Benchmarking Open-Source Large Language Models for Persian in Zero-Shot and Few-Shot Learning
作者: Mahdi Cherakhloo, Arash Abbasi, Mohammad Saeid Sarafraz, Bijan Vosoughi Vahdat
分类: cs.CL, cs.AI
发布日期: 2025-10-05
💡 一句话要点
评估开源大语言模型在波斯语零样本和少样本学习中的性能表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 波斯语NLP 大型语言模型 零样本学习 少样本学习 基准测试 开源模型 Gemma 2
📋 核心要点
- 现有大型语言模型在低资源语言(如波斯语)上的性能评估不足,缺乏系统性的基准测试。
- 该研究通过零样本和少样本学习范式,在多个波斯语NLP任务上评估开源LLM的性能。
- 实验结果表明,Gemma 2在多数任务中表现最佳,但在token级别理解任务上仍面临挑战。
📝 摘要(中文)
大型语言模型(LLMs)在多种语言中展现了卓越的能力,但它们在波斯语等低资源语言中的有效性需要深入研究。本文对几种开源LLM在波斯语自然语言处理(NLP)任务中的性能进行了全面基准测试,采用了零样本和少样本学习范式。我们使用ParsiNLU和ArmanEmo等已建立的波斯语数据集,在情感分析、命名实体识别、阅读理解和问答等一系列任务中评估模型。我们的方法包括针对零样本和少样本场景的严格实验设置,并采用准确率、F1分数、BLEU和ROUGE等指标进行性能评估。结果表明,Gemma 2在几乎所有任务和学习范式中都优于其他模型,尤其是在复杂的推理任务中表现出色。然而,大多数模型在命名实体识别等token级别理解任务中表现不佳,突出了波斯语处理中的具体挑战。这项研究为多语言LLM的研究做出了贡献,为它们在波斯语中的性能提供了有价值的见解,并为未来的模型开发提供了基准。
🔬 方法详解
问题定义:论文旨在评估开源大型语言模型在波斯语自然语言处理任务中的性能。现有方法缺乏对这些模型在波斯语上的系统性评估,尤其是在零样本和少样本学习场景下。这限制了我们对这些模型在低资源语言环境下的实际能力的理解,也阻碍了针对波斯语的LLM优化。
核心思路:论文的核心思路是通过构建一个全面的基准测试,评估多个开源LLM在各种波斯语NLP任务上的表现。通过比较不同模型在零样本和少样本学习设置下的性能,可以识别出哪些模型更适合波斯语处理,并揭示现有模型在哪些方面存在不足。这种评估为未来的模型开发和优化提供了有价值的指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的开源LLM进行评估;2) 选择一系列具有代表性的波斯语NLP任务,如情感分析、命名实体识别、阅读理解和问答;3) 使用已建立的波斯语数据集(如ParsiNLU和ArmanEmo)构建测试集;4) 在零样本和少样本学习设置下,对每个模型在每个任务上进行评估;5) 使用准确率、F1分数、BLEU和ROUGE等指标评估模型的性能;6) 分析实验结果,比较不同模型的性能,并识别出模型的优势和劣势。
关键创新:该研究的关键创新在于:1) 首次对多个开源LLM在波斯语NLP任务上进行了全面的基准测试;2) 采用了零样本和少样本学习范式,更真实地反映了模型在低资源语言环境下的性能;3) 使用了多个已建立的波斯语数据集,保证了评估的客观性和可比性;4) 详细分析了实验结果,为未来的模型开发和优化提供了有价值的指导。
关键设计:在实验设计方面,论文考虑了以下关键细节:1) 选择了具有代表性的开源LLM,包括Gemma 2等;2) 选择了涵盖不同NLP任务的波斯语数据集,以全面评估模型的性能;3) 在少样本学习设置中,精心设计了prompt,以提高模型的性能;4) 使用了标准的评估指标,如准确率、F1分数、BLEU和ROUGE,以保证评估结果的可比性。
