Are BabyLMs Deaf to Gricean Maxims? A Pragmatic Evaluation of Sample-efficient Language Models
作者: Raha Askari, Sina Zarrieß, Özge Alacam, Judith Sieker
分类: cs.CL
发布日期: 2025-10-06 (更新: 2025-10-08)
备注: Accepted for the BabyLM workshop in EMNLP 2025
💡 一句话要点
提出Gricean Maxims基准,评估小规模语言模型(BabyLMs)的语用推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语用推理 Gricean Maxims 小规模语言模型 BabyLMs 会话准则 自然语言处理 对话系统
📋 核心要点
- 现有语言模型在理解和应用语用推理方面存在不足,尤其是在处理隐式含义和会话准则时。
- 论文提出一个新基准,用于评估小规模语言模型(BabyLMs)在Gricean Maxims上的语用推理能力。
- 实验表明,增加训练数据量可以提升BabyLMs的语用推理能力,但仍与儿童和大型语言模型存在差距。
📝 摘要(中文)
隐式含义是人类交流的重要组成部分,因此语言模型必须能够识别和解释它们。Grice(1975)提出了一套会话准则,指导合作对话。说话者可能故意违反这些准则来表达字面意义之外的含义,而听者则识别这些违反行为以进行语用推理。本文基于Surian等人(1996)对儿童违反Gricean准则的敏感性研究,引入了一个新的基准,用于测试预训练数据量小于10M和100M tokens的语言模型(BabyLMs)是否能够区分符合准则和违反准则的语句。我们将这些BabyLMs在五个准则上的表现与儿童以及一个在3T tokens上预训练的大型语言模型(LLM)进行比较。结果表明,总体而言,在小于100M tokens上训练的模型优于在小于10M tokens上训练的模型,但仍未达到儿童和LLM的水平。研究结果表明,适量的数据增加可以改善语用行为的某些方面,从而导致对语用维度的更细粒度区分。
🔬 方法详解
问题定义:论文旨在评估小规模语言模型(BabyLMs)是否能够理解和应用Gricean Maxims,即合作对话中的会话准则。现有语言模型在处理隐式含义和语用推理方面存在不足,尤其是在数据量较少的情况下。这些模型可能无法有效地区分符合和违反会话准则的语句,从而影响其在实际对话场景中的应用。
核心思路:论文的核心思路是构建一个基准数据集,该数据集包含符合和违反Gricean Maxims的语句,并使用该数据集来评估不同规模的语言模型的语用推理能力。通过比较不同模型的表现,可以了解数据量对语用推理能力的影响,并为开发更有效的语用推理模型提供指导。
技术框架:该研究的技术框架主要包括以下几个部分:1) 构建Gricean Maxims基准数据集,该数据集包含符合和违反五个Gricean Maxims(Quantity, Quality, Relation, Manner, and Politeness)的语句。2) 选择不同规模的语言模型(BabyLMs),包括在小于10M和100M tokens上预训练的模型。3) 使用基准数据集评估这些模型区分符合和违反准则语句的能力。4) 将BabyLMs的表现与儿童和大型语言模型(LLM)进行比较。
关键创新:该研究的关键创新在于提出了一个专门用于评估语言模型语用推理能力的Gricean Maxims基准。该基准基于Surian等人(1996)对儿童的研究,并针对语言模型的特点进行了调整。此外,该研究还比较了不同规模语言模型的表现,揭示了数据量对语用推理能力的影响。与现有方法相比,该研究更关注小规模语言模型的语用推理能力,并提供了一个更细粒度的评估框架。
