Probing Geometry of Next Token Prediction Using Cumulant Expansion of the Softmax Entropy
作者: Karthik Viswanathan, Sang Eon Park
分类: cs.CL, cond-mat.stat-mech, cs.LG, stat.ML
发布日期: 2025-10-05
备注: 14 pages, 7 figures. Poster at HiLD 2025: 3rd Workshop on High-dimensional Learning Dynamics
💡 一句话要点
提出基于累积量展开的框架,用于探究LLM预测下一个token时的几何结构。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 累积量展开 统计结构 特征学习 下一个token预测
📋 核心要点
- 现有方法难以有效量化LLM在token预测中学习到的高阶统计结构。
- 该论文提出累积量展开框架,将softmax熵视为中心分布的扰动,推导闭式累积量观测值。
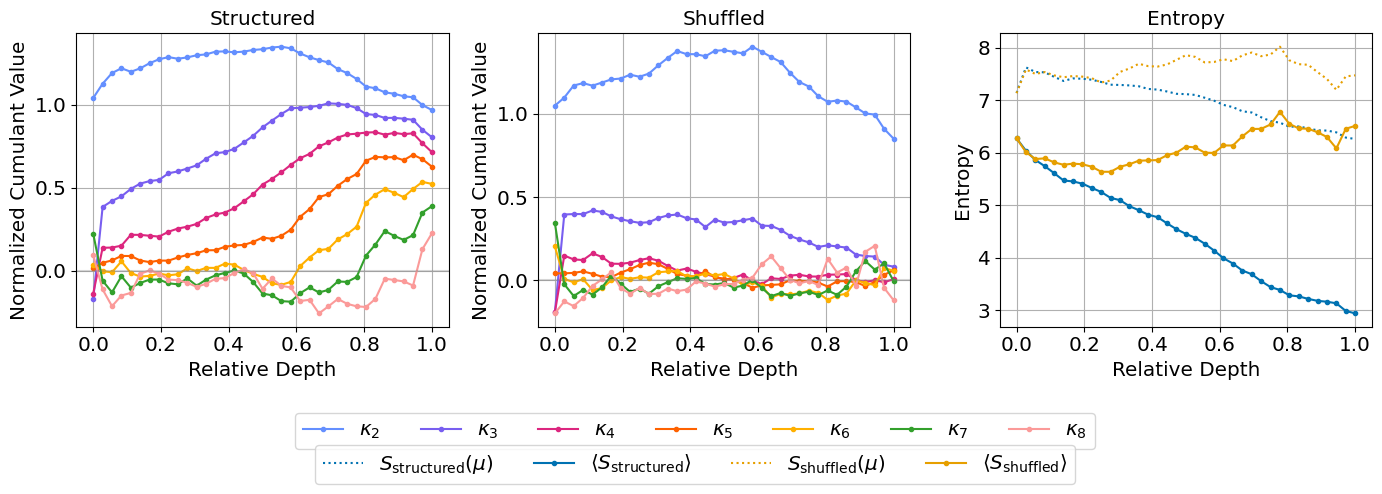
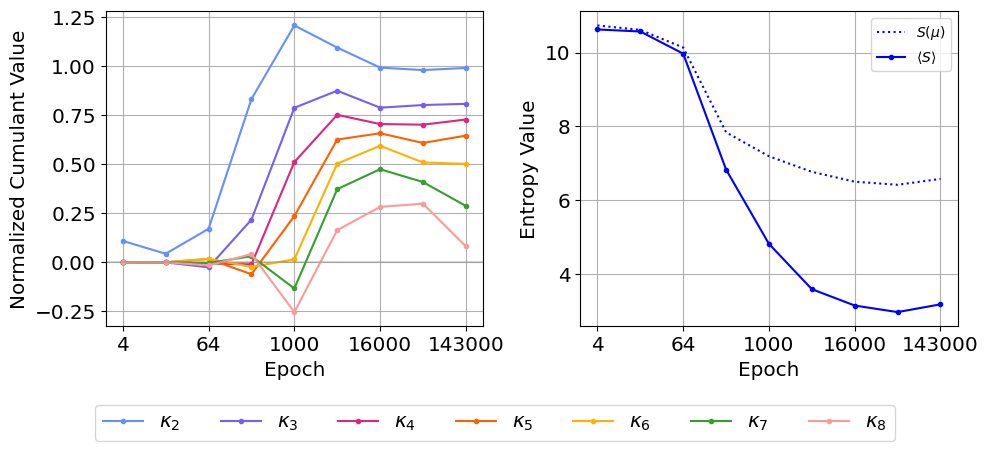
- 实验表明,累积量能有效区分结构化和随机提示,并揭示模型训练过程中学习高阶统计的进程。
📝 摘要(中文)
本文提出了一种累积量展开框架,用于量化大型语言模型(LLM)在下一个token预测过程中如何内化高阶统计结构。通过将每一层logit分布的softmax熵视为其“中心”分布周围的扰动,我们推导出闭式累积量观测值,从而分离出连续的高阶相关性。在实验中,我们在Pile-10K提示上跟踪GPT-2和Pythia模型中的这些累积量。(i) 结构化提示表现出跨层级的特征性上升和稳定曲线,而token被打乱的提示则保持平坦,揭示了累积量曲线对有意义上下文的依赖性。(ii) 在训练过程中,所有累积量单调增加,然后饱和,直接可视化了模型从捕获方差到学习偏度、峰度和更高阶统计结构的进展。(iii) 与一般文本相比,数学提示显示出不同的累积量特征,量化了模型如何对数学内容与语言内容采用根本不同的处理机制。总之,这些结果将累积量分析确立为一种轻量级的、数学上可靠的探针,用于研究高维神经网络中的特征学习动态。
🔬 方法详解
问题定义:大型语言模型在进行下一个token预测时,如何有效地理解和利用输入文本中的高阶统计信息是一个关键问题。现有的方法往往难以直接量化模型内部对这些高阶统计结构的捕获程度,缺乏一种轻量级且易于解释的分析工具。
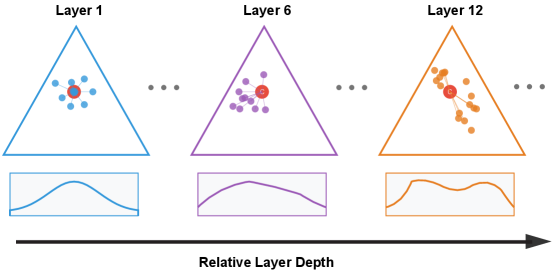
核心思路:本文的核心思路是将每一层softmax输出的熵看作是围绕一个中心分布的扰动,然后利用累积量展开来提取不同阶数的统计信息。这种方法能够将高阶相关性从模型的输出中分离出来,从而更好地理解模型学习到的统计结构。
技术框架:该方法主要包含以下几个步骤:首先,计算每一层logit分布的softmax熵。然后,将该熵视为围绕中心分布的扰动,并进行累积量展开。通过闭式公式计算不同阶数的累积量,这些累积量反映了不同阶数的统计相关性。最后,分析这些累积量在不同层、不同输入和不同训练阶段的变化,从而理解模型的学习动态。
关键创新:该方法最重要的创新点在于利用累积量展开来探究LLM内部对高阶统计信息的学习。与传统的分析方法相比,累积量展开能够提供更细粒度的信息,并且具有明确的数学解释。此外,该方法是轻量级的,易于计算和分析。
