Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought
作者: Guijin Son, Donghun Yang, Hitesh Laxmichand Patel, Amit Agarwal, Hyunwoo Ko, Chanuk Lim, Srikant Panda, Minhyuk Kim, Nikunj Drolia, Dasol Choi, Kyong-Ha Lee, Youngjae Yu
分类: cs.CL
发布日期: 2025-10-05 (更新: 2026-01-13)
备注: Work in Progress
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出Language-Mixed CoT,提升多语言推理模型在韩语等场景下的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 Chain-of-Thought 语言模型 韩语 数据集构建
📋 核心要点
- 现有工作主要集中在英语推理模型上,缺乏对特定语言推理能力的研究,阻碍了多语言环境下的应用。
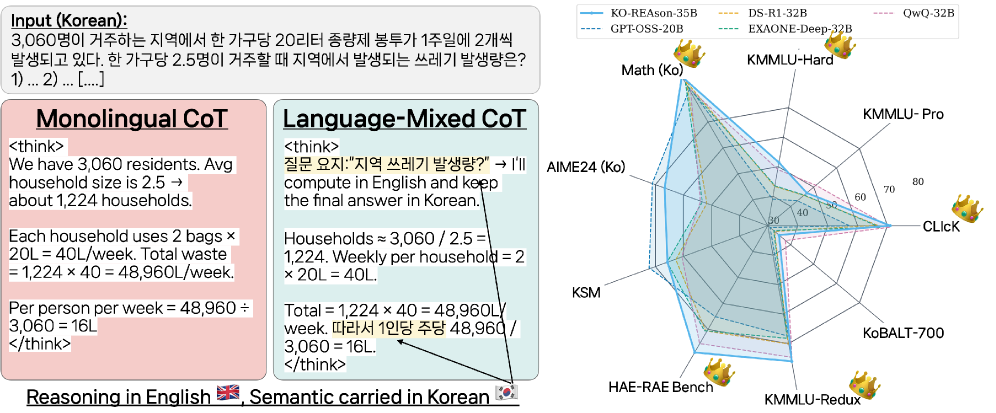
- 提出Language-Mixed CoT,通过在英语和目标语言间切换,利用英语作为推理锚点,减少翻译偏差,提升推理效果。
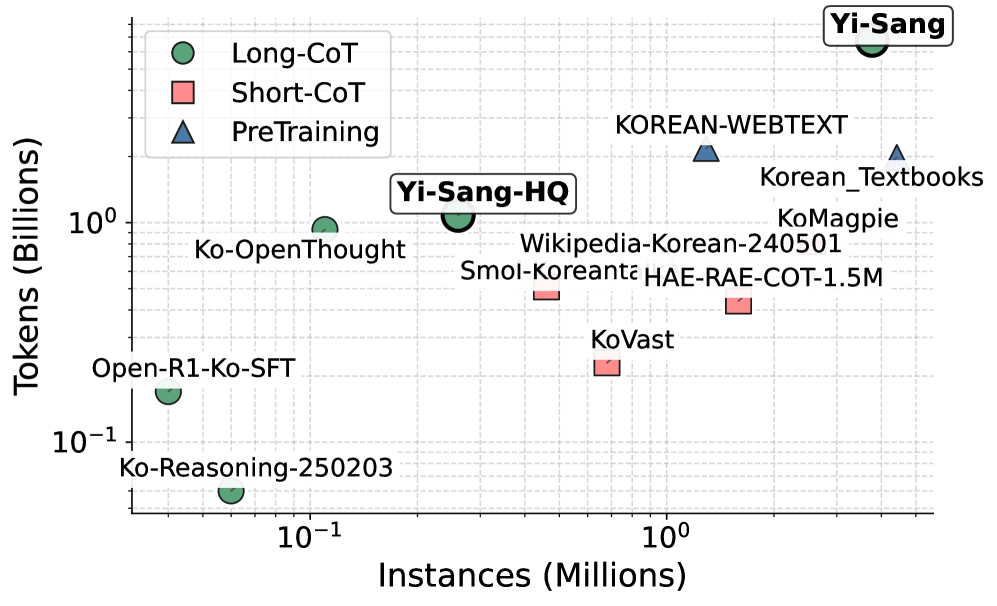
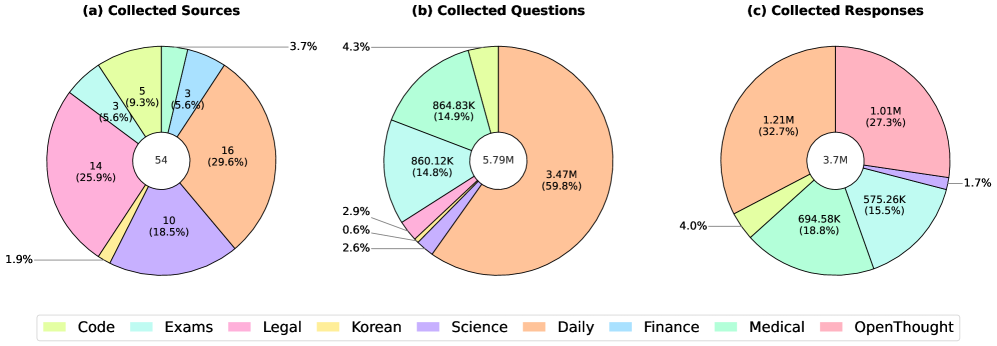
- 构建了大规模韩语数据集Yi-Sang,并训练了KO-REAson模型,在多个基准测试中取得了显著的性能提升。
📝 摘要(中文)
为了提升多语言推理模型的能力,本文提出了一种新的推理模式:Language-Mixed CoT。该模式在英语和目标语言之间切换,利用英语作为桥梁,在推理过程中最大程度地减少翻译带来的偏差。以韩语为例,作者构建了一个名为Yi-Sang的大规模数据集,包含579万个韩语原生问题,涵盖网络问答、考试、STEM和代码等领域,以及370万条由Qwen3-32B生成的长推理轨迹,并从中筛选出26万条高质量子集。基于此,作者训练了9个模型(4B-35B),涵盖Qwen2.5、Llama-3.1、Gemma-3等六个模型家族。实验结果表明,最佳模型KO-REAson-35B取得了state-of-the-art的性能,在9个基准测试中,总体平均分最高(64.0 ± 25),在5个基准测试中排名第一,其余排名第二。较小的模型也受益匪浅,在9个基准测试中平均提升了+18.6分。消融实验表明,Language-Mixed CoT比单语CoT更有效,并且能够提升跨语言和多模态性能。作者开源了数据收集流程、评估系统、数据集和模型,以促进语言特定推理的研究。
🔬 方法详解
问题定义:论文旨在解决多语言推理模型在非英语环境下的性能瓶颈问题。现有方法,特别是依赖翻译的策略,容易引入翻译噪声,影响推理的准确性。此外,缺乏高质量的非英语推理数据集也限制了模型的发展。
核心思路:论文的核心思路是利用英语作为中间语言,构建Language-Mixed Chain-of-Thought (CoT) 推理模式。通过在英语和目标语言之间灵活切换,模型可以在英语的语义空间中进行推理,同时利用目标语言的上下文信息,从而减少翻译带来的信息损失和偏差。
技术框架:整体框架包括数据收集与构建、模型训练和评估三个主要阶段。首先,构建大规模的韩语数据集Yi-Sang,包含多种来源的韩语问题和对应的推理轨迹。然后,基于该数据集,训练不同规模的语言模型,并采用Language-Mixed CoT进行微调。最后,在多个基准测试上评估模型的性能,并与现有方法进行比较。
关键创新:最重要的技术创新点在于Language-Mixed CoT推理模式。与传统的单语CoT或直接翻译的CoT方法不同,Language-Mixed CoT允许模型在推理过程中动态地选择使用英语或目标语言,从而更好地平衡推理的准确性和效率。
关键设计:在数据构建方面,作者精心挑选了多种来源的韩语数据,并使用Qwen3-32B模型生成推理轨迹,然后进行筛选和过滤,以保证数据的质量。在模型训练方面,作者尝试了多种不同的模型架构和训练策略,并对Language-Mixed CoT的切换频率和策略进行了调整,以获得最佳的性能。
