FocusMed: A Large Language Model-based Framework for Enhancing Medical Question Summarization with Focus Identification
作者: Chao Liu, Ling Luo, Tengxiao Lv, Huan Zhuang, Lejing Yu, Jian Wang, Hongfei Lin
分类: cs.CL, cs.AI
发布日期: 2025-10-06
备注: Accepted as a regular paper at BIBM2025
🔗 代码/项目: GITHUB
💡 一句话要点
FocusMed:基于大语言模型的医疗问答摘要框架,增强焦点识别能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗问题摘要 大语言模型 焦点识别 提示学习 文本摘要 自然语言处理 医疗健康
📋 核心要点
- 现有医疗问答摘要方法难以准确识别问题焦点,且大语言模型微调易产生幻觉,影响摘要质量。
- FocusMed框架通过核心焦点指导,利用提示模板提取焦点,并构建微调数据集,提升焦点识别能力。
- 实验结果表明,FocusMed在多个MQS数据集上取得了SOTA性能,显著提升了焦点识别能力并减轻了幻觉。
📝 摘要(中文)
随着在线医疗平台的快速发展,由于冗余信息和频繁出现的非专业术语,消费者健康问题(CHQ)在诊断方面效率低下。医疗问题摘要(MQS)任务旨在将CHQ转换为精简的医生常见问题(FAQ),但现有方法仍然面临问题焦点识别不佳和模型幻觉等挑战。本文探讨了大语言模型(LLM)在MQS任务中的潜力,并发现直接微调容易产生焦点识别偏差并生成不忠实的内容。为此,我们提出了一个基于核心焦点指导的优化框架。首先,设计了一个提示模板,以驱动LLM从CHQ中提取忠实于原始文本的核心焦点。然后,结合原始CHQ-FAQ对构建微调数据集,以提高识别问题焦点的能力。最后,提出了一种多维度质量评估和选择机制,以全面提高摘要的质量。我们在两个广泛采用的MQS数据集上进行了全面的实验,使用了三个已建立的评估指标。所提出的框架在所有指标上都取得了最先进的性能,表明模型识别问题关键焦点的能力显著提高,并显著减轻了幻觉。
🔬 方法详解
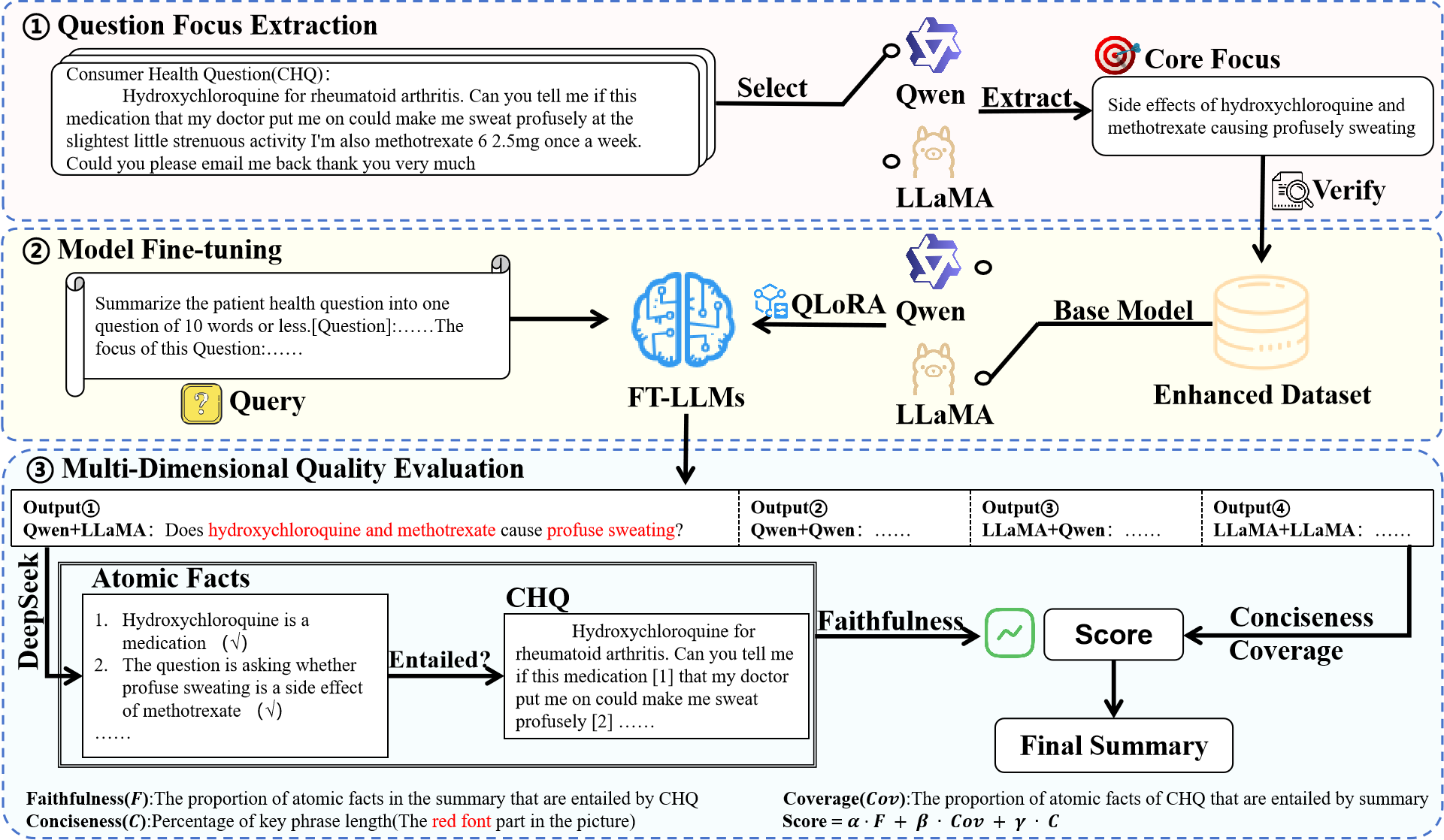
问题定义:医疗问题摘要(MQS)任务旨在将消费者健康问题(CHQ)转化为医生常见的精简问题(FAQ)。现有方法的痛点在于难以准确识别CHQ中的核心问题焦点,并且直接微调大语言模型(LLM)容易导致模型产生幻觉,生成不忠实于原文的内容,从而影响摘要的质量和可靠性。
核心思路:论文的核心思路是利用核心焦点指导来优化LLM在MQS任务中的表现。具体来说,首先通过提示工程(Prompt Engineering)引导LLM提取CHQ的核心焦点,然后利用提取的焦点信息构建微调数据集,从而提高LLM识别和利用问题焦点的能力。此外,还设计了多维度质量评估机制,以选择高质量的摘要结果。这样设计的目的是为了减少模型幻觉,提高摘要的忠实性和准确性。
技术框架:FocusMed框架主要包含三个阶段:1) 核心焦点提取:设计特定的提示模板,引导LLM从CHQ中提取核心焦点,确保提取的焦点忠实于原文。2) 微调数据集构建:结合原始的CHQ-FAQ对以及提取的核心焦点信息,构建用于微调LLM的数据集,增强模型对问题焦点的理解和利用能力。3) 多维度质量评估与选择:设计多维度的质量评估指标,对生成的摘要进行评估,并选择质量最高的摘要作为最终结果。
关键创新:该论文最重要的技术创新点在于提出了基于核心焦点指导的MQS框架。与直接微调LLM的方法不同,FocusMed显式地引导LLM关注问题的核心焦点,并通过构建包含焦点信息的微调数据集来增强模型对焦点的理解和利用能力。这种方法能够有效减少模型幻觉,提高摘要的忠实性和准确性。
关键设计:在核心焦点提取阶段,提示模板的设计至关重要,需要精心设计提示语,以引导LLM准确提取焦点信息。在微调数据集构建阶段,需要合理地将提取的焦点信息与原始CHQ-FAQ对结合,以充分利用焦点信息。在多维度质量评估阶段,需要设计合适的评估指标,例如忠实度、流畅度、相关性等,以全面评估摘要的质量。
