Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
作者: Sangmin Bae, Bilge Acun, Haroun Habeeb, Seungyeon Kim, Chien-Yu Lin, Liang Luo, Junjie Wang, Carole-Jean Wu
分类: cs.CL
发布日期: 2025-10-06
备注: 17 pages, 4 figures, 6 tables; detailed results will be included in the Appendix later
💡 一句话要点
系统分析混合语言模型架构,优化长文本建模的效率与性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合架构 语言模型 长文本建模 自注意力机制 状态空间模型 计算效率 模型优化
📋 核心要点
- 现有大型语言模型在长文本处理中面临计算效率瓶颈,单纯依赖自注意力机制难以兼顾性能与效率。
- 论文系统性地研究了层间和层内两种混合架构,将自注意力与状态空间模型融合,旨在提升长文本建模能力。
- 通过多角度评估,论文为混合语言模型的设计提供了实用指导,并优化了架构配置,提升了性能。
📝 摘要(中文)
大型语言模型的最新进展表明,混合架构——将自注意力机制与结构化状态空间模型(如Mamba)相结合——可以在建模质量和计算效率之间取得令人信服的平衡,尤其是在长上下文任务中。虽然这些混合模型显示出良好的性能,但关于混合策略的系统比较以及对其有效性背后关键因素的分析尚未明确地与社区分享。本文对基于层间(顺序)或层内(并行)融合的混合架构进行了全面评估。我们从语言建模性能、长上下文能力、缩放分析以及训练和推理效率等多个角度评估了这些设计。通过研究其计算原语的核心特征,我们确定了每种混合策略最关键的要素,并进一步为两种混合模型提出了最佳设计方案。我们的综合分析为开发混合语言模型提供了实用的指导和有价值的见解,有助于优化架构配置。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本时,计算复杂度高,效率低下。传统的自注意力机制虽然建模能力强,但计算量随序列长度呈平方增长,难以应用于超长文本。因此,如何在保证建模能力的同时,降低计算复杂度,是长文本建模面临的关键问题。
