Contrastive Learning Using Graph Embeddings for Domain Adaptation of Language Models in the Process Industry
作者: Anastasia Zhukova, Jonas Lührs, Christian E. Lobmüller, Bela Gipp
分类: cs.CL, cs.IR
发布日期: 2025-10-06 (更新: 2025-10-07)
备注: accepted to EMNLP 2025 (industry track)
💡 一句话要点
利用图嵌入对比学习,提升语言模型在流程工业领域自适应能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 图嵌入 领域自适应 语言模型 流程工业 知识图谱 文本嵌入
📋 核心要点
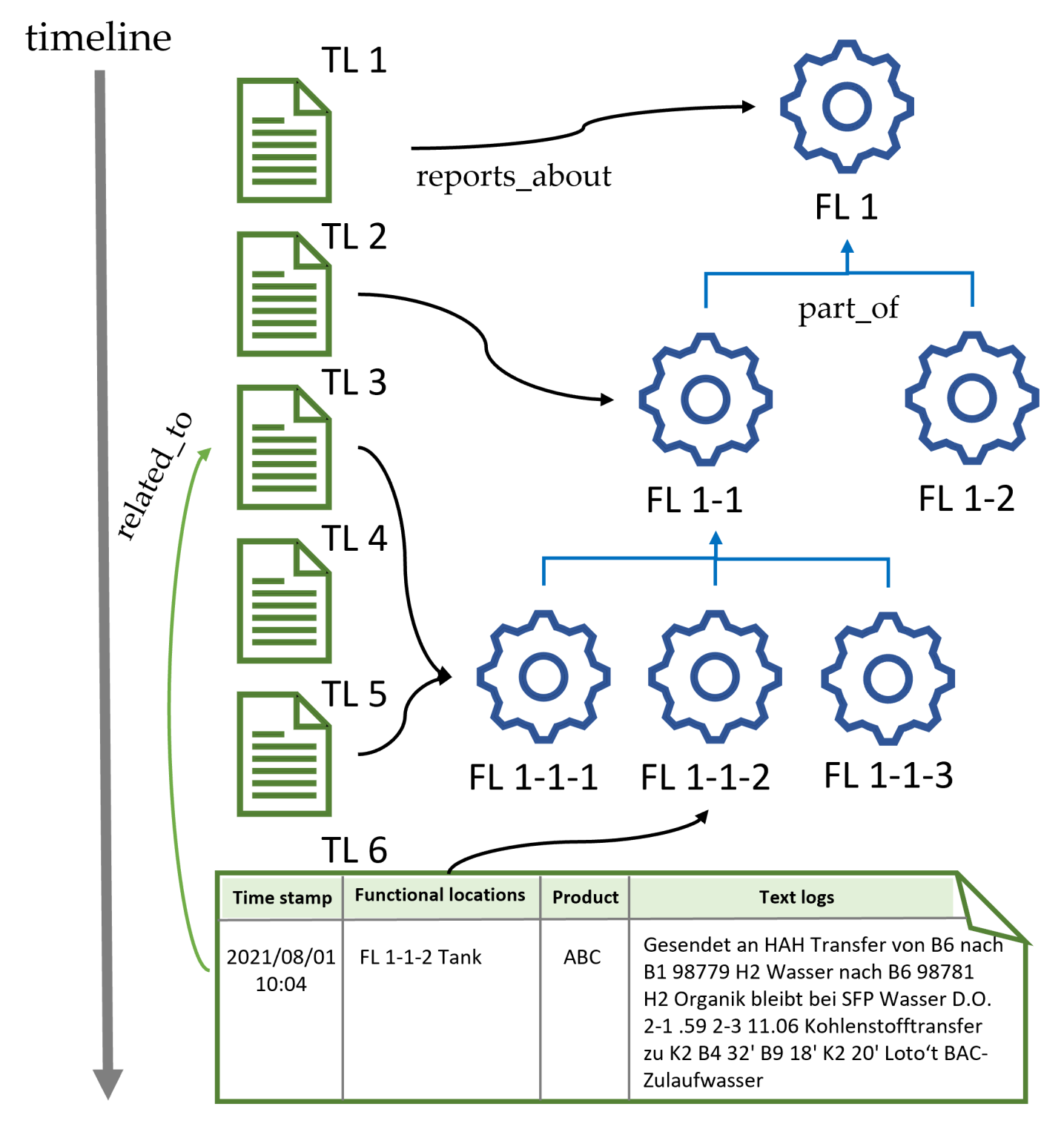
- 现有方法难以有效利用流程工业文本日志中的知识图谱结构信息,导致领域术语和关系学习不足。
- 论文采用图嵌入对比学习方法SciNCL,将知识图谱信息融入语言模型,提升领域自适应能力。
- 实验结果表明,该方法在流程工业文本嵌入基准上显著优于现有方法,且模型参数量更少。
📝 摘要(中文)
本文探索了SciNCL方法在流程工业领域的应用,该方法是一种图感知的邻域对比学习方法,最初为科学出版物设计,旨在通过结合图结构的额外知识来增强预训练语言模型,从而学习领域特定的术语或文档之间的关系。流程工业的文本日志包含关于日常运营的关键信息,并且通常被构建为稀疏知识图谱。实验表明,使用从图嵌入(GE)导出的三元组微调的语言模型,在专有的流程工业文本嵌入基准(PITEB)上,性能优于最先进的mE5-large文本编码器9.8-14.3%(5.45-7.96个百分点),同时参数量减少了3倍。
🔬 方法详解
问题定义:流程工业领域的文本日志包含大量关键信息,但现有方法难以有效利用这些日志中蕴含的知识图谱结构信息,导致语言模型在学习领域特定术语和文档关系时表现不佳。现有方法通常忽略了文本之间的结构化关系,或者无法有效地将知识图谱的信息融入到语言模型中,从而限制了模型在特定领域的性能。
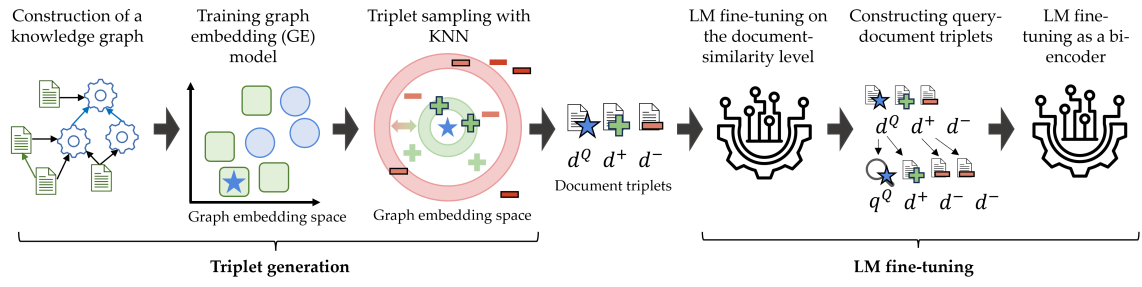
核心思路:论文的核心思路是利用图嵌入(Graph Embedding)技术,将流程工业文本日志构建的知识图谱中的节点(文本)和边(关系)映射到低维向量空间。然后,通过对比学习的方式,让模型学习到图中相邻节点的相似表示,从而将图结构的知识融入到语言模型中。这样,模型不仅可以学习到文本的语义信息,还可以学习到文本之间的关系信息,从而提升模型在流程工业领域的自适应能力。
技术框架:整体框架包括以下几个主要阶段:1) 构建流程工业文本日志的知识图谱;2) 使用图嵌入算法(如Node2Vec、DeepWalk等)学习知识图谱中节点的向量表示;3) 基于图嵌入结果,构建对比学习的三元组(anchor, positive, negative),其中anchor节点和positive节点在图中相邻,anchor节点和negative节点在图中不相邻;4) 使用对比学习损失函数(如InfoNCE)微调预训练语言模型,使其学习到图结构的知识。
