Large Language Models Hallucination: A Comprehensive Survey
作者: Aisha Alansari, Hamzah Luqman
分类: cs.CL
发布日期: 2025-10-05 (更新: 2025-10-09)
💡 一句话要点
全面综述:剖析大语言模型幻觉现象的成因、检测与缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉现象 自然语言生成 错误检测 知识库
📋 核心要点
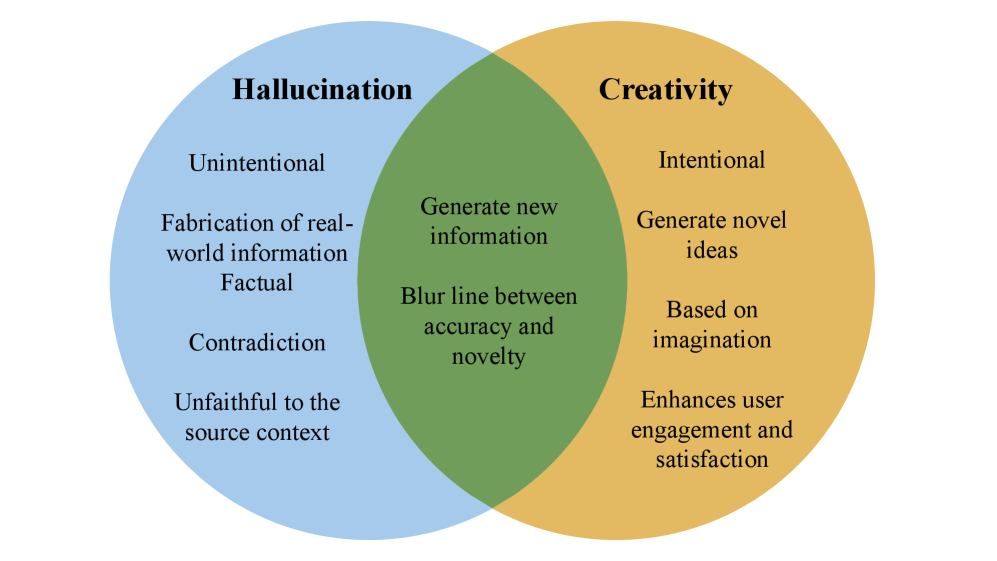
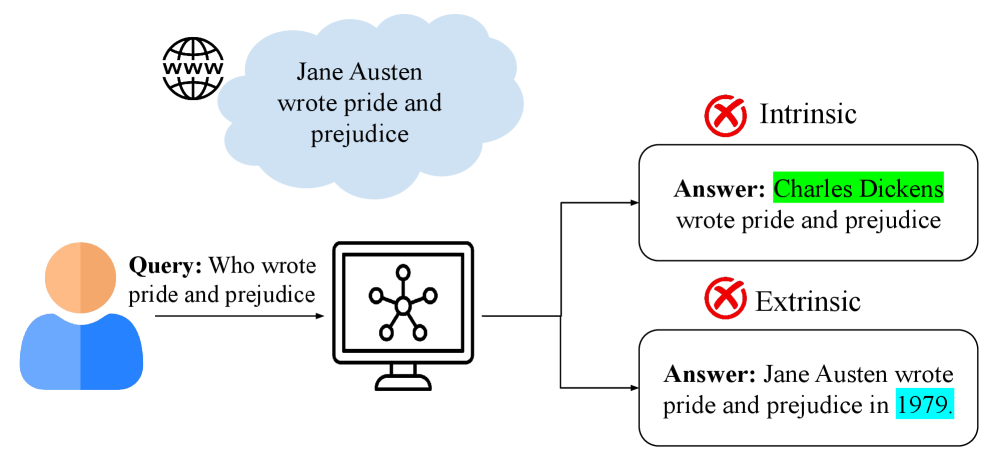
- 大型语言模型虽然在多种任务上表现出色,但其生成内容可能存在事实性错误,即“幻觉”问题,降低了模型的可信度。
- 该论文旨在全面分析LLM幻觉现象,从成因、检测到缓解策略,构建完整的理论框架,为后续研究提供指导。
- 论文不仅总结了现有的幻觉检测和缓解方法,还指出了当前方法的局限性,并展望了未来研究方向。
📝 摘要(中文)
大型语言模型(LLM)已经变革了自然语言处理领域,并在各种任务中取得了显著的性能。然而,它们令人印象深刻的流畅性往往以产生虚假或捏造的信息为代价,这种现象被称为幻觉。幻觉指的是LLM生成的内容流畅且语法正确,但事实不准确或缺乏外部证据支持。幻觉削弱了LLM的可靠性和可信度,尤其是在需要事实准确性的领域。本综述全面回顾了LLM中幻觉现象的研究,重点关注其原因、检测和缓解。我们首先提出了幻觉类型的分类,并分析了从数据收集和架构设计到推理的整个LLM开发生命周期中的根本原因。我们进一步研究了幻觉如何在关键的自然语言生成任务中出现。在此基础上,我们介绍了检测方法的结构化分类和缓解策略的分类。我们还分析了当前检测和缓解方法的优势和局限性,并回顾了用于量化LLM幻觉的现有评估基准和指标。最后,我们概述了关键的开放挑战和未来研究的有希望的方向,为开发更真实和可信的LLM奠定基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的“幻觉”问题,即模型生成的内容在语法上流畅,但在事实上不准确或缺乏证据支持。现有方法在检测和缓解幻觉方面存在局限性,例如检测方法不够全面,缓解策略效果有限,缺乏统一的评估标准。
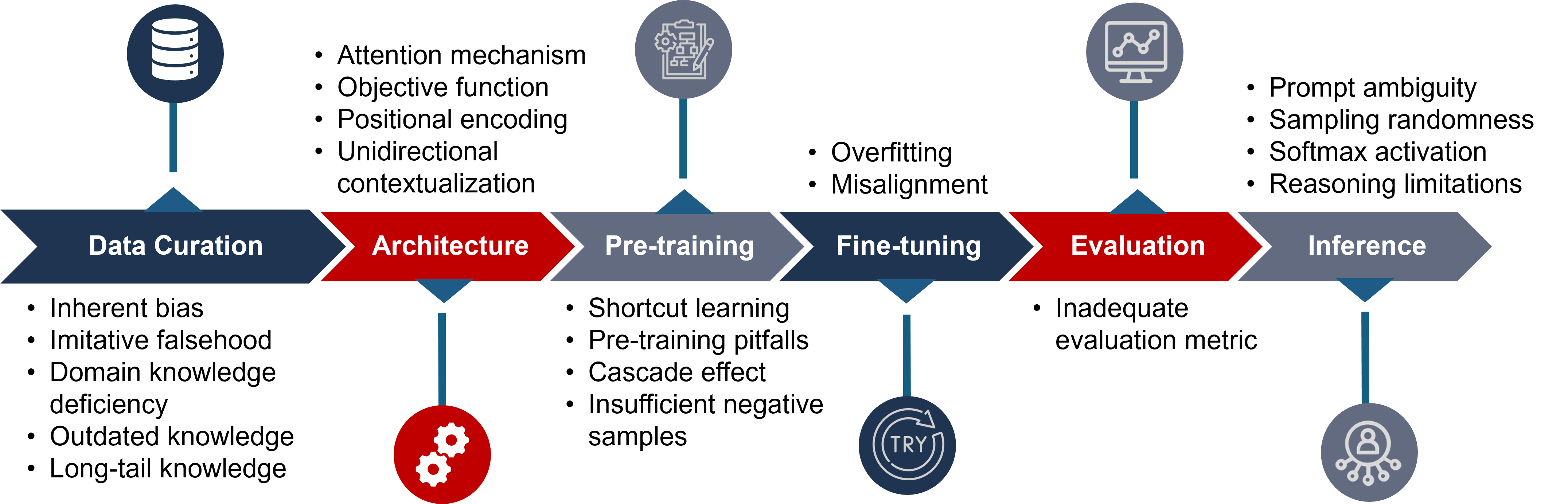
核心思路:论文的核心思路是对LLM幻觉现象进行系统性的梳理和分析,从幻觉的成因入手,深入探讨其在不同阶段(数据收集、模型训练、推理)的产生机制,并在此基础上,对现有的检测和缓解方法进行分类和评估,最终提出未来研究方向。
技术框架:论文构建了一个全面的LLM幻觉研究框架,主要包含以下几个部分:1) 幻觉类型分类:对不同类型的幻觉进行定义和区分;2) 幻觉成因分析:分析LLM开发生命周期中各个阶段可能导致幻觉的原因;3) 幻觉检测方法分类:对现有的幻觉检测方法进行归类和总结;4) 幻觉缓解策略分类:对现有的幻觉缓解策略进行归类和总结;5) 评估基准和指标:回顾用于量化LLM幻觉的现有评估基准和指标。
关键创新:论文的主要创新在于其系统性和全面性。它不仅对LLM幻觉现象进行了深入的分析,还构建了一个完整的理论框架,为后续研究提供了指导。与现有研究相比,该论文更加注重对幻觉成因的分析,并对现有的检测和缓解方法进行了更加细致的分类和评估。
关键设计:论文没有提出新的算法或模型,而是一个综述性的工作。其关键设计在于对现有研究的组织和分类方式,例如,根据LLM开发生命周期的不同阶段来分析幻觉的成因,以及根据不同的技术原理来对检测和缓解方法进行分类。此外,论文还对现有的评估基准和指标进行了回顾,为未来的研究提供了参考。
🖼️ 关键图片
📊 实验亮点
