Self Speculative Decoding for Diffusion Large Language Models
作者: Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, Linfeng Zhang
分类: cs.CL
发布日期: 2025-10-05
💡 一句话要点
提出自推测解码(SSD)加速扩散大语言模型推理,无需额外模块。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 推理加速 推测解码 并行生成
📋 核心要点
- 现有扩散大语言模型的并行解码偏离逐步解码,导致性能下降,限制了实际应用。
- 提出自推测解码(SSD),利用模型自身进行草稿生成和验证,无需额外模块,降低冗余。
- 实验表明,SSD在保证输出质量的前提下,实现了高达3.46倍的推理加速效果。
📝 摘要(中文)
基于扩散的大语言模型(dLLMs)作为自回归模型的有力竞争者,通过双向注意力机制和并行生成范式提供了独特的优势。然而,当前并行解码方法的结果偏离了逐步解码,导致潜在的性能下降,限制了它们的实际部署。为了解决这个问题,我们提出了自推测解码(SSD),这是一种无损的推理加速方法,它利用dLLM本身作为推测解码的起草者和验证者,而无需辅助模块。SSD引入了一种自起草机制,模型生成多个位置的预测,然后通过分层验证树在单个前向传递中验证它们。与需要单独草稿模型的传统推测解码不同,SSD通过利用dLLM固有的并行预测多个位置的能力,消除了模型冗余和内存开销。这种自推测方法允许模型在单个前向传递中逐步验证和接受多个token。我们的实验表明,在LLaDA和Dream等开源模型上,SSD实现了高达3.46倍的加速,同时保持输出与逐步解码相同。代码将在GitHub上公开。
🔬 方法详解
问题定义:论文旨在解决扩散大语言模型(dLLMs)并行解码时,由于偏离逐步解码而导致的性能下降问题。现有并行解码方法虽然提高了生成速度,但牺牲了生成质量,限制了dLLMs的实际应用。传统推测解码方法需要额外的草稿模型,增加了模型冗余和内存开销。
核心思路:论文的核心思路是利用dLLM自身的能力,同时作为推测解码的草稿生成器和验证器。通过让模型并行预测多个位置的token,并使用分层验证树进行验证,从而在单个前向传递中接受多个token。这种“自推测”的方式避免了引入额外的模型,降低了资源消耗,同时保持了生成质量。
技术框架:SSD的核心流程包括自起草和分层验证两个阶段。在自起草阶段,dLLM并行预测多个位置的token,形成一个候选序列。然后,通过分层验证树,逐层验证这些候选token的正确性。验证过程利用dLLM自身的预测能力,无需外部模型。被验证为正确的token将被接受,并用于后续的生成过程。
关键创新:SSD最重要的创新在于其“自推测”的特性,即利用dLLM自身作为草稿生成器和验证器。这与传统的推测解码方法不同,后者需要额外的草稿模型。通过消除模型冗余,SSD降低了内存开销,并简化了推理流程。此外,分层验证树的设计也提高了验证效率。
关键设计:SSD的关键设计包括:1) 自起草机制,决定了并行预测的token数量;2) 分层验证树的结构,影响验证效率;3) 验证阈值的设置,平衡了加速效果和生成质量。论文可能还涉及一些与特定dLLM架构相关的参数设置,但摘要中未明确提及。
🖼️ 关键图片
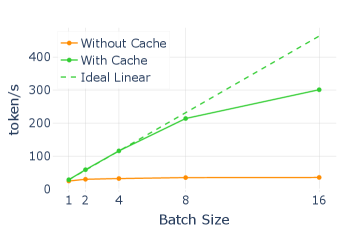
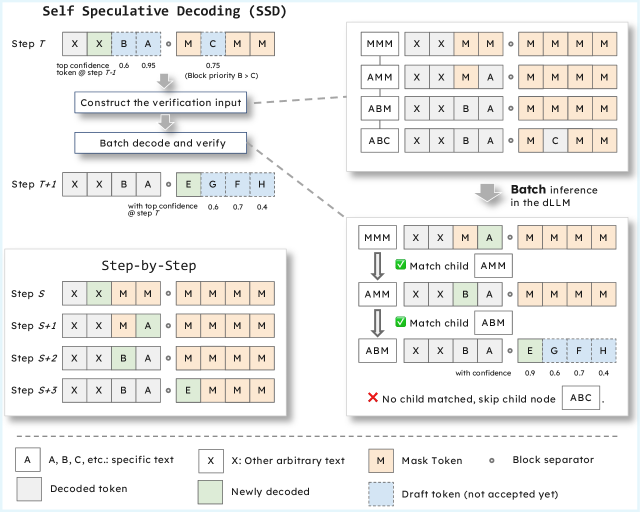
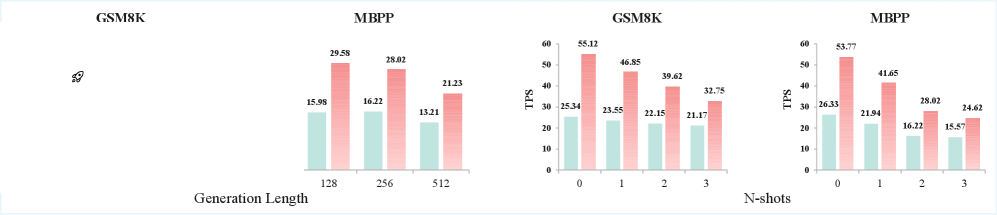
📊 实验亮点
实验结果表明,SSD在LLaDA和Dream等开源模型上实现了高达3.46倍的推理加速,同时保持了与逐步解码相同的输出质量。这意味着SSD能够在不牺牲生成质量的前提下,显著提高dLLMs的推理效率,具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种基于扩散模型的大语言模型推理加速场景,例如文本生成、机器翻译、对话系统等。通过提高推理效率,SSD能够降低计算成本,并提升用户体验,使得dLLMs更容易部署在资源受限的设备上,例如移动设备和边缘服务器。未来,该技术有望推动dLLMs在更多实际应用场景中的普及。
📄 摘要(原文)
Diffusion-based Large Language Models (dLLMs) have emerged as a competitive alternative to autoregressive models, offering unique advantages through bidirectional attention and parallel generation paradigms. However, the generation results of current parallel decoding methods deviate from stepwise decoding, introducing potential performance degradation, which limits their practical deployment. To address this problem, we propose \textbf{S}elf \textbf{S}peculative \textbf{D}ecoding (SSD), a lossless inference acceleration method that leverages the dLLM itself as both speculative decoding drafter and verifier without auxiliary modules. SSD introduces a self-drafting mechanism where the model generates predictions for multiple positions, then verifies them through hierarchical verification trees in a single forward pass. Unlike traditional speculative decoding that requires separate draft models, SSD eliminates model redundancy and memory overhead by exploiting the dLLM's inherent parallel prediction capability for multiple positions. This self-speculative approach allows the model to progressively verify and accept multiple tokens in a single forward pass. Our experiments demonstrate that SSD achieves up to 3.46$\times$ speedup while keeping the output identical to stepwise decoding on open source models such as LLaDA and Dream. Code will be made publicly available on GitHub.