The Geometry of Truth: Layer-wise Semantic Dynamics for Hallucination Detection in Large Language Models
作者: Amir Hameed Mir
分类: cs.CL, cs.AI, cs.IT, cs.LG, cs.NE
发布日期: 2025-10-06
备注: Comments: 14 pages, 14 figures, 5 tables. Code available at: https://github.com/sirraya-tech/Sirraya_LSD_Code
💡 一句话要点
提出Layer-wise Semantic Dynamics (LSD)用于检测大语言模型中的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 语义动态 对比学习 Transformer 事实一致性 模型可解释性
📋 核心要点
- 现有LLM幻觉检测方法依赖多次采样或外部知识,效率低且成本高,限制了实际应用。
- LSD通过分析Transformer层间隐藏状态语义变化,无需外部信息即可检测幻觉,提升效率。
- 实验表明,LSD在幻觉检测任务上显著优于现有方法,且速度提升5-20倍,兼顾精度与效率。
📝 摘要(中文)
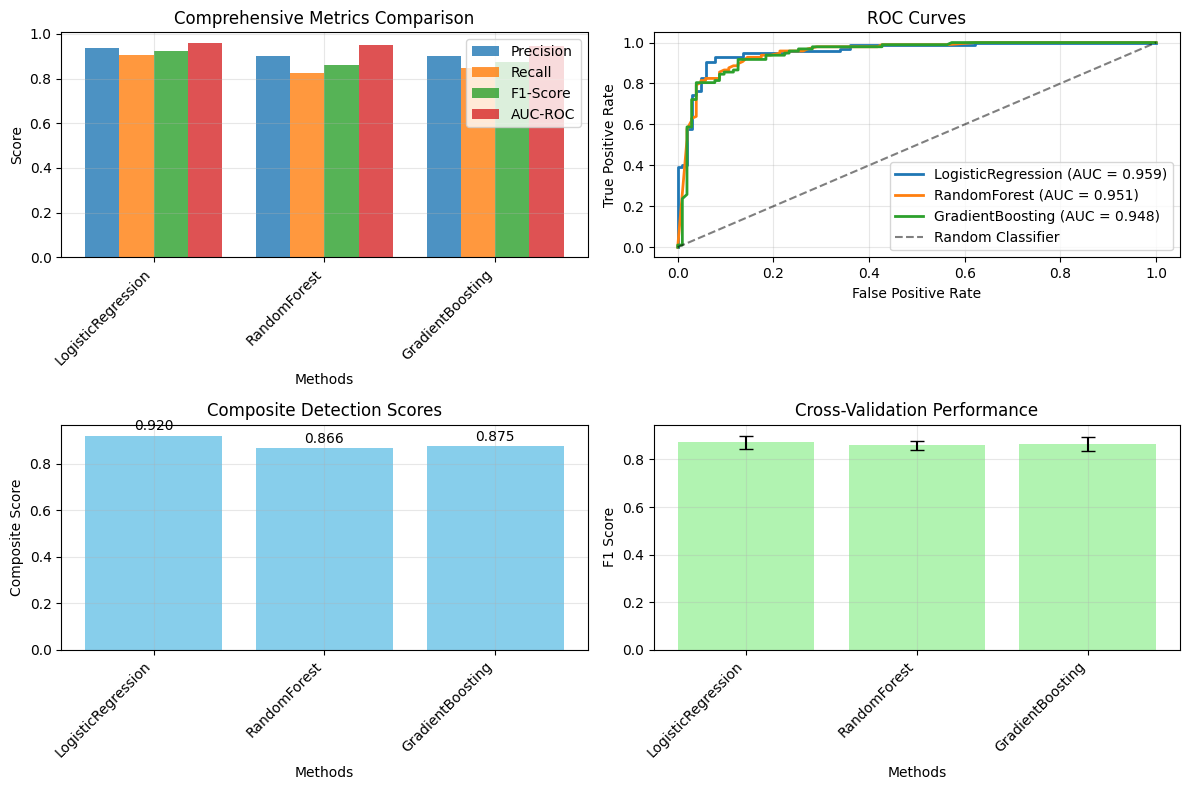
大型语言模型(LLM)经常生成流畅但事实不正确的陈述,这种现象被称为幻觉,在高风险领域构成严重威胁。本文提出了一种用于幻觉检测的几何框架Layer-wise Semantic Dynamics (LSD),该框架分析了Transformer层中隐藏状态语义的演变。与依赖于多次采样或外部验证源的先前方法不同,LSD在模型表示空间内运行。通过基于边际的对比学习,LSD将隐藏激活与来自事实编码器的ground-truth嵌入对齐,揭示了语义轨迹的明显分离:事实性响应保持稳定的对齐,而幻觉表现出明显的跨深度语义漂移。在TruthfulQA和合成事实-幻觉数据集上的评估表明,LSD实现了0.92的F1分数、0.96的AUROC和0.89的聚类准确率,优于SelfCheckGPT和Semantic Entropy基线,同时只需要一次前向传递。这种效率比基于采样的方法提高了5-20倍的速度,而没有牺牲精度或可解释性。LSD为实时幻觉监控提供了一种可扩展的、模型无关的机制,并为大型语言模型中事实一致性的几何特性提供了新的见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的幻觉问题,即模型生成流畅但事实不正确的陈述。现有方法,如SelfCheckGPT和Semantic Entropy,通常需要多次采样或依赖外部知识源进行验证,计算成本高昂,效率低下,难以满足实时应用的需求。这些方法也缺乏对模型内部表示的深入理解,难以解释幻觉产生的原因。