🖼️ 关键图片
📊 实验亮点
KO-REAson-35B模型在9个基准测试中取得了state-of-the-art的性能,总体平均分最高(64.0 ± 25),在5个基准测试中排名第一,其余排名第二。与单语CoT相比,Language-Mixed CoT带来了显著的性能提升,并且能够提升跨语言和多模态性能。较小的模型也受益匪浅,在9个基准测试中平均提升了+18.6分。
🎯 应用场景
该研究成果可应用于多语言智能客服、跨语言信息检索、多语言教育等领域。通过提升模型在特定语言环境下的推理能力,可以更好地服务于不同语言的用户,促进全球范围内的信息交流和知识共享。未来,该方法可以推广到其他语言,构建更加通用和强大的多语言推理模型。
📄 摘要(原文)
Recent frontier models employ long chain-of-thought reasoning to explore solution spaces in context and achieve stonger performance. While many works study distillation to build smaller yet capable models, most focus on English and little is known about language-specific reasoning. To bridge this gap, we first introduct Language-Mixed CoT, a reasoning schema that switches between English and a target language, using English as an anchor to excel in reasoning while minimizing translation artificats. As a Korean case study, we curate Yi-Sang: 5.79M native-Korean prompts from web Q&A, exams, STEM, and code; 3.7M long reasoning traces generated from Qwen3-32B; and a targeted 260k high-yield subset. We train ninve models (4B-35B) across six families (Qwen2.5, Llama-3.1, Gemma-3, etc). Our best model, KO-REAson-35B, achieves state-of-the-art performance, with the highest overall average score (64.0 \pm 25), ranking first on 5/9 benchmarks and second on the remainder. Samller and mid-sized models also benefit substantially, with an average improvement of +18.6 points across teh evaluated nine benchmarks. Ablations show Language-Mixed CoT is more effective than monolingual CoT, also resulting in cross-lingual and mult-modal performance gains. We release our data-curation pipeline, evaluation system, datasets, and models to advance research on language-specific reasoning. Data and model collection: https://huggingface.co/KOREAson.