Large Language Models Preserve Semantic Isotopies in Story Continuations
作者: Marc Cavazza
分类: cs.CL, cs.AI
发布日期: 2025-10-06
💡 一句话要点
研究表明,大型语言模型在故事续写中能够保持语义同位素
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语义同位素 故事续写 文本生成 语义理解
📋 核心要点
- 现有研究对大型语言模型(LLMs)如何处理和保持文本的深层语义结构(如语义同位素)关注不足。
- 该研究通过故事续写实验,考察LLM在生成文本时是否能保持语义同位素,从而揭示其语义理解能力。
- 实验结果表明,在一定token范围内,LLM在故事续写中能够有效地保持语义同位素的多个结构和语义属性。
📝 摘要(中文)
本文探讨了文本语义与大型语言模型(LLMs)的相关性,扩展了先前关于分布语义和结构语义之间联系的见解。我们研究了LLM生成的文本是否保留了语义同位素。我们设计了一个故事续写实验,使用10,000个ROCStories提示,由五个LLM完成。我们首先验证了GPT-4o从语言基准中提取同位素的能力,然后将其应用于生成的故事。然后,我们分析了同位素的结构(覆盖率、密度、扩散)和语义属性,以评估它们如何受到补全的影响。结果表明,在给定的token范围内,LLM补全可以在多个属性上保持语义同位素。
🔬 方法详解
问题定义:现有方法在评估大型语言模型(LLMs)的语义理解能力时,往往侧重于表面的文本相似性或逻辑一致性,而忽略了深层的语义结构,例如语义同位素。语义同位素是指在文本中反复出现的语义主题或概念,它对于理解文本的连贯性和一致性至关重要。因此,如何评估LLM在生成文本时是否能够保持语义同位素,是一个重要的研究问题。
核心思路:该论文的核心思路是通过故事续写实验来评估LLM的语义同位素保持能力。具体来说,给定一个故事的开头(prompt),让LLM生成故事的结尾,然后分析生成的结尾部分是否与开头部分保持了相同的语义同位素。如果LLM能够生成与开头部分具有相同语义主题的故事结尾,则说明它具有较强的语义理解和保持能力。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用ROCStories数据集中的故事开头作为prompt;2) 使用五个不同的LLM(具体模型未知)生成故事结尾;3) 使用GPT-4o提取故事开头和结尾中的语义同位素;4) 分析提取出的语义同位素的结构(覆盖率、密度、扩散)和语义属性,比较故事开头和结尾之间的差异。
关键创新:该研究的关键创新在于将语义同位素的概念引入到LLM的评估中,提供了一种新的评估LLM语义理解能力的方法。与传统的评估方法相比,该方法更加关注文本的深层语义结构,能够更全面地评估LLM的语义理解能力。
