Teaching LLM to be Persuasive: Reward-Enhanced Policy Optimization for Alignment frm Heterogeneous Rewards
作者: Zhuoran Zhuang, Ye Chen, Xia Zeng, Chao Luo, Luhui Liu, Yihan Chen
分类: cs.CL
发布日期: 2025-10-05 (更新: 2025-10-11)
💡 一句话要点
提出REPO框架,通过异构奖励优化LLM,提升在线旅游议价场景的说服力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 奖励模型 策略优化 在线议价 商务拓展 异构奖励 人机协作
📋 核心要点
- 现有LLM在在线旅游议价场景中,难以兼顾说服力、业务约束和对话流畅性,易过拟合且缺乏对细微风格的把握。
- REPO框架结合偏好训练奖励模型、奖励判断器和程序化奖励函数,从多维度对齐LLM,提升其说服能力和合规性。
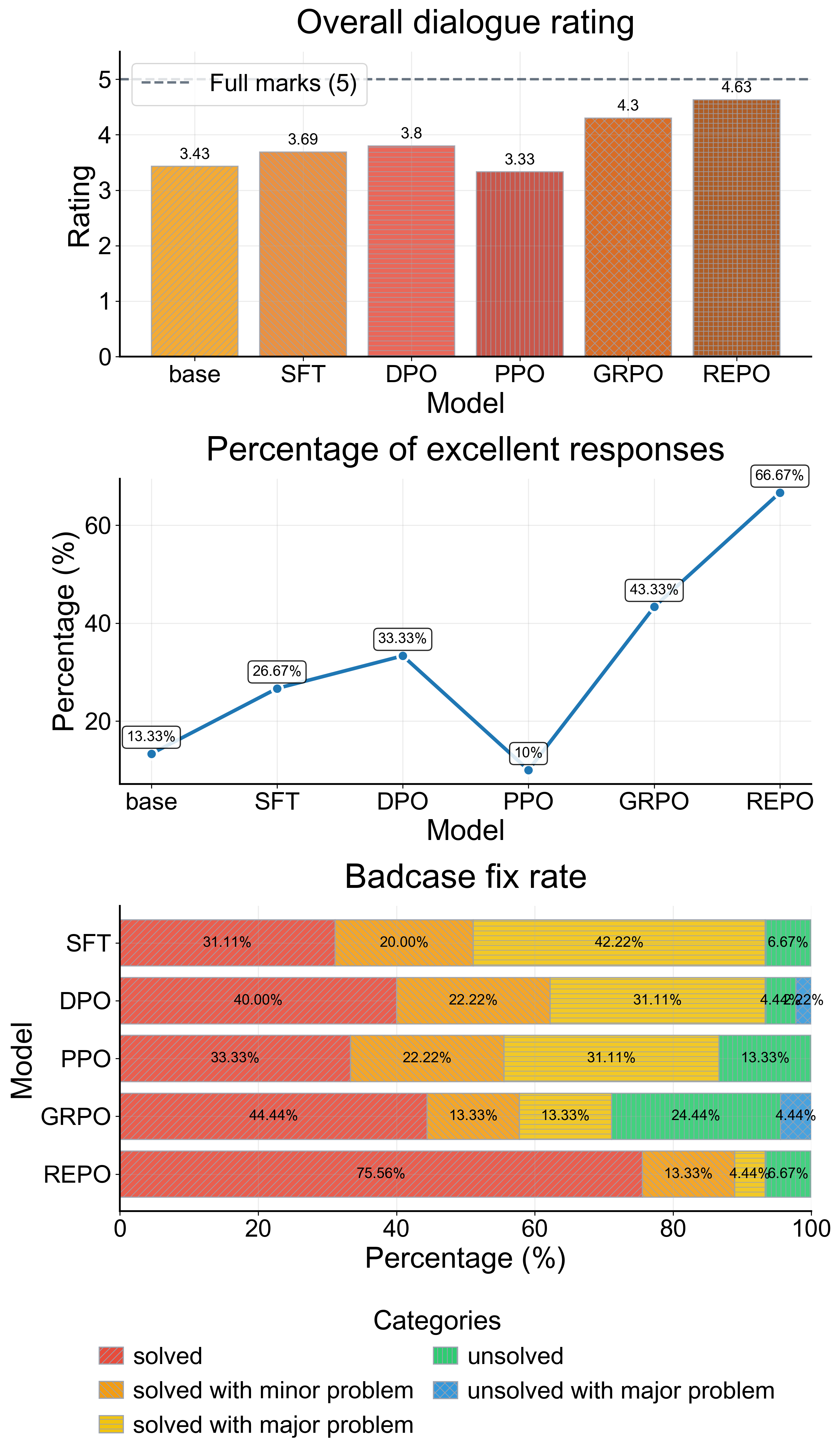
- 实验表明,REPO在对话质量、优秀回复比例和坏案例修复率上均显著优于SFT、DPO、PPO和GRPO等基线方法。
📝 摘要(中文)
本文研究如何部署大型语言模型(LLM)作为商务拓展(BD)代理,用于在线旅游平台(OTA)中具有说服力的价格谈判。对旅行者可负担性和酒店盈利能力的平衡直接影响预订量、合作关系和旅游渠道。代理需要遵循标准操作程序(SOP)进行多轮说服,理解口语化输入,并遵守护栏(如不过度承诺、不产生幻觉)。传统的后训练方法,如监督微调(SFT)或单源奖励优化,容易过拟合脚本,忽略细微的说服风格,并且无法强制执行可验证的业务约束。因此,本文提出奖励增强策略优化(REPO),这是一个强化学习后训练框架,它使用异构奖励来对齐LLM:一个用于密集人类对齐的偏好训练奖励模型(RM),一个用于高级说服行为和SOP合规性的奖励判断器(RJ),以及用于数值、格式和护栏的确定性检查的程序化奖励函数(RF)。提出了一种直接的增强机制,将RM与RJ和RF信号相结合,以抑制奖励利用并提高谈判质量。在生产式评估中(约150轮来自真实对话,225轮来自精选的坏案例对话),REPO将平均对话评分提升至4.63(相比基线+1.20,相比直接偏好优化(DPO)+0.83,相比群体相对策略优化(GRPO)+0.33),将至少包含一个优秀回复的对话比例提高到66.67%(相比GRPO提高23.34个百分点),并实现了93.33%的坏案例修复率,其中75.56%是干净的修复,优于SFT、DPO、PPO和GRPO。我们还观察到涌现的能力,如主动同理心、本地化推理、校准策略,这些能力超越了黄金标注。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在在线旅游议价场景中,作为商务拓展(BD)代理时,难以同时满足说服力、遵循标准操作程序(SOP)和遵守业务约束的问题。现有方法,如监督微调(SFT)和单源奖励优化,容易过拟合训练数据,忽略细微的说服风格,并且无法有效地执行可验证的业务规则,导致实际应用效果不佳。
核心思路:论文的核心思路是利用异构奖励信号来对齐LLM,从而克服现有方法的局限性。具体来说,通过结合偏好训练奖励模型(RM)、奖励判断器(RJ)和程序化奖励函数(RF),从不同维度评估LLM的输出,并利用这些奖励信号来指导LLM的策略优化。这种多维度奖励机制能够更全面地捕捉人类偏好、业务规则和对话质量,从而提升LLM的说服能力和合规性。
技术框架:REPO(Reward-Enhanced Policy Optimization)框架包含以下主要模块:1) 偏好训练奖励模型(RM):用于学习人类对不同对话回复的偏好,提供密集的奖励信号。2) 奖励判断器(RJ):用于评估LLM是否遵循标准操作程序(SOP)以及是否表现出高级的说服行为。3) 程序化奖励函数(RF):用于执行确定性的检查,例如数值、格式和业务护栏(如不过度承诺、不产生幻觉)。4) 奖励增强机制:将RM、RJ和RF的奖励信号进行组合,以抑制奖励利用并提高谈判质量。5) 策略优化:使用强化学习算法(如PPO或DPO)来优化LLM的策略,使其能够最大化累积奖励。
关键创新:REPO框架的关键创新在于其异构奖励机制和奖励增强机制。传统的奖励优化方法通常只使用单一的奖励信号,容易导致LLM过度优化该信号,而忽略其他重要的因素。REPO框架通过结合多种奖励信号,能够更全面地评估LLM的输出,从而提升其说服能力和合规性。奖励增强机制则进一步抑制了奖励利用,提高了谈判质量。
关键设计:奖励增强机制是REPO框架的关键设计之一。具体来说,该机制通过加权平均的方式将RM、RJ和RF的奖励信号进行组合。权重可以根据不同的任务和场景进行调整,以平衡不同奖励信号的重要性。此外,为了防止LLM过度依赖某些奖励信号,可以引入正则化项,惩罚LLM对这些信号的过度优化。具体的损失函数和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