核心思路:论文的核心思路是将自注意力机制与状态空间模型(如Mamba)相结合,构建混合架构。自注意力擅长捕捉全局依赖关系,而状态空间模型在处理长序列时具有更高的计算效率。通过融合两者的优势,可以在建模质量和计算效率之间取得平衡。
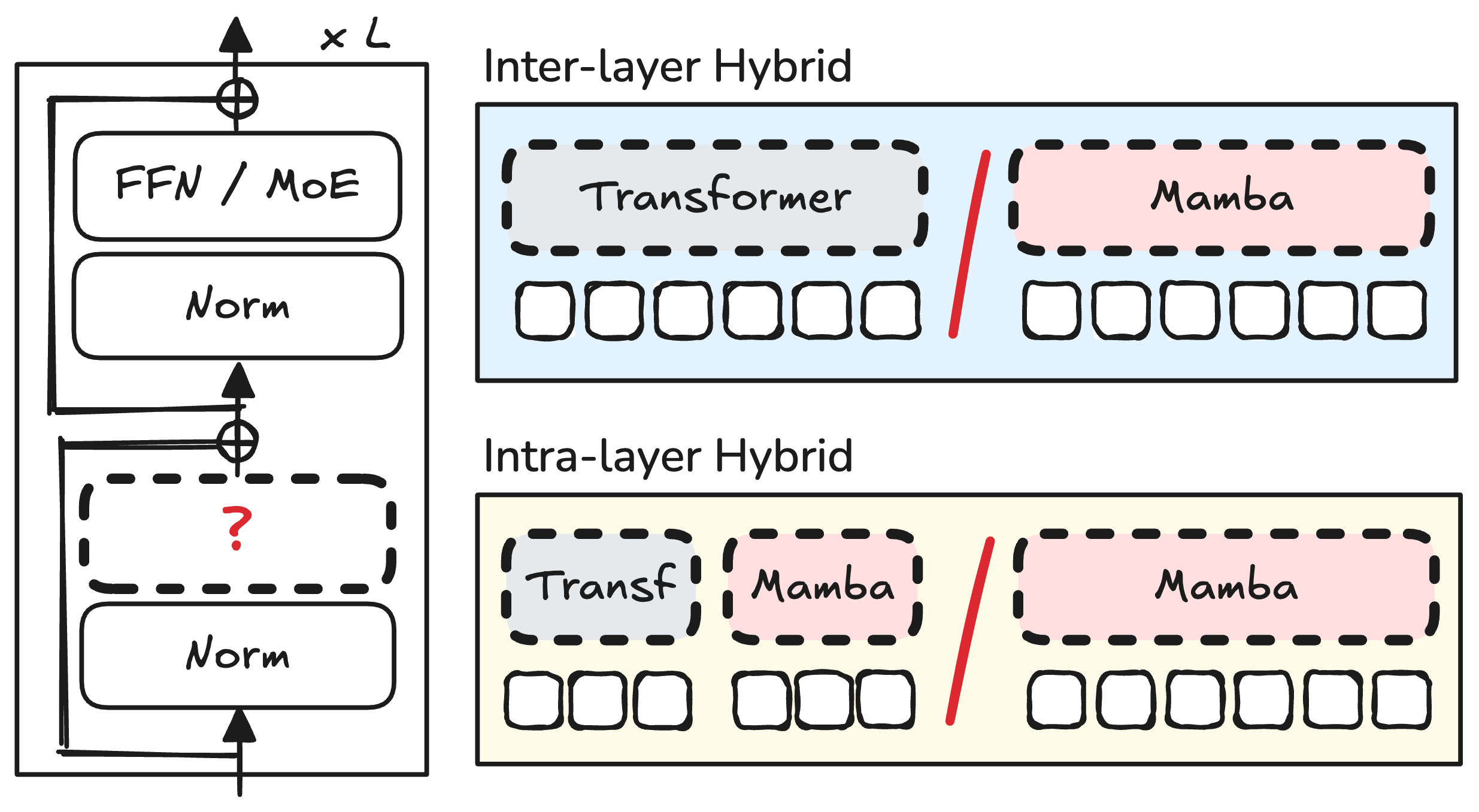
技术框架:论文主要研究了两种混合架构:层间(sequential)融合和层内(parallel)融合。层间融合是指将自注意力层和状态空间模型层交替堆叠。层内融合是指在同一层中并行使用自注意力和状态空间模型,并通过某种方式(如加权平均)将它们的输出融合。整体框架包括对这两种混合方式的系统性评估,并分析其在语言建模性能、长上下文能力、缩放分析以及训练和推理效率等方面的表现。
关键创新:论文的关键创新在于对混合架构的系统性分析和设计优化。以往的研究主要集中在单一的混合架构上,缺乏对不同混合策略的全面比较。本文通过对比层间和层内融合的优缺点,揭示了不同混合策略的适用场景,并为混合语言模型的设计提供了更全面的指导。
关键设计:论文的关键设计包括:1) 对不同混合比例的探索,例如自注意力层和状态空间模型层的比例;2) 对融合方式的优化,例如如何有效地融合自注意力和状态空间模型的输出;3) 对训练策略的调整,例如如何针对混合架构设计更有效的训练方法。此外,论文还关注了不同混合架构的缩放特性,并分析了其在不同模型规模下的性能表现。
🖼️ 关键图片

📊 实验亮点
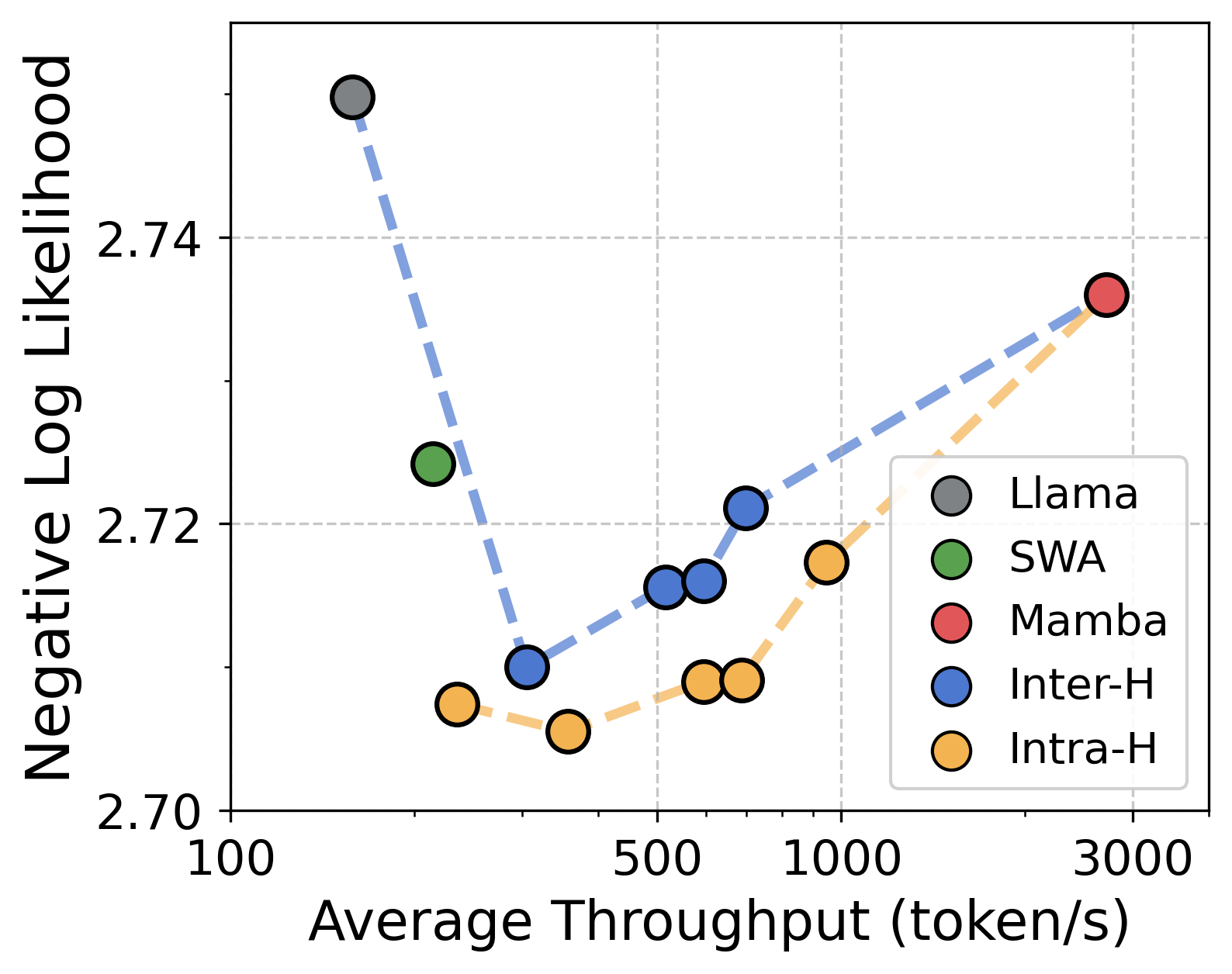
论文通过实验验证了混合架构在长文本建模方面的优势。具体性能数据未知,但论文强调通过系统性分析,为混合语言模型的设计提供了实用指导,并优化了架构配置,提升了性能。实验对比了层间和层内融合的优缺点,并分析了不同混合比例和融合方式对模型性能的影响。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的自然语言处理任务,例如文档摘要、机器翻译、对话系统、代码生成等。通过优化混合架构,可以提升这些应用在处理长文本时的效率和性能,降低计算成本,并为未来的大型语言模型设计提供新的思路。
📄 摘要(原文)
Recent progress in large language models demonstrates that hybrid architectures--combining self-attention mechanisms with structured state space models like Mamba--can achieve a compelling balance between modeling quality and computational efficiency, particularly for long-context tasks. While these hybrid models show promising performance, systematic comparisons of hybridization strategies and analyses on the key factors behind their effectiveness have not been clearly shared to the community. In this work, we present a holistic evaluation of hybrid architectures based on inter-layer (sequential) or intra-layer (parallel) fusion. We evaluate these designs from a variety of perspectives: language modeling performance, long-context capabilities, scaling analysis, and training and inference efficiency. By investigating the core characteristics of their computational primitive, we identify the most critical elements for each hybridization strategy and further propose optimal design recipes for both hybrid models. Our comprehensive analysis provides practical guidance and valuable insights for developing hybrid language models, facilitating the optimization of architectural configurations.