关键设计:实验的关键设计包括:1) 使用ROCStories数据集,因为它包含大量的故事,可以提供丰富的实验数据;2) 使用GPT-4o提取语义同位素,因为它在语义理解方面具有较强的能力;3) 分析语义同位素的多个属性(覆盖率、密度、扩散),以更全面地评估LLM的语义保持能力。具体的参数设置、损失函数、网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


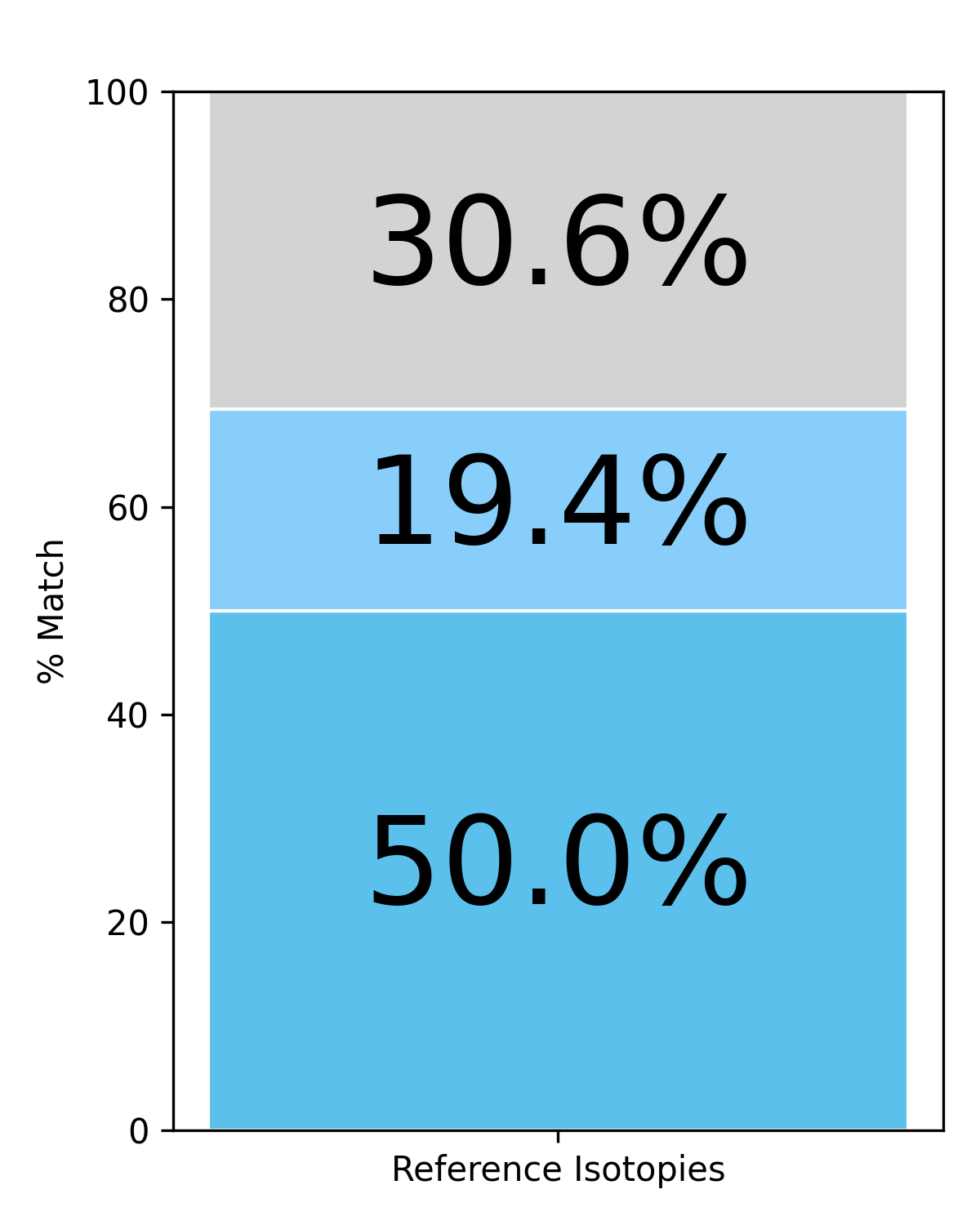
📊 实验亮点
实验结果表明,在给定的token范围内,LLM在故事续写中能够有效地保持语义同位素的多个结构和语义属性。这表明LLM不仅能够生成语法正确的文本,还能够理解和保持文本的深层语义结构。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于提升故事生成、对话系统和文本摘要等任务的质量。通过确保生成文本保持语义同位素,可以提高文本的连贯性、一致性和可理解性。此外,该研究也为评估和改进LLM的语义理解能力提供了新的思路。
📄 摘要(原文)
In this work, we explore the relevance of textual semantics to Large Language Models (LLMs), extending previous insights into the connection between distributional semantics and structural semantics. We investigate whether LLM-generated texts preserve semantic isotopies. We design a story continuation experiment using 10,000 ROCStories prompts completed by five LLMs. We first validate GPT-4o's ability to extract isotopies from a linguistic benchmark, then apply it to the generated stories. We then analyze structural (coverage, density, spread) and semantic properties of isotopies to assess how they are affected by completion. Results show that LLM completion within a given token horizon preserves semantic isotopies across multiple properties.