FedSRD: Sparsify-Reconstruct-Decompose for Communication-Efficient Federated Large Language Models Fine-Tuning
作者: Guochen Yan, Luyuan Xie, Qingni Shen, Yuejian Fang, Zhonghai Wu
分类: cs.CL
发布日期: 2025-10-06 (更新: 2025-10-08)
💡 一句话要点
提出FedSRD框架,通过稀疏化-重构-分解,解决联邦LLM微调中的通信瓶颈问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 低秩适应 通信效率 模型微调
📋 核心要点
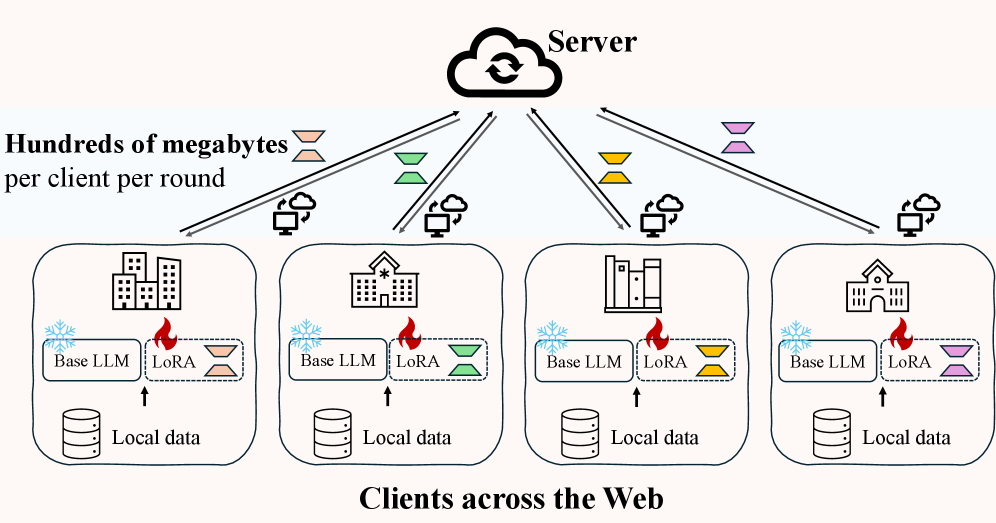
- 现有联邦学习微调LLM方法,特别是基于LoRA的方法,在异构网络中面临严重的通信开销瓶颈。
- FedSRD框架通过稀疏化LoRA更新、服务器端重构聚合以及稀疏低秩分解广播,实现通信效率的提升。
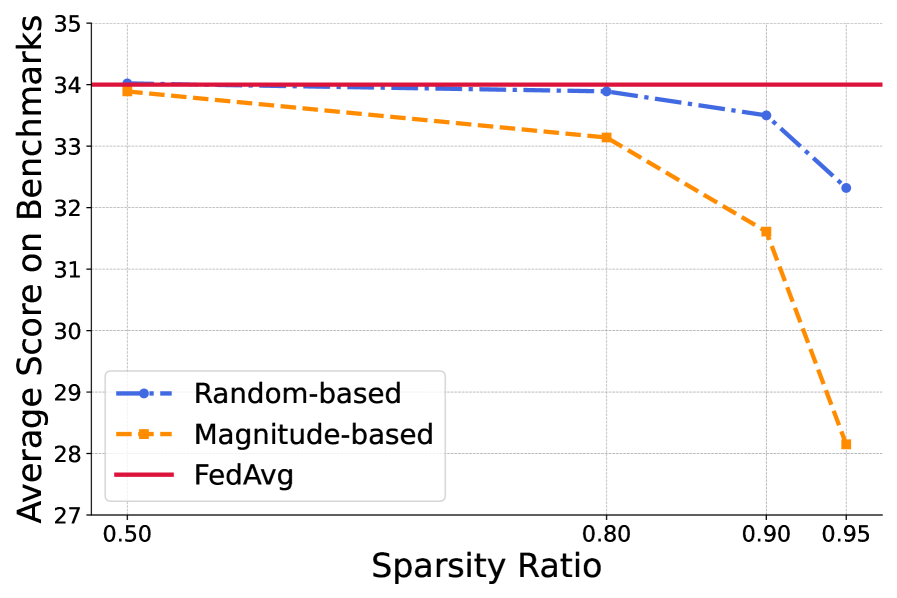
- 实验表明,FedSRD能显著降低通信成本高达90%,并在异构客户端数据上提升模型性能。
📝 摘要(中文)
当前在公开Web数据上训练大型语言模型(LLM)的范式正变得难以为继,专业领域的高质量数据源正接近枯竭。联邦学习(FL)作为一种实用的解决方案,通过利用分布在全球客户端的私有数据进行隐私保护的协同微调,为下一代去中心化Web上的AI提供了可能。虽然低秩适应(LoRA)是高效微调的标准方法,但其在联邦环境中的应用面临着一个关键挑战:在Web的异构网络条件下,通信开销仍然是一个显著的瓶颈。LoRA参数中的结构冗余不仅带来了沉重的通信负担,而且在聚合客户端更新时还会引入冲突。为了解决这个问题,我们提出了FedSRD,一个为通信高效的联邦LLM微调而设计的稀疏化-重构-分解框架。我们首先引入了一种重要性感知的稀疏化方法,该方法保留了LoRA更新的结构完整性,以减少上传的参数数量。然后,服务器在全秩空间中重构和聚合这些更新,以减轻冲突。最后,它将全局更新分解为稀疏的低秩格式进行广播,确保对称高效的循环。我们还提出了一种高效的变体FedSRD-e,以减少计算开销。在10个基准测试上的实验结果表明,我们的框架显著降低了高达90%的通信成本,同时甚至提高了异构客户端数据上的模型性能。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,大型语言模型(LLM)微调过程中由于LoRA参数的结构冗余导致的巨大通信开销问题。现有方法在异构网络环境中,通信效率低下,严重制约了联邦LLM的实际应用。
核心思路:论文的核心思路是利用LoRA参数的内在结构冗余性,通过稀疏化减少上传参数量,并在服务器端进行重构以缓解聚合冲突,最后将全局更新分解为稀疏低秩形式进行广播,从而实现通信效率的提升。这种设计旨在保持模型性能的同时,显著降低通信成本。
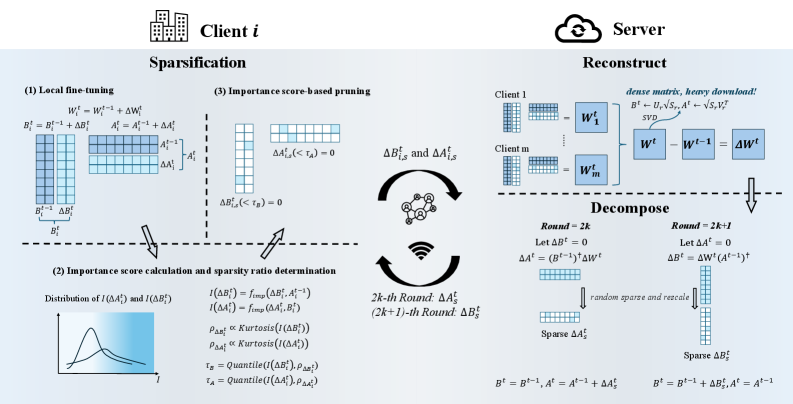
技术框架:FedSRD框架包含三个主要阶段:1) 稀疏化(Sparsify):客户端进行LoRA微调后,采用重要性感知的稀疏化方法,保留重要的LoRA更新,减少上传参数量。2) 重构(Reconstruct):服务器接收到稀疏更新后,在全秩空间中重构这些更新,以减轻聚合冲突。3) 分解(Decompose):服务器将全局更新分解为稀疏的低秩格式,然后广播给客户端。此外,论文还提出了一个高效变体FedSRD-e,旨在进一步降低计算开销。
关键创新:FedSRD的关键创新在于其稀疏化-重构-分解的整体框架,以及重要性感知的稀疏化方法。与现有方法不同,FedSRD不仅关注减少参数量,还考虑了服务器端的重构和分解,从而在保证模型性能的同时,显著降低了通信成本。
关键设计:论文中关键的设计包括:1) 重要性感知的稀疏化方法,具体实现细节未知。2) 服务器端重构的具体算法,细节未知。3) 全局更新分解为稀疏低秩格式的具体方法,细节未知。4) FedSRD-e的具体实现,细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FedSRD框架在10个基准测试上显著降低了高达90%的通信成本,同时在异构客户端数据上甚至提高了模型性能。这些结果验证了FedSRD在通信效率和模型性能方面的优越性,使其成为联邦LLM微调的一个有前景的解决方案。
