Instability in Downstream Task Performance During LLM Pretraining
作者: Yuto Nishida, Masaru Isonuma, Yusuke Oda
分类: cs.CL
发布日期: 2025-10-06
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
通过检查点集成提升LLM预训练下游任务性能的稳定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练 下游任务 检查点集成 模型稳定性
📋 核心要点
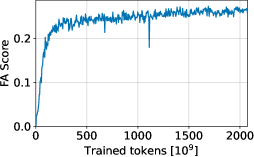
- 大型语言模型预训练过程中,下游任务性能波动大,难以选择最佳检查点。
- 论文提出检查点平均和集成两种后处理方法,聚合相邻检查点以降低性能波动。
- 实验证明,该方法能有效提升下游任务性能的稳定性,无需修改训练流程。
📝 摘要(中文)
在训练大型语言模型(LLM)时,通常会跟踪整个训练过程中的下游任务性能,并选择验证分数最高的检查点。然而,下游指标经常表现出显著的波动,这使得识别真正代表最佳性能模型的检查点变得困难。本研究实证分析了在多样化的网络规模语料库上训练的LLM中下游任务性能的稳定性。我们发现,任务分数在整个训练过程中频繁波动,无论是在聚合层面还是在示例层面。为了解决这种不稳定性,我们研究了两种事后检查点集成方法:检查点平均和集成,其动机是聚合相邻检查点可以降低性能波动。我们通过实验和理论证明,这些方法提高了下游性能的稳定性,而无需对训练过程进行任何更改。
🔬 方法详解
问题定义:大型语言模型(LLM)的预训练过程中,下游任务的性能评估指标(如准确率、F1值等)会随着训练的进行出现显著的波动。这种波动使得难以确定哪个检查点(checkpoint)代表了模型在下游任务上的最佳性能。现有方法通常选择验证集上表现最佳的检查点,但这种选择容易受到偶然因素的影响,导致最终模型性能不稳定。
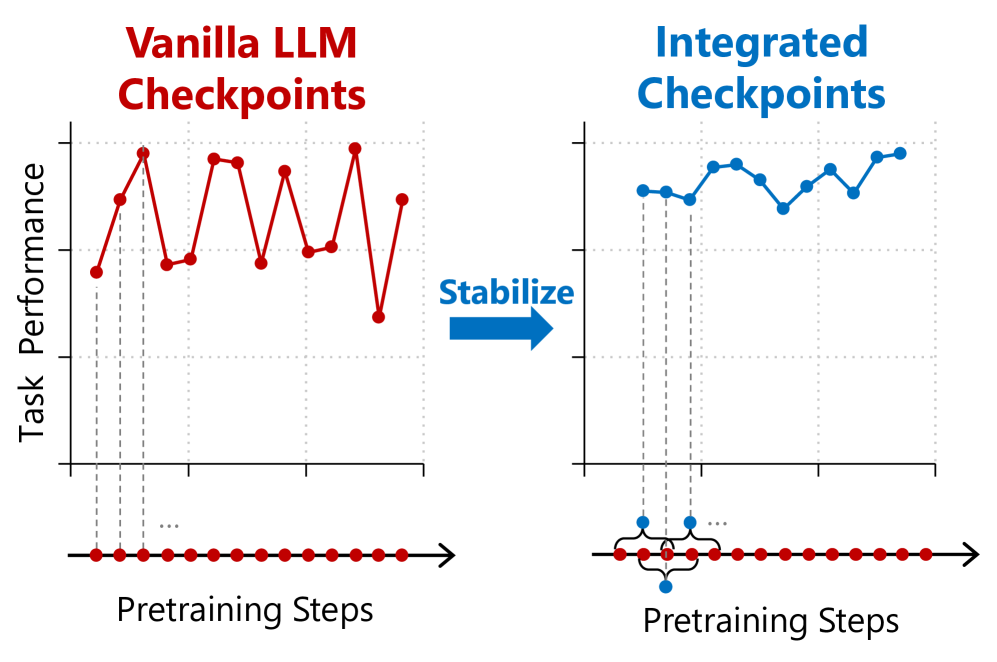
核心思路:论文的核心思路是,通过集成多个相邻的检查点,来平滑下游任务性能的波动,从而提高模型选择的鲁棒性。作者假设,相邻的检查点在模型参数空间上是接近的,它们的性能波动可能存在一定的互补性,通过集成可以降低单个检查点的偶然误差。
技术框架:论文主要研究了两种检查点集成方法:检查点平均(Checkpoint Averaging)和集成(Ensemble)。检查点平均是指将多个检查点的模型参数进行平均,得到一个新的模型。集成是指使用多个检查点分别进行预测,然后将预测结果进行平均或投票,得到最终的预测结果。这两种方法都是在预训练完成后进行的后处理步骤,不需要修改预训练的流程。
关键创新:论文的关键创新在于,它关注了LLM预训练过程中下游任务性能的稳定性问题,并提出了通过检查点集成来解决这个问题。与传统的选择单个最佳检查点的方法相比,检查点集成可以更有效地利用预训练过程中产生的多个模型,从而提高最终模型的性能和鲁棒性。
关键设计:论文没有涉及特别复杂的网络结构或损失函数设计。关键在于如何选择用于集成的检查点。作者可能考察了不同的选择策略,例如选择验证集上性能最好的几个检查点,或者选择训练过程中间隔一定步数的检查点。此外,对于集成方法,如何对不同检查点的预测结果进行加权平均也是一个需要考虑的设计细节。具体实验细节未知。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,检查点平均和集成两种方法可以有效提高下游任务性能的稳定性,而无需修改预训练流程。具体的性能提升幅度未知,但论文强调了这两种方法在降低性能波动方面的有效性。实验结果表明,集成多个检查点可以获得比选择单个最佳检查点更好的性能。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练和微调过程中,帮助研究人员和工程师更有效地选择和利用预训练模型,提高下游任务的性能和稳定性。此外,该方法也可以应用于其他机器学习模型的训练过程中,例如图像识别、语音识别等领域,具有一定的通用性。
📄 摘要(原文)
When training large language models (LLMs), it is common practice to track downstream task performance throughout the training process and select the checkpoint with the highest validation score. However, downstream metrics often exhibit substantial fluctuations, making it difficult to identify the checkpoint that truly represents the best-performing model. In this study, we empirically analyze the stability of downstream task performance in an LLM trained on diverse web-scale corpora. We find that task scores frequently fluctuate throughout training, both at the aggregate and example levels. To address this instability, we investigate two post-hoc checkpoint integration methods: checkpoint averaging and ensemble, motivated by the hypothesis that aggregating neighboring checkpoints can reduce performance volatility. We demonstrate both empirically and theoretically that these methods improve downstream performance stability without requiring any changes to the training procedure.