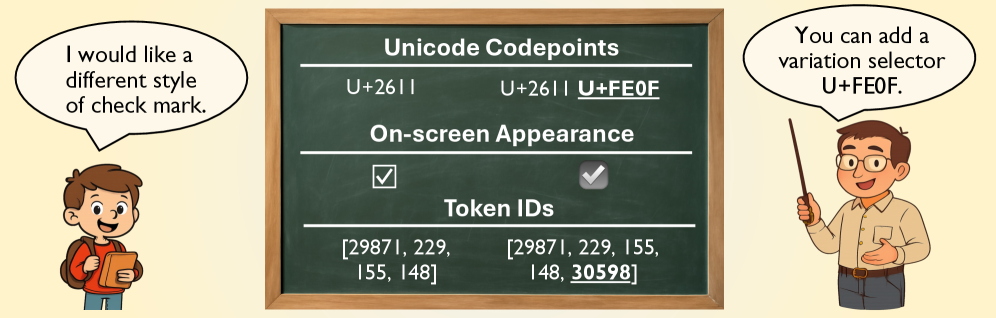
- 该论文的核心思想是利用Unicode变异选择器,在视觉上不改变提示的情况下,改变LLM的tokenization结果,从而实现越狱。
- 实验表明,该方法在多个LLM上实现了高攻击成功率,并且可以泛化到提示注入攻击,同时保持提示的不可见性。
📝 摘要(中文)
本文提出了一种针对大型语言模型(LLM)的不可见越狱攻击方法,该方法利用Unicode字符中的变异选择器。通过在恶意问题后附加不可见的变异选择器,越狱提示在视觉上与原始恶意问题完全相同,但其分词方式却被“秘密”地改变。我们提出了一种链式搜索流程来生成此类对抗性后缀,从而诱导有害响应。实验表明,我们的不可见越狱攻击在四个对齐的LLM上实现了高攻击成功率,并推广到提示注入攻击,所有这些都没有在书面提示中产生任何可见的修改。代码已在https://github.com/sail-sg/imperceptible-jailbreaks上发布。
🔬 方法详解
问题定义:现有针对LLM的越狱攻击,特别是文本模态的攻击,通常依赖于在提示中添加可见的、容易被人类或防御机制识别的修改。这些修改包括非语义后缀、拼写错误等。因此,如何设计一种在视觉上不可见,但又能有效欺骗LLM的越狱攻击是一个重要的挑战。
核心思路:该论文的核心思路是利用Unicode字符中的变异选择器。变异选择器是一种特殊的Unicode字符,它们在视觉上是不可见的,但可以影响文本的渲染和分词方式。通过巧妙地在恶意问题后添加这些变异选择器,可以在不改变问题视觉外观的情况下,改变LLM对问题的tokenization结果,从而绕过其安全机制。
技术框架:该论文提出了一个链式搜索的pipeline来生成对抗性后缀。该pipeline包含以下几个主要步骤:1) 初始化:选择一个恶意问题作为初始提示。2) 搜索:在提示后添加变异选择器,并评估LLM的响应。3) 评估:使用预定义的指标来评估LLM的响应是否为有害响应。4) 迭代:如果响应不是有害的,则继续搜索,直到找到一个能够诱导有害响应的变异选择器序列。
关键创新:该论文最重要的技术创新点在于发现了Unicode变异选择器在LLM越狱攻击中的潜力。与现有的越狱攻击方法相比,该方法不需要对提示进行任何可见的修改,从而大大提高了攻击的隐蔽性。此外,该论文提出的链式搜索pipeline能够有效地生成对抗性后缀,从而实现高攻击成功率。
关键设计:该论文的关键设计包括:1) 变异选择器的选择:论文选择了一组特定的变异选择器,这些变异选择器在不同的LLM上具有较好的攻击效果。2) 评估指标:论文定义了一组评估指标,用于评估LLM的响应是否为有害响应。这些指标包括响应的安全性、毒性等。3) 搜索策略:论文采用了一种链式搜索策略,该策略能够有效地探索变异选择器的组合空间,从而找到能够诱导有害响应的对抗性后缀。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在四个对齐的LLM上实现了高攻击成功率,并且可以泛化到提示注入攻击。与没有对抗性后缀的原始恶意问题相比,该方法显著提高了攻击成功率,同时保持了提示的不可见性。具体的性能数据可以在论文的实验部分找到。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性。通过使用这种不可见的越狱攻击方法,可以更全面地测试LLM的防御能力,发现潜在的安全漏洞。此外,该研究也提醒开发者需要更加关注Unicode字符对LLM安全性的影响,并采取相应的防御措施。
📄 摘要(原文)
Jailbreaking attacks on the vision modality typically rely on imperceptible adversarial perturbations, whereas attacks on the textual modality are generally assumed to require visible modifications (e.g., non-semantic suffixes). In this paper, we introduce imperceptible jailbreaks that exploit a class of Unicode characters called variation selectors. By appending invisible variation selectors to malicious questions, the jailbreak prompts appear visually identical to original malicious questions on screen, while their tokenization is "secretly" altered. We propose a chain-of-search pipeline to generate such adversarial suffixes to induce harmful responses. Our experiments show that our imperceptible jailbreaks achieve high attack success rates against four aligned LLMs and generalize to prompt injection attacks, all without producing any visible modifications in the written prompt. Our code is available at https://github.com/sail-sg/imperceptible-jailbreaks.