关键设计:关键设计包括:(1) 使用softmax熵作为扰动的基础,因为它直接反映了模型输出分布的不确定性。(2) 推导闭式累积量公式,使得计算效率高。(3) 通过实验验证了该方法在不同模型、不同数据集和不同任务上的有效性。没有特别提及损失函数或网络结构,因为该方法主要关注的是对现有模型的分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结构化提示的累积量曲线呈现上升和稳定趋势,而随机提示则保持平坦,验证了累积量对上下文的敏感性。训练过程中,累积量单调增加并饱和,可视化了模型学习高阶统计的过程。数学提示与一般文本的累积量特征不同,揭示了模型对不同类型内容的差异化处理。
🎯 应用场景
该研究成果可应用于分析和理解大型语言模型的内部工作机制,诊断模型在处理不同类型文本时的能力差异,并指导模型训练,使其更好地学习和利用高阶统计信息。此外,该方法还可以用于评估模型的鲁棒性和泛化能力。
📄 摘要(原文)
We introduce a cumulant-expansion framework for quantifying how large language models (LLMs) internalize higher-order statistical structure during next-token prediction. By treating the softmax entropy of each layer's logit distribution as a perturbation around its "center" distribution, we derive closed-form cumulant observables that isolate successively higher-order correlations. Empirically, we track these cumulants in GPT-2 and Pythia models on Pile-10K prompts. (i) Structured prompts exhibit a characteristic rise-and-plateau profile across layers, whereas token-shuffled prompts remain flat, revealing the dependence of the cumulant profile on meaningful context. (ii) During training, all cumulants increase monotonically before saturating, directly visualizing the model's progression from capturing variance to learning skew, kurtosis, and higher-order statistical structures. (iii) Mathematical prompts show distinct cumulant signatures compared to general text, quantifying how models employ fundamentally different processing mechanisms for mathematical versus linguistic content. Together, these results establish cumulant analysis as a lightweight, mathematically grounded probe of feature-learning dynamics in high-dimensional neural networks.