Detecting Distillation Data from Reasoning Models
作者: Hengxiang Zhang, Hyeong Kyu Choi, Sharon Li, Hongxin Wei
分类: cs.CL, cs.AI
发布日期: 2025-10-06 (更新: 2025-10-15)
💡 一句话要点
提出Token Probability Deviation方法,用于检测推理模型蒸馏数据中的污染样本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蒸馏数据检测 基准污染 大型语言模型 Token概率 推理模型 数据安全 模型评估
📋 核心要点
- 推理蒸馏提升模型能力,但可能导致基准污染,评估数据泄露影响模型性能。
- 提出Token Probability Deviation (TBD)方法,利用生成token的概率偏差检测污染数据。
- 实验表明TBD方法有效,在S1数据集上AUC达到0.918,TPR@1% FPR达到0.470。
📝 摘要(中文)
推理蒸馏已成为增强大型语言模型推理能力的有效范例。然而,推理蒸馏可能无意中导致基准污染,即蒸馏数据集中包含的评估数据会虚增蒸馏模型的性能指标。本文正式定义了蒸馏数据检测任务,该任务因蒸馏数据的部分可用性而具有独特的挑战性。然后,我们提出了一种新颖有效的方法,即Token Probability Deviation (TBD),它利用生成输出token的概率模式。我们的方法基于这样的分析:蒸馏模型倾向于为见过的(seen)问题生成近乎确定的token,而为未见过的(unseen)问题生成更多低概率的token。TBD背后的关键思想是量化生成token的概率与高参考概率的偏差程度。实际上,我们的方法通过为见过的(seen)问题产生比未见过的(unseen)问题更低的分数,从而实现了有竞争力的检测性能。大量实验表明了我们方法的有效性,在S1数据集上实现了0.918的AUC和0.470的TPR@1% FPR。
🔬 方法详解
问题定义:论文旨在解决推理模型蒸馏过程中,由于蒸馏数据集包含评估数据而导致的基准污染问题。现有方法难以有效检测这些污染数据,因为蒸馏数据集通常不完全公开,只能部分访问。这使得传统的重复数据删除方法失效,需要新的检测方法。
核心思路:论文的核心思路是利用蒸馏模型在处理“见过”和“未见过”的问题时,生成token的概率分布差异。蒸馏模型对于见过的问题,倾向于生成高概率的、近乎确定的token;而对于未见过的问题,则会生成更多低概率的token。通过量化这种概率偏差,可以区分蒸馏数据和非蒸馏数据。
技术框架:TBD方法的核心在于计算token概率与参考概率之间的偏差。具体流程如下:1) 使用蒸馏模型生成问题对应的答案token序列。2) 获取每个token的生成概率。3) 选择一个高参考概率值(例如0.99)。4) 计算每个token的概率与参考概率之间的偏差,例如使用负对数概率。5) 将所有token的偏差值进行聚合,得到最终的TBD分数。TBD分数越低,表示问题越可能出现在蒸馏数据集中。
关键创新:TBD方法的关键创新在于利用了蒸馏模型生成token的概率分布特性来检测蒸馏数据。与传统的基于文本相似度的检测方法不同,TBD方法不需要访问完整的蒸馏数据集,只需要通过分析模型的输出概率即可进行检测。这种方法更适用于蒸馏数据集部分可用的场景。
关键设计:TBD方法的关键设计包括:1) 参考概率的选择:参考概率需要足够高,以区分高概率token和低概率token。2) 偏差度量方式:可以使用负对数概率或其他合适的度量方式来量化概率偏差。3) 偏差聚合方式:可以将所有token的偏差值进行平均、求和或其他方式进行聚合,得到最终的TBD分数。论文中具体使用了哪些参数设置未知。
🖼️ 关键图片


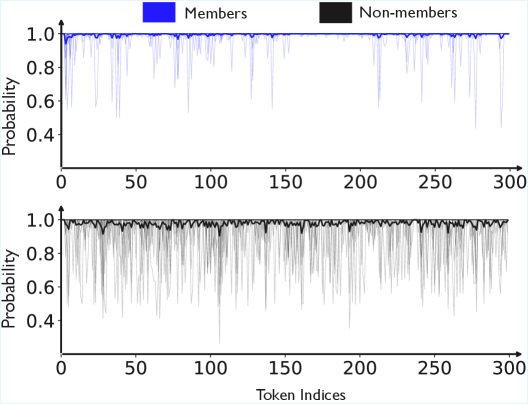
📊 实验亮点
实验结果表明,TBD方法在S1数据集上取得了显著的检测效果,AUC达到0.918,TPR@1% FPR达到0.470。这意味着在误报率仅为1%的情况下,TBD方法能够成功检测出47%的污染数据。这些结果证明了TBD方法在检测蒸馏数据污染方面的有效性和优越性,优于其他基线方法(具体对比基线未知)。
🎯 应用场景
该研究成果可应用于评估大型语言模型的安全性,防止模型在训练过程中受到恶意数据污染,提高模型的可信度。此外,该方法还可以用于检测和清理已有的蒸馏数据集,避免基准测试结果受到污染数据的影响,从而更准确地评估模型的真实性能。未来,该技术可能被集成到模型训练流程中,作为一种数据质量控制手段。
📄 摘要(原文)
Reasoning distillation has emerged as an efficient and powerful paradigm for enhancing the reasoning capabilities of large language models. However, reasoning distillation may inadvertently cause benchmark contamination, where evaluation data included in distillation datasets can inflate performance metrics of distilled models. In this work, we formally define the task of distillation data detection, which is uniquely challenging due to the partial availability of distillation data. Then, we propose a novel and effective method Token Probability Deviation (TBD), which leverages the probability patterns of the generated output tokens. Our method is motivated by the analysis that distilled models tend to generate near-deterministic tokens for seen questions, while producing more low-probability tokens for unseen questions. Our key idea behind TBD is to quantify how far the generated tokens' probabilities deviate from a high reference probability. In effect, our method achieves competitive detection performance by producing lower scores for seen questions than for unseen questions. Extensive experiments demonstrate the effectiveness of our method, achieving an AUC of 0.918 and a TPR@1% FPR of 0.470 on the S1 dataset.