Do LLMs Align with My Task? Evaluating Text-to-SQL via Dataset Alignment
作者: Davood Rafiei, Morgan Lindsay Heisler, Weiwei Zhang, Mohammadreza Pourreza, Yong Zhang
分类: cs.CL, cs.AI, cs.DB
发布日期: 2025-10-06
💡 一句话要点
通过数据集对齐评估LLM在Text-to-SQL任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大型语言模型 数据集对齐 监督式微调 跨领域泛化
📋 核心要点
- 现有方法在跨领域NL2SQL任务中,由于训练数据与目标数据结构差异,导致LLM泛化能力受限。
- 论文提出通过比较训练集、目标数据和模型预测的SQL结构特征分布,评估数据集对齐程度。
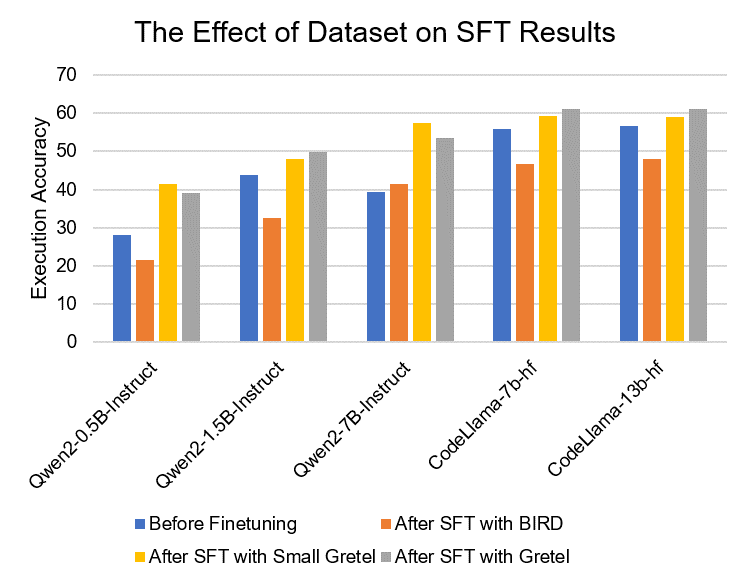
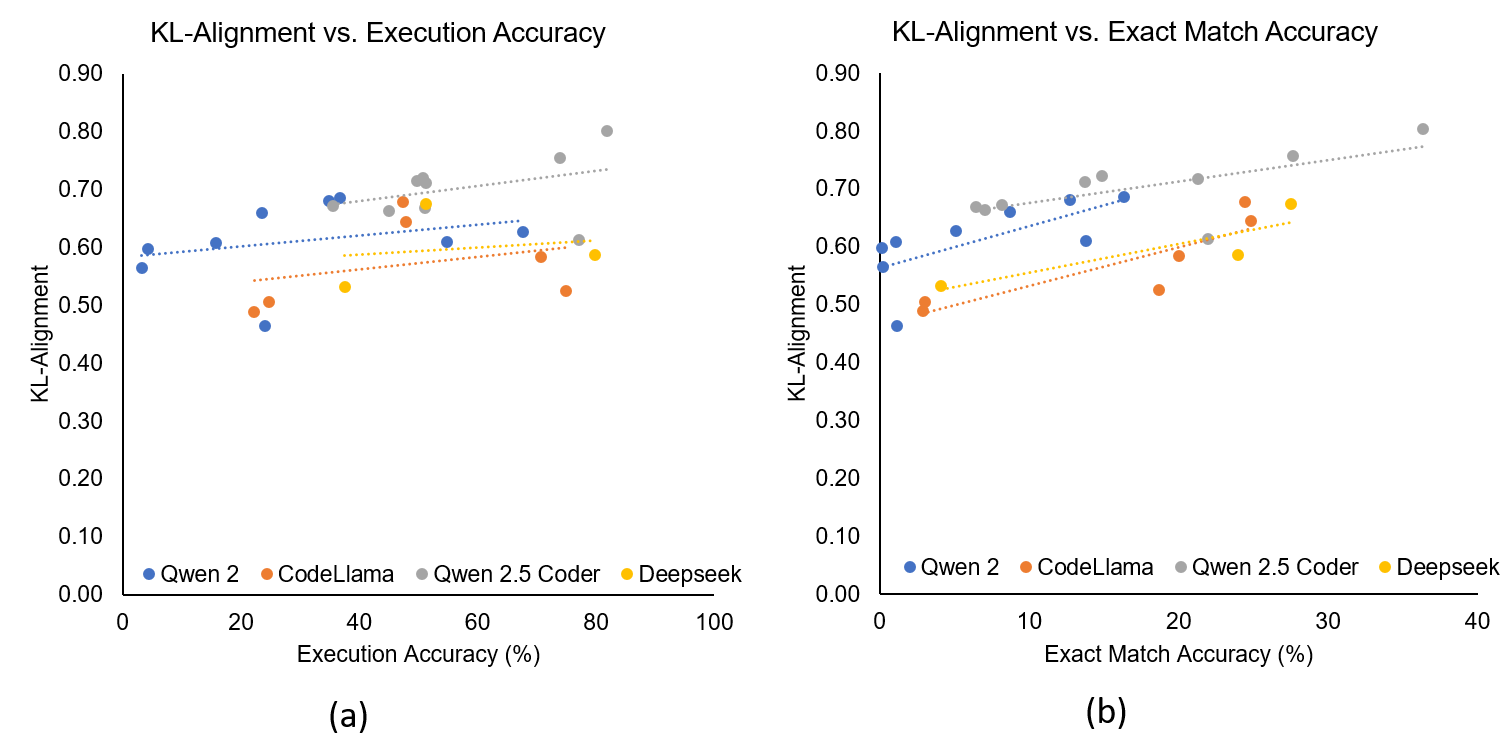
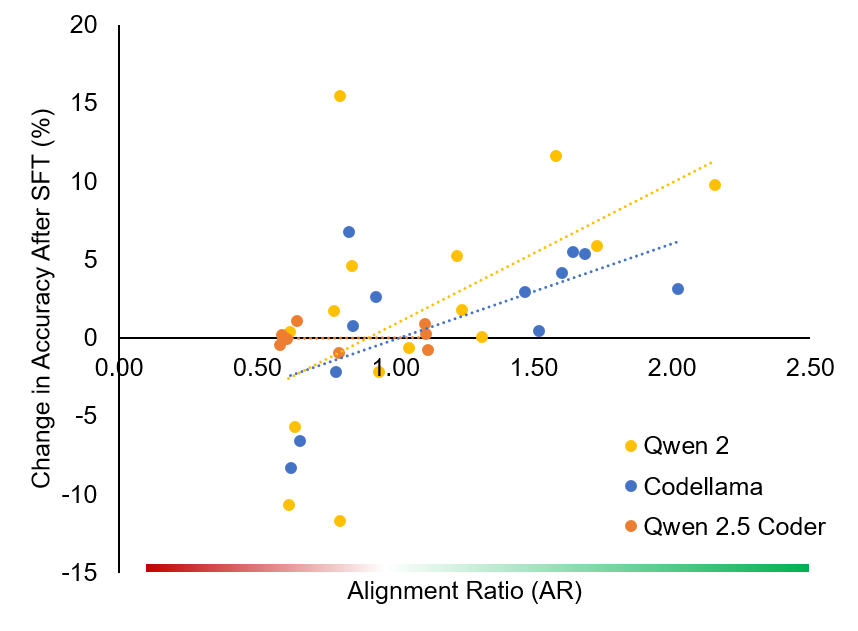
- 实验表明,结构对齐程度是微调效果的强预测指标,高对齐度带来显著性能提升。
📝 摘要(中文)
监督式微调(SFT)是使大型语言模型(LLM)适应下游任务的有效方法。然而,训练数据的差异性会阻碍模型在不同领域之间的泛化能力。本文研究了自然语言到SQL(NL2SQL或text to SQL)任务的数据集对齐问题,考察了SFT训练数据与目标查询的结构特征的匹配程度,以及这种对齐如何影响模型性能。我们假设可以通过比较训练集、目标数据和SFT之前模型的预测中结构化SQL特征的分布来准确估计对齐程度。通过在三个大型跨领域NL2SQL基准测试和多个模型系列上的综合实验,我们表明结构对齐是微调成功的一个强有力的预测指标。当对齐程度高时,SFT在准确性和SQL生成质量方面会产生显著的提升;当对齐程度低时,改进很小或没有改进。这些发现突出了在NL2SQL任务中,对齐感知的数据选择对于有效的微调和泛化至关重要。
🔬 方法详解
问题定义:本文旨在解决在Text-to-SQL任务中,由于训练数据与目标数据在SQL结构上的不对齐,导致LLM微调后泛化能力不足的问题。现有方法通常忽略了这种结构差异,导致微调效果不稳定,有时甚至无法提升性能。
