Exploring Chain-of-Thought Reasoning for Steerable Pluralistic Alignment
作者: Yunfan Zhang, Kathleen McKeown, Smaranda Muresan
分类: cs.CL, cs.LG
发布日期: 2025-10-05
备注: ACL EMNLP 2025
💡 一句话要点
探索思维链推理以实现可控的多元化对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链推理 可控多元化 强化学习 价值观对齐
📋 核心要点
- 现有大型语言模型在处理需要细致人类视角的任务时存在局限性,因为它们通常被训练成反映统一的价值观。
- 该研究探索了思维链(CoT)推理技术,旨在构建能够采纳特定视角并生成对齐输出的可控多元化模型。
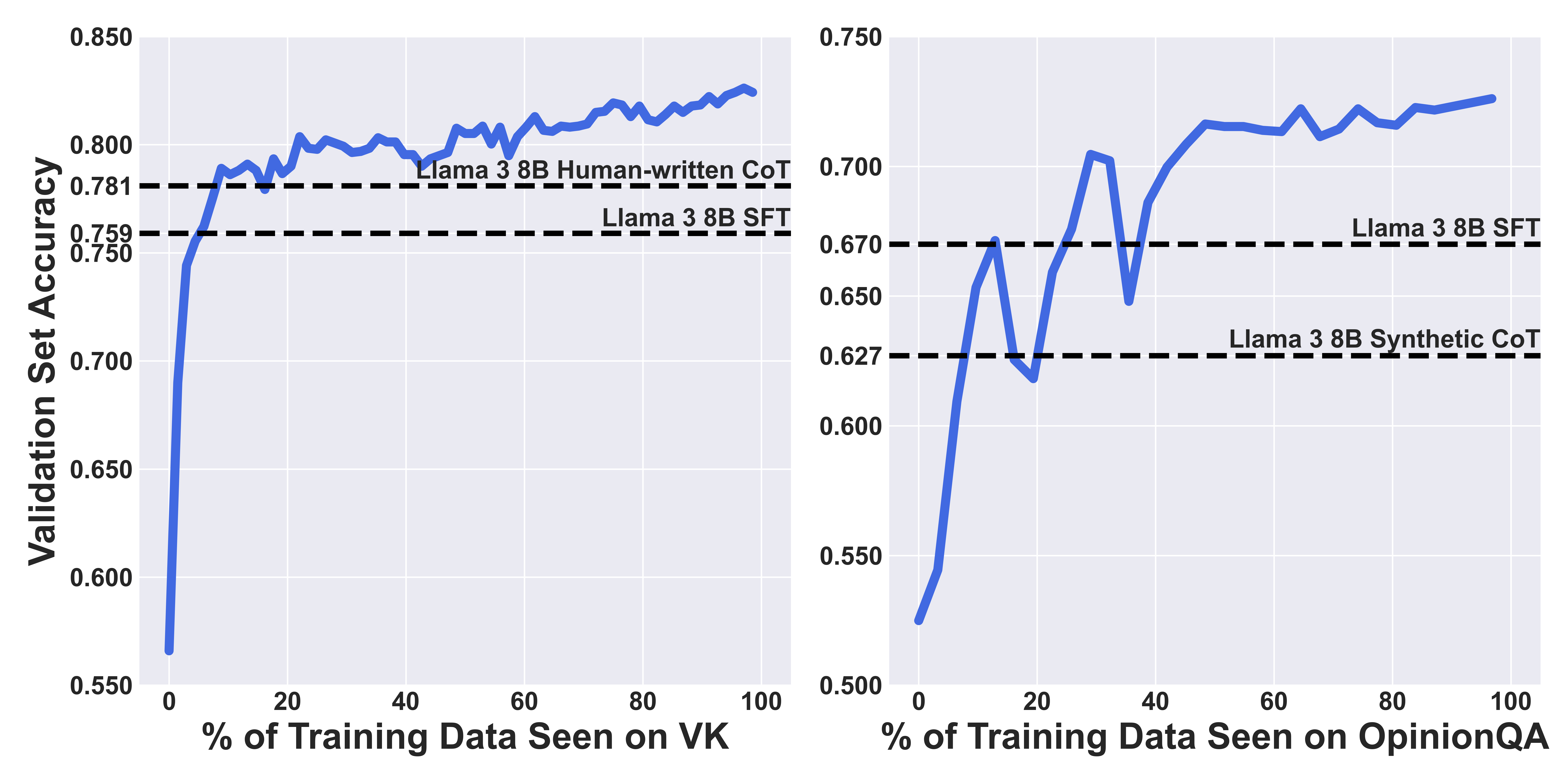
- 实验结果表明,使用可验证奖励的强化学习(RLVR)方法在性能和训练样本效率方面优于其他CoT方法。
📝 摘要(中文)
大型语言模型(LLMs)通常被训练成反映相对统一的价值观,这限制了它们在需要理解细微人类视角的任务中的适用性。最近的研究强调了使LLMs支持可控多元化的重要性——即采纳特定视角并使生成的输出与之对齐的能力。在这项工作中,我们研究了思维链(CoT)推理技术是否可以应用于构建可控的多元化模型。我们探索了几种方法,包括CoT提示、在人工编写的CoT上进行微调、在合成解释上进行微调,以及使用可验证奖励的强化学习(RLVR)。我们使用Value Kaleidoscope和OpinionQA数据集评估这些方法。在所研究的方法中,RLVR始终优于其他方法,并表现出强大的训练样本效率。我们进一步分析了生成的CoT轨迹在忠实性和安全性方面的表现。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在理解和采纳不同人类视角方面的局限性。现有LLMs通常被训练成反映相对统一的价值观,无法很好地应用于需要 nuanced 理解的任务。因此,如何使LLMs具备可控的多元化能力,即能够根据特定视角生成对齐的输出,是本文要解决的核心问题。现有方法缺乏有效控制LLM输出价值观倾向的能力,导致其在需要考虑不同观点或价值观的任务中表现不佳。
核心思路:论文的核心思路是利用思维链(Chain-of-Thought, CoT)推理技术来引导LLMs生成更符合特定视角的输出。CoT通过让LLMs逐步推理并解释其决策过程,从而增强了模型的可解释性和可控性。通过控制CoT的推理过程,可以引导LLMs采纳特定的价值观或观点,并生成与之对齐的输出。此外,论文还探索了使用强化学习(RL)来优化CoT的生成过程,使其更加符合目标视角的价值观。
技术框架:论文探索了多种基于CoT的框架,包括:1) CoT提示:直接在prompt中加入CoT推理的示例;2) 在人工编写的CoT上进行微调:使用人工标注的CoT数据对LLM进行微调;3) 在合成解释上进行微调:使用自动生成CoT数据进行微调;4) 使用可验证奖励的强化学习(RLVR):使用强化学习方法,根据CoT输出的价值观倾向给予奖励,从而优化CoT的生成过程。RLVR框架包含一个奖励模型,用于评估CoT输出的价值观倾向,并根据评估结果调整LLM的策略。
关键创新:论文的关键创新在于将强化学习与思维链推理相结合,提出了使用可验证奖励的强化学习(RLVR)方法。RLVR方法能够有效地引导LLMs生成符合特定视角的CoT输出,从而实现可控的多元化对齐。与传统的CoT方法相比,RLVR方法能够更有效地利用训练数据,并取得更好的性能。此外,论文还对生成的CoT轨迹进行了忠实性和安全性分析,从而验证了RLVR方法的有效性和可靠性。