🎯 应用场景
FedSRD框架可应用于各种需要联邦学习进行LLM微调的场景,例如医疗健康、金融服务等。它能够保护用户隐私,降低通信成本,提高模型训练效率,促进LLM在去中心化Web上的应用,并加速AI技术在各个领域的普及。
📄 摘要(原文)
The current paradigm of training large language models (LLMs) on publicly available Web data is becoming unsustainable, with high-quality data sources in specialized domains nearing exhaustion. Federated Learning (FL) emerges as a practical solution for the next generation of AI on a decentralized Web, enabling privacy-preserving collaborative fine-tuning by leveraging private data distributed across a global client base. While Low-Rank Adaptation (LoRA) is the standard for efficient fine-tuning, its application in federated settings presents a critical challenge: communication overhead remains a significant bottleneck across the Web's heterogeneous network conditions. The structural redundancy within LoRA parameters not only incurs a heavy communication burden but also introduces conflicts when aggregating client updates. To address this, we propose FedSRD, a Sparsify-Reconstruct-Decompose framework designed for communication-efficient federated LLMs fine-tuning. We first introduce an importance-aware sparsification method that preserves the structural integrity of LoRA updates to reduce the uploaded parameter count. The server then reconstructs and aggregates these updates in a full-rank space to mitigate conflicts. Finally, it decomposes the global update into a sparse low-rank format for broadcast, ensuring a symmetrically efficient cycle. We also propose an efficient variant, FedSRD-e, to reduce computational overhead. Experimental results on 10 benchmarks demonstrate that our framework significantly reduces communication costs by up to 90\% while even improving model performance on heterogeneous client data.