Multi-Agent Tool-Integrated Policy Optimization
作者: Zhanfeng Mo, Xingxuan Li, Yuntao Chen, Lidong Bing
分类: cs.CL
发布日期: 2025-10-06
备注: Work in progress
💡 一句话要点
提出MATPO,通过多智能体强化学习优化工具集成的大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 工具集成 大语言模型 策略优化 信用分配
📋 核心要点
- 现有工具集成的大语言模型受限于上下文长度和工具噪声,单智能体框架难以有效管理复杂任务。
- MATPO通过强化学习在单个LLM中训练规划者和工作者智能体,实现角色专业化和高效上下文管理。
- 实验表明,MATPO在多个数据集上显著优于单智能体基线,并对工具噪声具有更强的鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地依赖于多轮工具集成规划来处理知识密集型和复杂的推理任务。现有的实现通常依赖于单个智能体,但它们受到有限的上下文长度和嘈杂的工具响应的影响。一个自然的解决方案是采用具有规划者和工作者智能体的多智能体框架来管理上下文。然而,目前还没有方法支持对工具集成的多智能体框架进行有效的强化学习后训练。为了解决这个差距,我们提出了多智能体工具集成策略优化(MATPO),它允许使用强化学习,通过特定角色的提示,在单个LLM实例中训练不同的角色(规划者和工作者)。MATPO源于规划者和工作者rollout之间的一个有原则的信用分配机制。这种设计消除了部署多个LLM的需求,从而节省了内存,同时保留了专业化的好处。在GAIA-text、WebWalkerQA和FRAMES上的实验表明,MATPO始终优于单智能体基线,性能平均相对提高了18.38%,并且对嘈杂的工具输出表现出更强的鲁棒性。我们的研究结果突出了在单个LLM中统一多个智能体角色的有效性,并为稳定和高效的多智能体RL训练提供了实践见解。