关键设计:基准数据集的设计参考了Surian等人的研究,并针对语言模型的特点进行了调整。数据集包含符合和违反五个Gricean Maxims的语句,并对每条语句进行了标注。评估指标包括准确率、精确率、召回率和F1值。模型训练和评估的具体参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
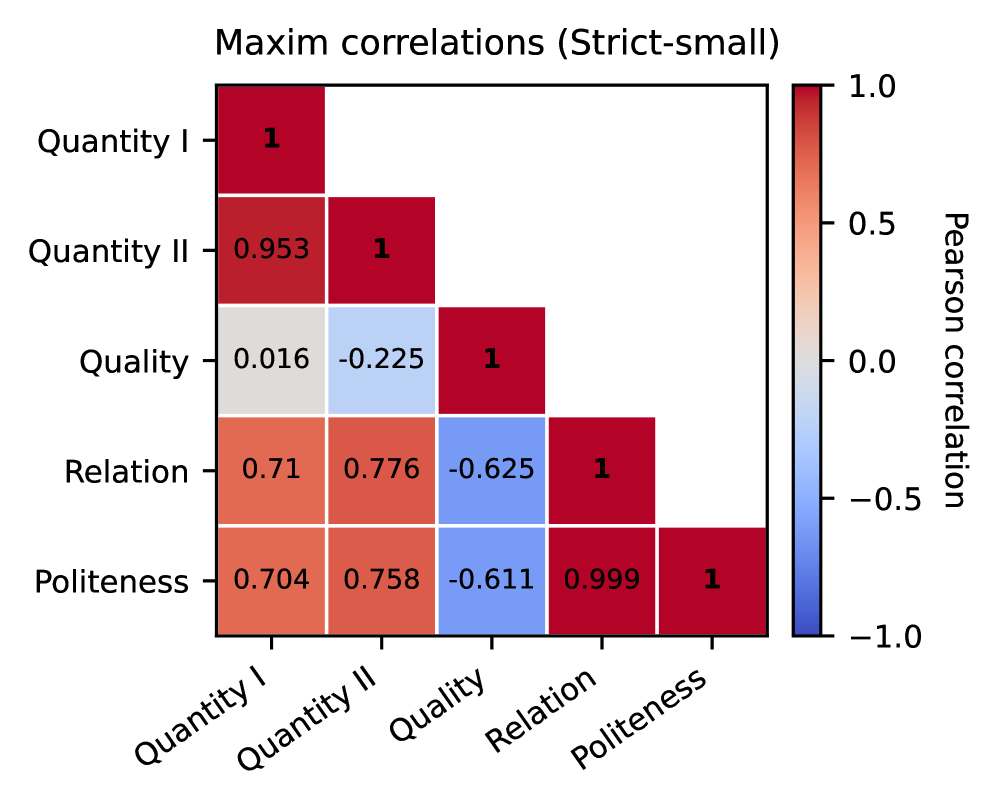
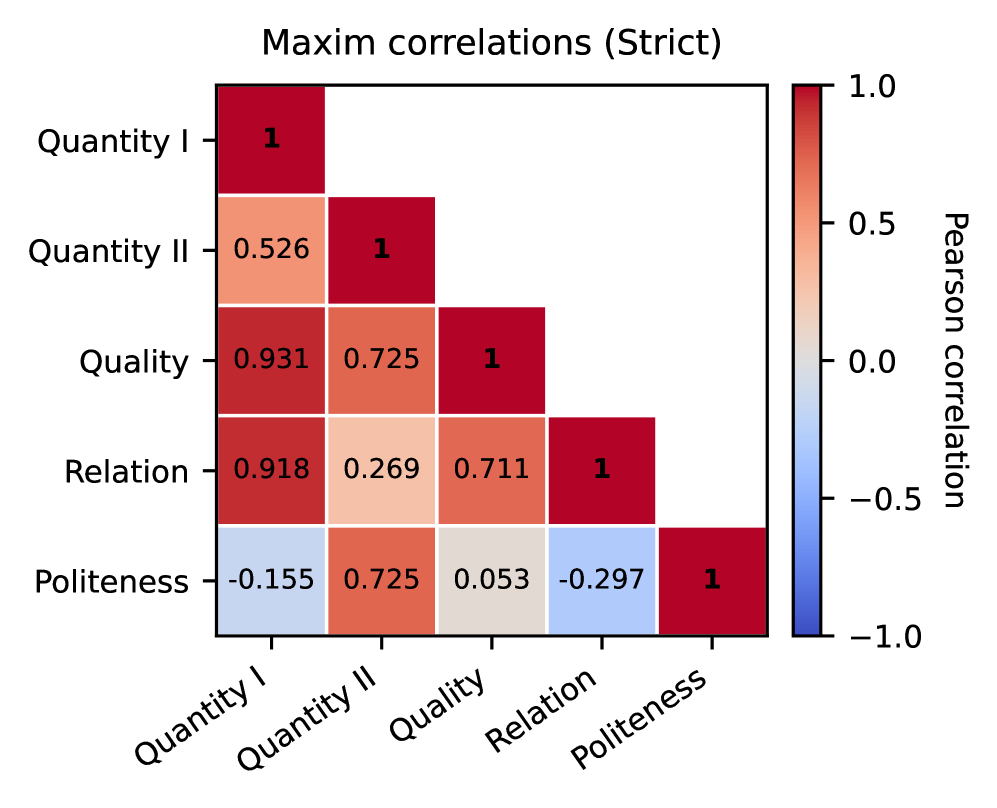
📊 实验亮点
实验结果表明,在小于100M tokens上训练的BabyLMs优于在小于10M tokens上训练的模型,但仍未达到儿童和大型语言模型的水平。这表明适量的数据增加可以改善语用行为的某些方面,从而导致对语用维度的更细粒度区分。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于对话系统、智能助手等领域,提升机器理解人类意图和进行自然对话的能力。通过提高语言模型的语用推理能力,可以使其更好地理解用户的隐含需求,从而提供更个性化和有效的服务。未来的研究可以进一步探索如何利用更少的训练数据来提升语言模型的语用推理能力,并将其应用于更复杂的对话场景。
📄 摘要(原文)
Implicit meanings are integral to human communication, making it essential for language models to be capable of identifying and interpreting them. Grice (1975) proposed a set of conversational maxims that guide cooperative dialogue, noting that speakers may deliberately violate these principles to express meanings beyond literal words, and that listeners, in turn, recognize such violations to draw pragmatic inferences. Building on Surian et al. (1996)'s study of children's sensitivity to violations of Gricean maxims, we introduce a novel benchmark to test whether language models pretrained on less than 10M and less than 100M tokens can distinguish maxim-adhering from maxim-violating utterances. We compare these BabyLMs across five maxims and situate their performance relative to children and a Large Language Model (LLM) pretrained on 3T tokens. We find that overall, models trained on less than 100M tokens outperform those trained on less than 10M, yet fall short of child-level and LLM competence. Our results suggest that modest data increases improve some aspects of pragmatic behavior, leading to finer-grained differentiation between pragmatic dimensions.