🖼️ 关键图片

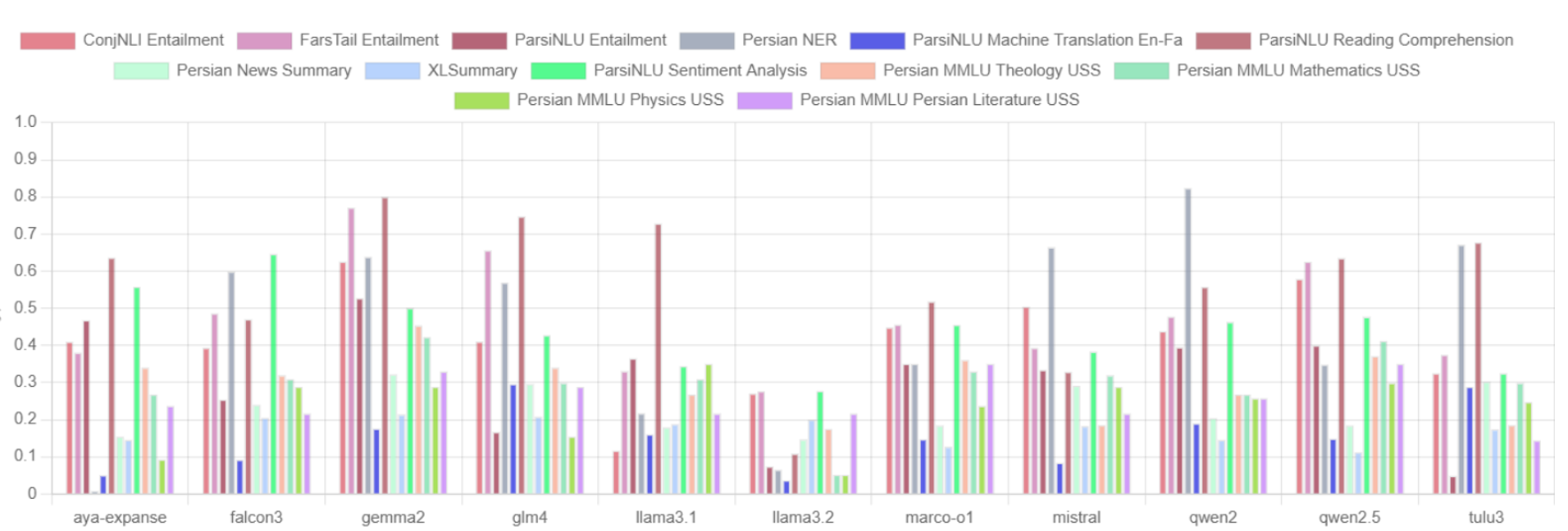
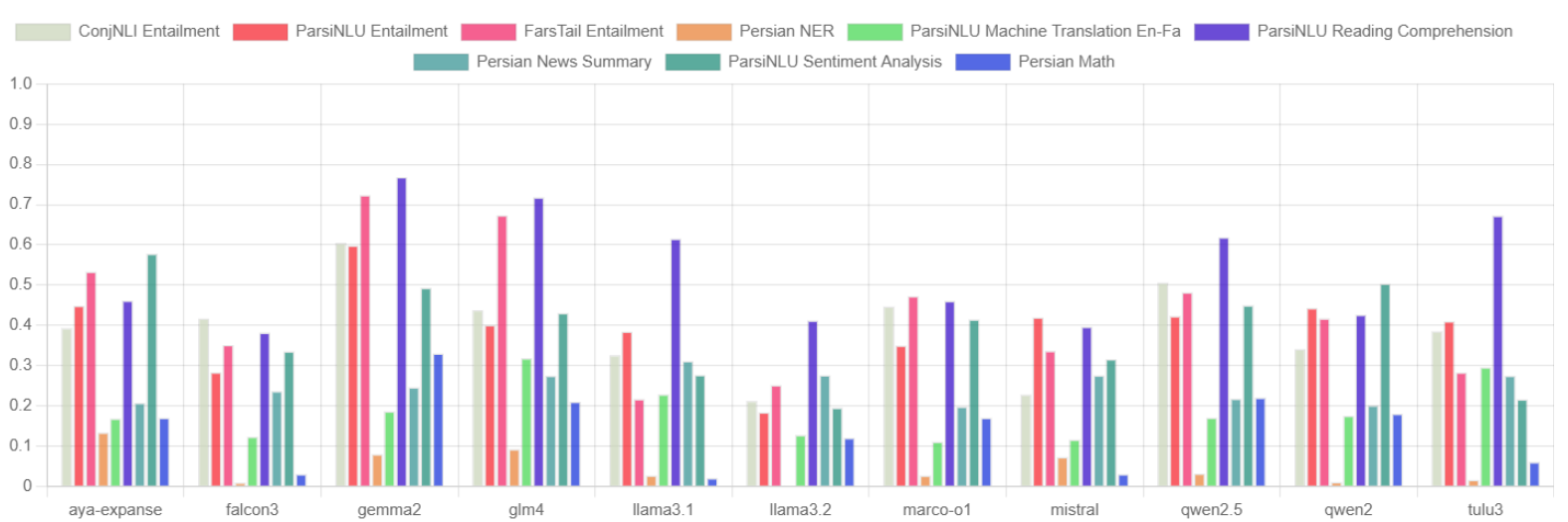
📊 实验亮点
实验结果表明,Gemma 2在多数任务中表现优于其他开源模型,尤其是在复杂推理任务上。然而,所有模型在命名实体识别等token级别理解任务上都表现不佳,这表明现有模型在处理波斯语的形态和句法复杂性方面仍存在挑战。该研究为未来波斯语LLM的开发指明了方向。
🎯 应用场景
该研究成果可应用于波斯语自然语言处理的多个领域,如情感分析、信息检索、机器翻译等。通过选择合适的预训练模型并进行微调,可以提升这些应用在波斯语环境下的性能。此外,该基准测试可以作为未来波斯语LLM开发的参考,促进相关技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous languages; however, their effectiveness in low-resource languages like Persian requires thorough investigation. This paper presents a comprehensive benchmark of several open-source LLMs for Persian Natural Language Processing (NLP) tasks, utilizing both zero-shot and few-shot learning paradigms. We evaluate models across a range of tasks including sentiment analysis, named entity recognition, reading comprehension, and question answering, using established Persian datasets such as ParsiNLU and ArmanEmo. Our methodology encompasses rigorous experimental setups for both zero-shot and few-shot scenarios, employing metrics such as Accuracy, F1-score, BLEU, and ROUGE for performance evaluation. The results reveal that Gemma 2 consistently outperforms other models across nearly all tasks in both learning paradigms, with particularly strong performance in complex reasoning tasks. However, most models struggle with token-level understanding tasks like Named Entity Recognition, highlighting specific challenges in Persian language processing. This study contributes to the growing body of research on multilingual LLMs, providing valuable insights into their performance in Persian and offering a benchmark for future model development.