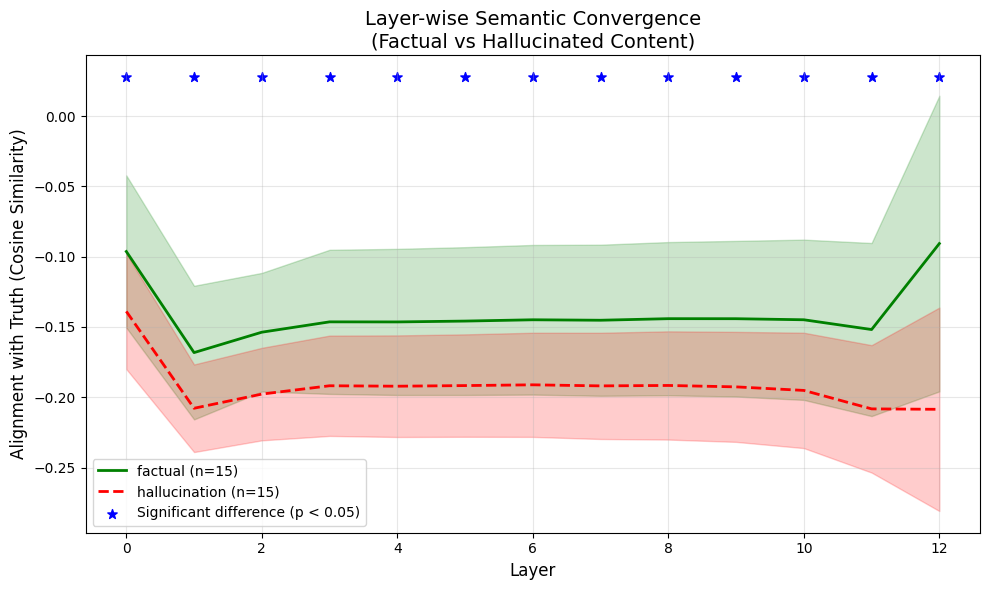
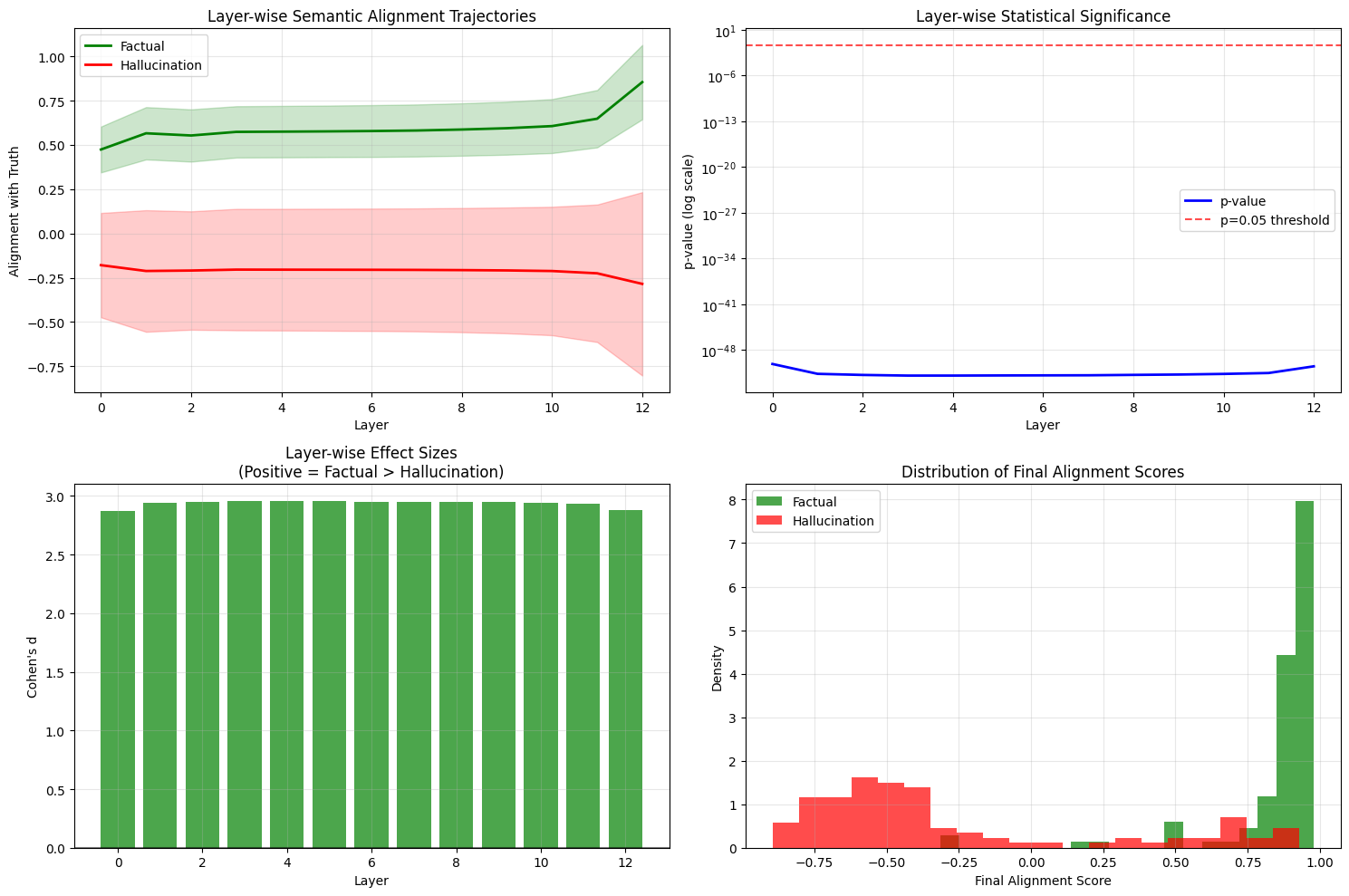
核心思路:论文的核心思路是利用Transformer模型层间隐藏状态的语义动态变化来区分事实性响应和幻觉。作者假设,事实性响应在不同层之间的语义表示应该保持相对稳定,而幻觉则会表现出显著的语义漂移。通过分析这种语义漂移,可以有效地检测幻觉。这种方法无需外部信息,仅依赖模型内部的表示空间,因此更加高效和可扩展。
技术框架:LSD框架主要包含以下几个阶段:1) 获取LLM各层的隐藏状态激活值;2) 使用事实编码器(例如,预训练的BERT模型)生成ground-truth嵌入;3) 使用基于边际的对比学习方法,将LLM的隐藏状态激活值与ground-truth嵌入对齐;4) 计算各层之间的语义漂移,并根据漂移程度判断是否存在幻觉。整体流程简单高效,易于实现。
关键创新:LSD的关键创新在于其利用了Transformer模型层间的语义动态变化来检测幻觉。与现有方法不同,LSD无需多次采样或外部知识,而是直接在模型的表示空间内进行分析。这种方法不仅提高了效率,还提供了对模型内部运作机制的更深入理解。此外,LSD采用的基于边际的对比学习方法能够有效地对齐隐藏状态和ground-truth嵌入,从而提高了幻觉检测的准确性。
关键设计:LSD的关键设计包括:1) 使用预训练的BERT模型作为事实编码器,生成高质量的ground-truth嵌入;2) 采用基于边际的对比损失函数,鼓励事实性响应的隐藏状态与ground-truth嵌入之间的距离最小化,而幻觉的距离最大化;3) 通过计算相邻层之间隐藏状态的余弦相似度来衡量语义漂移;4) 使用聚类算法(如K-means)将语义轨迹分为事实性和幻觉两类。具体的参数设置和超参数选择需要根据具体的LLM和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
LSD在TruthfulQA和合成数据集上取得了显著的性能提升,F1分数达到0.92,AUROC达到0.96,聚类准确率达到0.89,超越了SelfCheckGPT和Semantic Entropy等基线方法。更重要的是,LSD仅需一次前向传递,速度比基于采样的方法提高了5-20倍,在保证精度的同时,显著提升了效率。
🎯 应用场景
LSD可应用于各种需要高可靠性的LLM应用场景,如医疗诊断、金融分析、法律咨询等。通过实时监控LLM的输出,LSD可以有效降低幻觉带来的风险,提高决策的准确性和可靠性。未来,LSD可以进一步扩展到其他类型的生成模型,并与其他幻觉缓解技术相结合,构建更强大的安全保障体系。
📄 摘要(原文)
Large Language Models (LLMs) often produce fluent yet factually incorrect statements-a phenomenon known as hallucination-posing serious risks in high-stakes domains. We present Layer-wise Semantic Dynamics (LSD), a geometric framework for hallucination detection that analyzes the evolution of hidden-state semantics across transformer layers. Unlike prior methods that rely on multiple sampling passes or external verification sources, LSD operates intrinsically within the model's representational space. Using margin-based contrastive learning, LSD aligns hidden activations with ground-truth embeddings derived from a factual encoder, revealing a distinct separation in semantic trajectories: factual responses preserve stable alignment, while hallucinations exhibit pronounced semantic drift across depth. Evaluated on the TruthfulQA and synthetic factual-hallucination datasets, LSD achieves an F1-score of 0.92, AUROC of 0.96, and clustering accuracy of 0.89, outperforming SelfCheckGPT and Semantic Entropy baselines while requiring only a single forward pass. This efficiency yields a 5-20x speedup over sampling-based methods without sacrificing precision or interpretability. LSD offers a scalable, model-agnostic mechanism for real-time hallucination monitoring and provides new insights into the geometry of factual consistency within large language models.