🖼️ 关键图片


📊 实验亮点
FocusMed在两个广泛使用的MQS数据集上进行了实验,结果表明,该框架在所有评估指标上都取得了SOTA性能。与现有方法相比,FocusMed显著提高了模型识别问题关键焦点的能力,并有效减轻了幻觉。具体性能提升数据在论文中有详细展示。
🎯 应用场景
FocusMed框架可应用于在线医疗平台,自动生成高质量的医疗问题摘要,帮助医生快速了解患者的核心诉求,提高诊断效率。该研究还可推广至其他文本摘要任务,例如法律文档摘要、新闻摘要等,具有广泛的应用前景和实际价值。未来,可以进一步探索如何利用外部知识库来增强模型的摘要能力。
📄 摘要(原文)
With the rapid development of online medical platforms, consumer health questions (CHQs) are inefficient in diagnosis due to redundant information and frequent non-professional terms. The medical question summary (MQS) task aims to transform CHQs into streamlined doctors' frequently asked questions (FAQs), but existing methods still face challenges such as poor identification of question focus and model hallucination. This paper explores the potential of large language models (LLMs) in the MQS task and finds that direct fine-tuning is prone to focus identification bias and generates unfaithful content. To this end, we propose an optimization framework based on core focus guidance. First, a prompt template is designed to drive the LLMs to extract the core focus from the CHQs that is faithful to the original text. Then, a fine-tuning dataset is constructed in combination with the original CHQ-FAQ pairs to improve the ability to identify the focus of the question. Finally, a multi-dimensional quality evaluation and selection mechanism is proposed to comprehensively improve the quality of the summary from multiple dimensions. We conduct comprehensive experiments on two widely-adopted MQS datasets using three established evaluation metrics. The proposed framework achieves state-of-the-art performance across all measures, demonstrating a significant boost in the model's ability to identify critical focus of questions and a notable mitigation of hallucinations. The source codes are freely available at https://github.com/DUT-LiuChao/FocusMed.