关键创新:最重要的技术创新点在于将图嵌入和对比学习相结合,用于领域自适应的语言模型微调。与传统的微调方法相比,该方法能够更有效地利用知识图谱的结构信息,从而提升模型在特定领域的性能。与直接将知识图谱信息注入到语言模型的方法相比,该方法更加灵活,可以适用于不同的图嵌入算法和对比学习损失函数。
关键设计:关键设计包括:1) 选择合适的图嵌入算法,以有效地捕捉知识图谱的结构信息;2) 设计合适的对比学习三元组构建策略,以确保正样本和负样本的选择能够有效地引导模型学习;3) 选择合适的对比学习损失函数,以优化模型的表示学习;4) 调整预训练语言模型的微调策略,以避免过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果显示,使用图嵌入对比学习微调的语言模型在流程工业文本嵌入基准(PITEB)上,性能优于最先进的mE5-large文本编码器9.8-14.3%(5.45-7.96个百分点),同时参数量减少了3倍。这表明该方法能够在保证性能的同时,显著降低模型的计算复杂度。
🎯 应用场景
该研究成果可应用于流程工业的智能运维、故障诊断、安全预警等领域。通过提升语言模型对流程工业领域文本的理解能力,可以更有效地从文本日志中提取关键信息,辅助工程师进行决策,提高生产效率,降低运营成本,并提升安全性。未来,该方法还可以推广到其他具有知识图谱结构的领域,如医疗、金融等。
📄 摘要(原文)
Recent trends in NLP utilize knowledge graphs (KGs) to enhance pretrained language models by incorporating additional knowledge from the graph structures to learn domain-specific terminology or relationships between documents that might otherwise be overlooked. This paper explores how SciNCL, a graph-aware neighborhood contrastive learning methodology originally designed for scientific publications, can be applied to the process industry domain, where text logs contain crucial information about daily operations and are often structured as sparse KGs. Our experiments demonstrate that language models fine-tuned with triplets derived from graph embeddings (GE) outperform a state-of-the-art mE5-large text encoder by 9.8-14.3% (5.45-7.96p) on the proprietary process industry text embedding benchmark (PITEB) while having 3 times fewer parameters.