该论文是一篇全面的综述性文章,系统地总结了LLM幻觉现象的研究进展,并对现有的检测和缓解方法进行了分类和评估。虽然没有提供具体的性能数据,但它为研究人员提供了一个清晰的全局视角,并指出了未来研究的重点方向,具有重要的参考价值。
🎯 应用场景
该研究成果可应用于提升大语言模型在各个领域的可靠性和可信度,例如在医疗诊断、金融分析、法律咨询等对准确性要求极高的领域。通过深入理解幻觉的成因并采用有效的检测和缓解策略,可以减少模型产生错误信息的风险,从而更好地服务于人类社会。
📄 摘要(原文)
Large language models (LLMs) have transformed natural language processing, achieving remarkable performance across diverse tasks. However, their impressive fluency often comes at the cost of producing false or fabricated information, a phenomenon known as hallucination. Hallucination refers to the generation of content by an LLM that is fluent and syntactically correct but factually inaccurate or unsupported by external evidence. Hallucinations undermine the reliability and trustworthiness of LLMs, especially in domains requiring factual accuracy. This survey provides a comprehensive review of research on hallucination in LLMs, with a focus on causes, detection, and mitigation. We first present a taxonomy of hallucination types and analyze their root causes across the entire LLM development lifecycle, from data collection and architecture design to inference. We further examine how hallucinations emerge in key natural language generation tasks. Building on this foundation, we introduce a structured taxonomy of detection approaches and another taxonomy of mitigation strategies. We also analyze the strengths and limitations of current detection and mitigation approaches and review existing evaluation benchmarks and metrics used to quantify LLMs hallucinations. Finally, we outline key open challenges and promising directions for future research, providing a foundation for the development of more truthful and trustworthy LLMs.