核心思路:论文的核心思路是通过量化训练数据、目标数据和模型预测结果在SQL结构上的相似度,来评估数据集的对齐程度。如果训练数据在SQL结构上与目标数据高度对齐,那么LLM在微调后更容易泛化到目标领域。反之,如果对齐程度低,则微调效果可能不佳。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 提取训练集、目标数据和预训练LLM预测结果的SQL结构特征;2) 计算这些特征分布之间的相似度,作为对齐程度的度量;3) 使用SFT对LLM进行微调;4) 评估微调后的LLM在目标数据上的性能;5) 分析对齐程度与微调性能之间的关系。
关键创新:论文的关键创新在于提出了基于SQL结构特征分布相似度的对齐度量方法。这种方法能够有效地捕捉训练数据与目标数据在SQL结构上的差异,从而预测微调的效果。与现有方法相比,该方法更加关注数据本身的结构特征,而不是仅仅依赖于模型的性能指标。
关键设计:论文的关键设计包括:1) SQL结构特征的选择,例如SQL查询的类型、表的数量、连接操作的数量等;2) 特征分布相似度的计算方法,例如KL散度、余弦相似度等;3) 微调策略的选择,例如学习率、batch size等。论文可能还探讨了不同对齐度量方法和微调策略对最终性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结构对齐程度与微调后的模型性能之间存在显著的正相关关系。在高对齐度的情况下,SFT能够显著提高模型的准确性和SQL生成质量。在三个大型跨领域NL2SQL基准测试中,该方法能够有效地预测微调的效果,并指导数据选择,从而提升模型性能。
🎯 应用场景
该研究成果可应用于各种需要跨领域Text-to-SQL的应用场景,例如智能客服、数据分析平台等。通过评估数据集的对齐程度,可以选择更合适的训练数据,从而提高LLM在目标领域的性能和泛化能力。该研究还有助于开发更智能、更可靠的数据库查询系统。
📄 摘要(原文)
Supervised Fine-Tuning (SFT) is an effective method for adapting Large Language Models (LLMs) on downstream tasks. However, variability in training data can hinder a model's ability to generalize across domains. This paper studies the problem of dataset alignment for Natural Language to SQL (NL2SQL or text to SQL), examining how well SFT training data matches the structural characteristics of target queries and how this alignment impacts model performance. We hypothesize that alignment can be accurately estimated by comparing the distributions of structural SQL features across the training set, target data, and the model's predictions prior to SFT. Through comprehensive experiments on three large cross-domain NL2SQL benchmarks and multiple model families, we show that structural alignment is a strong predictor of fine-tuning success. When alignment is high, SFT yields substantial gains in accuracy and SQL generation quality; when alignment is low, improvements are marginal or absent. These findings highlight the importance of alignment-aware data selection for effective fine-tuning and generalization in NL2SQL tasks.