🔬 方法详解
问题定义:现有的大语言模型在处理需要工具集成和复杂推理的任务时,通常采用单智能体框架。这种框架面临两个主要问题:一是上下文长度有限,难以处理多轮交互和长期依赖关系;二是容易受到工具返回的噪声信息干扰,影响决策的准确性。
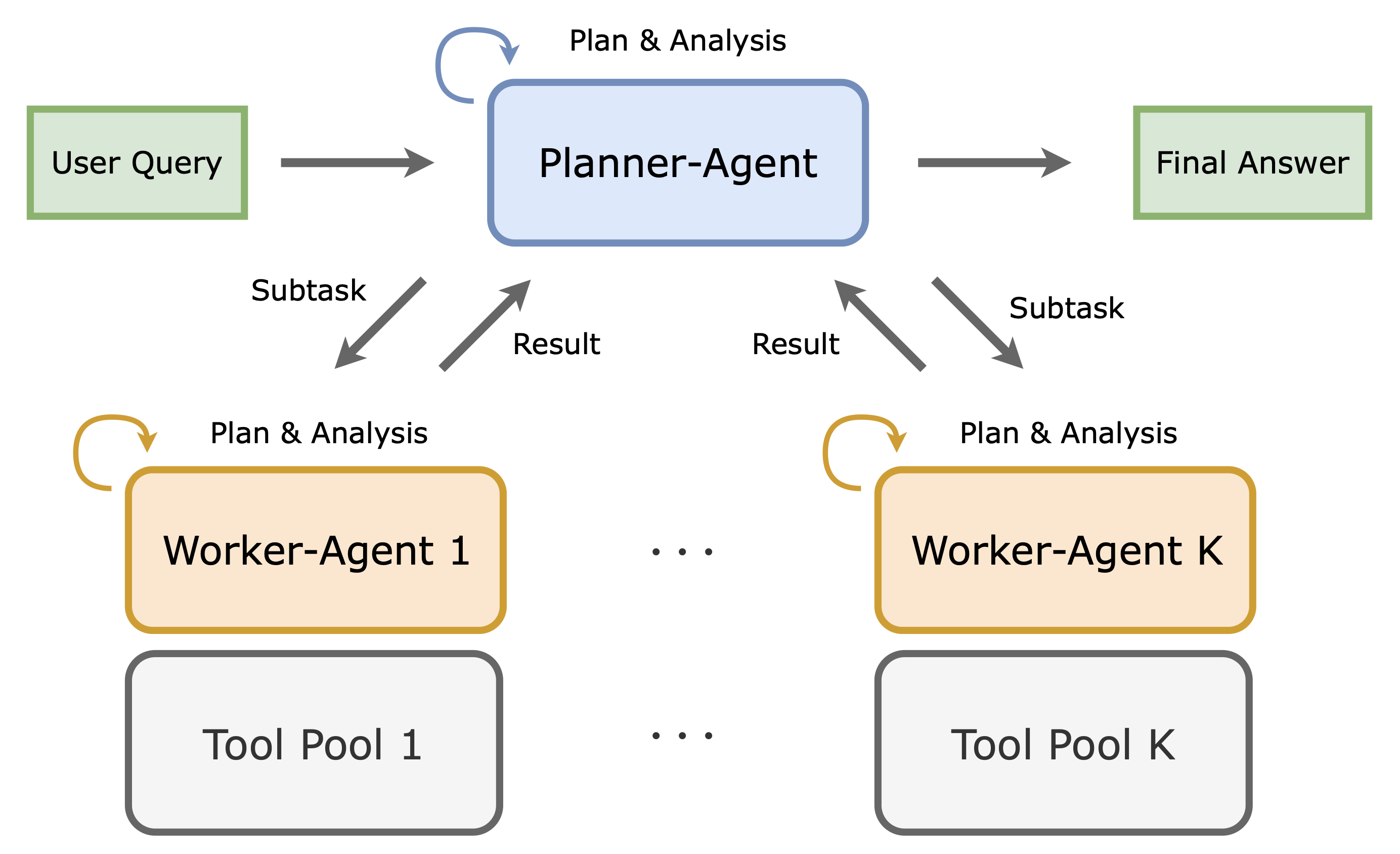
核心思路:MATPO的核心思路是将单智能体框架扩展为多智能体框架,引入规划者和工作者两种角色。规划者负责制定任务执行计划,工作者负责调用工具并执行具体操作。通过角色分离,可以更好地管理上下文,提高任务执行的效率和鲁棒性。同时,MATPO采用强化学习方法,对规划者和工作者的策略进行优化,使其能够更好地协同完成任务。
技术框架:MATPO的技术框架主要包括以下几个模块:1) 规划者智能体:负责接收任务描述,生成任务执行计划,并将计划分解为一系列子任务。2) 工作者智能体:负责接收规划者发送的子任务,调用相应的工具执行操作,并将结果返回给规划者。3) 奖励函数:用于评估规划者和工作者执行任务的质量,并指导策略优化。4) 策略优化算法:采用策略梯度方法,对规划者和工作者的策略进行优化,使其能够最大化累积奖励。
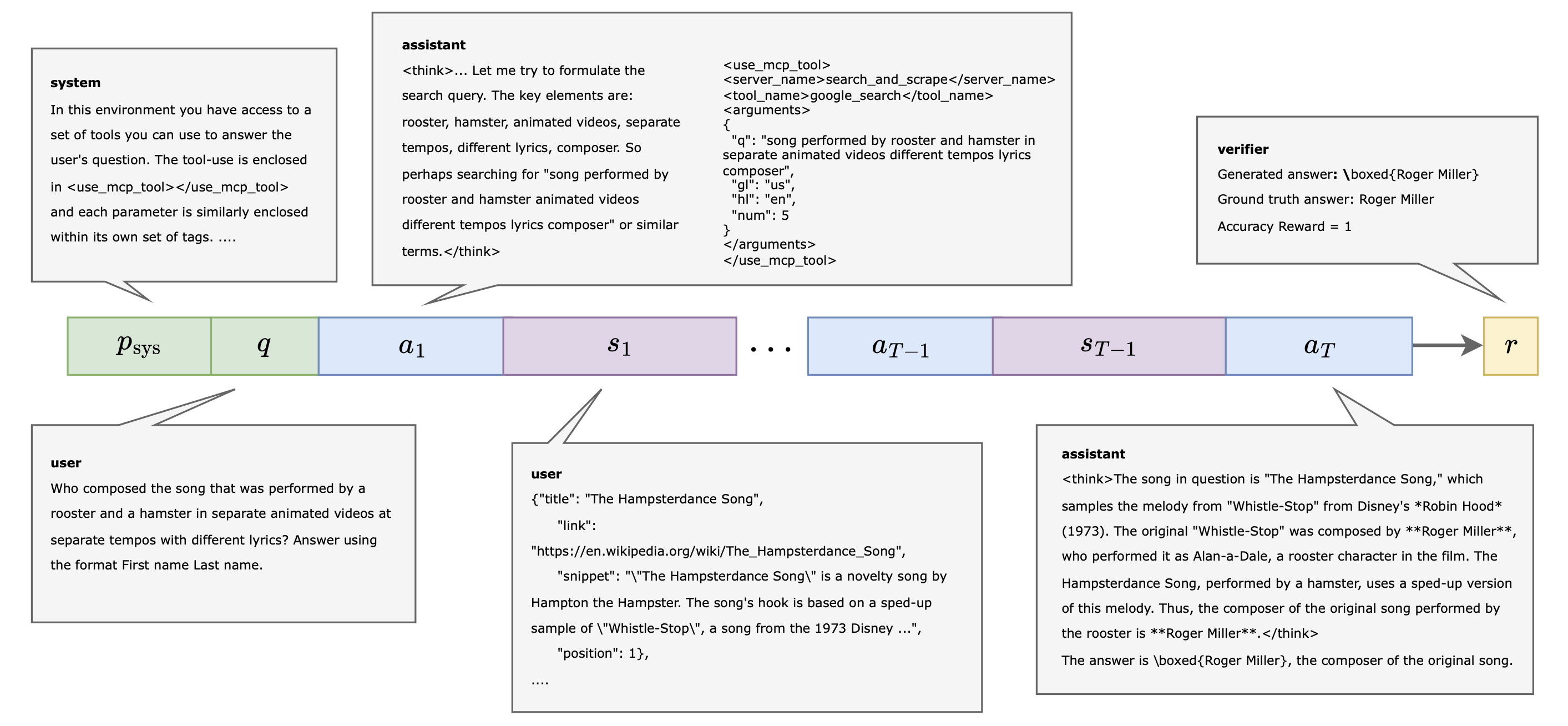
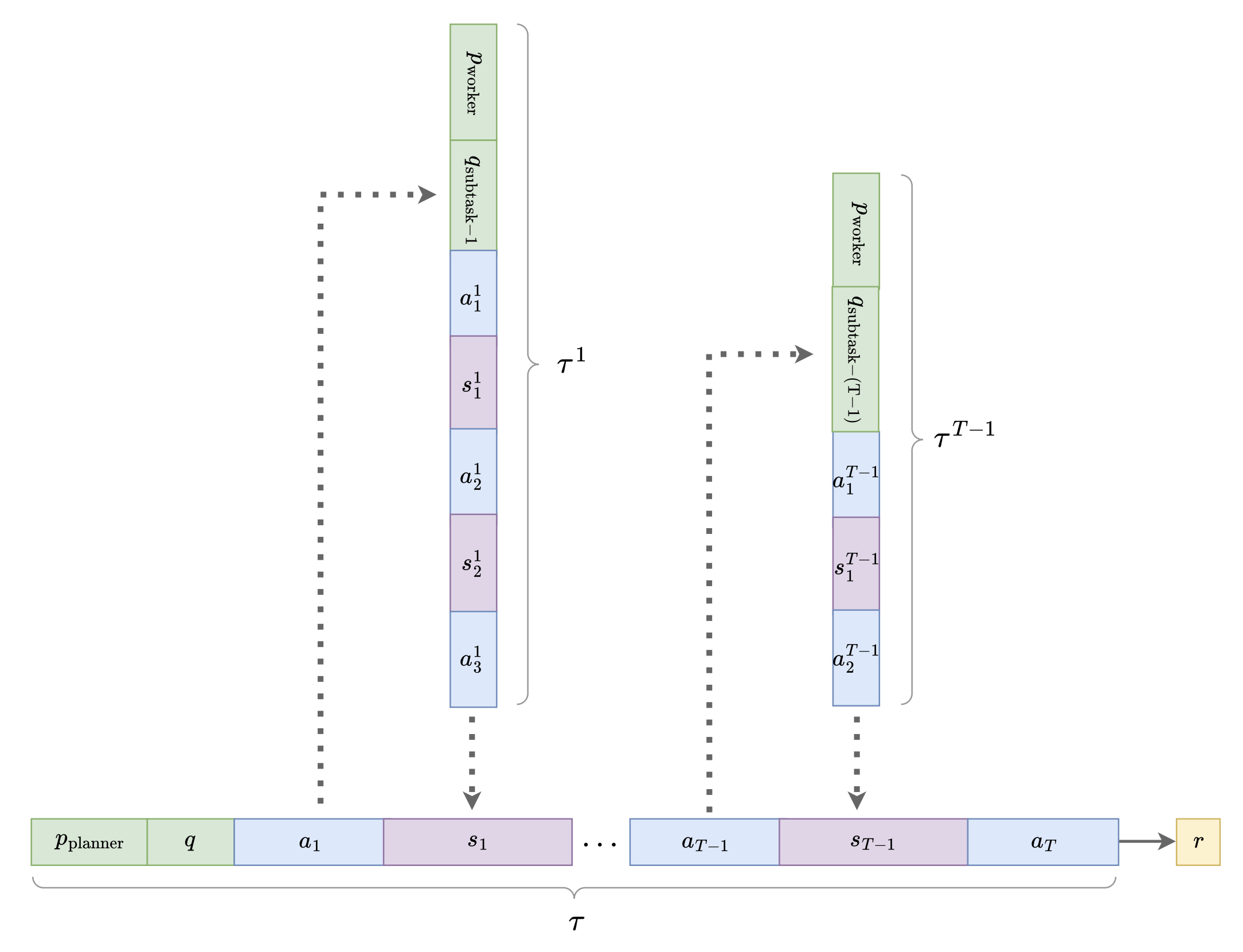
关键创新:MATPO的关键创新在于提出了一种新的多智能体强化学习方法,可以在单个LLM实例中训练不同的角色。这种方法避免了部署多个LLM带来的内存开销,同时保留了角色专业化的优势。此外,MATPO还设计了一种有原则的信用分配机制,可以在规划者和工作者的rollout之间进行有效的信用分配,从而提高训练的效率和稳定性。
关键设计:MATPO的关键设计包括:1) 角色特定的提示:为规划者和工作者设计不同的提示,使其能够更好地理解自己的角色和任务。2) 信用分配机制:采用一种基于时间差分的信用分配机制,根据规划者和工作者的贡献程度,将奖励分配给不同的角色。3) 策略梯度算法:采用PPO算法,对规划者和工作者的策略进行优化,使其能够最大化累积奖励。