REPO在生产式评估中表现出色,平均对话评分提升至4.63,相比基线提升显著(+1.20 vs base, +0.83 vs DPO, +0.33 vs GRPO)。同时,至少包含一个优秀回复的对话比例提高到66.67%(相比GRPO提高23.34个百分点),并实现了93.33%的坏案例修复率,其中75.56%是干净的修复,优于其他基线方法。
🎯 应用场景
该研究成果可广泛应用于在线客服、商务谈判、销售推广等领域。通过提升LLM的说服能力和合规性,可以有效提高用户满意度、促进业务增长,并降低潜在的风险。未来,该方法有望扩展到其他需要人机协作的场景,例如医疗咨询、法律服务等。
📄 摘要(原文)
We study deploying large language models (LLMs) as business development (BD) agents for persuasive price negotiation in online travel agencies (OTAs), where aligning traveler affordability and hotel profitability directly affects bookings, partner relationships, and access to travel. The agent must follow a Standard Operating Procedure (SOP) while conducting multi-turn persuasion, interpreting colloquial inputs, and adhering to guardrails (no over-promising, no hallucinations). Conventional post-training -- supervised fine-tuning (SFT) or single-source reward optimization -- overfits scripts, misses nuanced persuasive style, and fails to enforce verifiable business constraints. We propose Reward-Enhanced Policy Optimization (REPO), a reinforcement learning post-training framework that aligns an LLM with heterogeneous rewards: a preference-trained reward model (RM) for dense human alignment, a reward judge (RJ) for high-level persuasive behavior and SOP compliance, and programmatic reward functions (RF) for deterministic checks on numerics, formatting, and guardrails. A straightforward enhancement mechanism is proposed to combine the RM with RJ and RF signals to curb reward hacking and improve negotiation quality. In production-style evaluations -- approximately 150 turns from real dialogues and 225 turns from curated bad-case dialogues -- REPO lifts average dialogue rating to 4.63: +1.20 over base, +0.83 over Direct Preference Optimization (DPO); +0.33 over Group Relative Policy Optimization (GRPO), increases the share of conversations with at least one excellent response to 66.67% (+23.34 percentage points over GRPO), and achieves a 93.33% bad-case fix rate with 75.56% clean fixes, outperforming SFT, DPO, PPO, and GRPO. We also observe emergent capabilities -- proactive empathy, localized reasoning, calibrated tactics -- that surpass gold annotations.