🖼️ 关键图片
📊 实验亮点
MATPO在GAIA-text、WebWalkerQA和FRAMES数据集上进行了评估,实验结果表明,MATPO始终优于单智能体基线,性能平均相对提高了18.38%。此外,MATPO还表现出更强的鲁棒性,能够有效应对工具返回的噪声信息。这些结果表明,MATPO是一种有效且实用的多智能体强化学习方法。
🎯 应用场景
MATPO具有广泛的应用前景,可以应用于知识密集型问答、智能助手、自动化报告生成等领域。通过将复杂任务分解为多个子任务,并利用工具进行辅助,MATPO可以显著提高任务完成的效率和质量。此外,MATPO还可以应用于机器人控制领域,通过规划者制定行动计划,工作者控制机器人执行具体操作,实现更智能化的机器人控制。
📄 摘要(原文)
Large language models (LLMs) increasingly rely on multi-turn tool-integrated planning for knowledge-intensive and complex reasoning tasks. Existing implementations typically rely on a single agent, but they suffer from limited context length and noisy tool responses. A natural solution is to adopt a multi-agent framework with planner- and worker-agents to manage context. However, no existing methods support effective reinforcement learning post-training of tool-integrated multi-agent frameworks. To address this gap, we propose Multi-Agent Tool-Integrated Policy Optimization (MATPO), which enables distinct roles (planner and worker) to be trained within a single LLM instance using role-specific prompts via reinforcement learning. MATPO is derived from a principled credit assignment mechanism across planner and worker rollouts. This design eliminates the need to deploy multiple LLMs, which would be memory-intensive, while preserving the benefits of specialization. Experiments on GAIA-text, WebWalkerQA, and FRAMES show that MATPO consistently outperforms single-agent baselines by an average of 18.38% relative improvement in performance and exhibits greater robustness to noisy tool outputs. Our findings highlight the effectiveness of unifying multiple agent roles within a single LLM and provide practical insights for stable and efficient multi-agent RL training.