关键设计:在RLVR框架中,奖励模型的设计至关重要。论文使用了预训练的价值观分类器作为奖励模型,用于评估CoT输出的价值观倾向。奖励函数的设计需要平衡目标视角的价值观倾向和CoT输出的流畅性。此外,论文还探索了不同的强化学习算法,例如Proximal Policy Optimization (PPO),用于优化LLM的策略。在训练过程中,需要仔细调整强化学习的超参数,以避免训练不稳定或奖励欺骗等问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用可验证奖励的强化学习(RLVR)方法在Value Kaleidoscope和OpinionQA数据集上始终优于其他CoT方法。RLVR方法表现出强大的训练样本效率,能够在较少的训练数据下取得良好的性能。此外,对生成的CoT轨迹的忠实性和安全性分析表明,RLVR方法能够生成更符合目标视角且更安全的输出。
🎯 应用场景
该研究成果可应用于需要考虑不同价值观或观点的多个领域,例如:政治辩论分析、伦理决策支持、个性化推荐系统等。通过使LLMs能够理解和采纳不同的视角,可以提高其在这些领域的应用价值。此外,该研究还可以促进人机协作,使LLMs能够更好地理解人类的需求和偏好,从而提供更个性化的服务。
📄 摘要(原文)
Large Language Models (LLMs) are typically trained to reflect a relatively uniform set of values, which limits their applicability to tasks that require understanding of nuanced human perspectives. Recent research has underscored the importance of enabling LLMs to support steerable pluralism -- the capacity to adopt a specific perspective and align generated outputs with it. In this work, we investigate whether Chain-of-Thought (CoT) reasoning techniques can be applied to building steerable pluralistic models. We explore several methods, including CoT prompting, fine-tuning on human-authored CoT, fine-tuning on synthetic explanations, and Reinforcement Learning with Verifiable Rewards (RLVR). We evaluate these approaches using the Value Kaleidoscope and OpinionQA datasets. Among the methods studied, RLVR consistently outperforms others and demonstrates strong training sample efficiency. We further analyze the generated CoT traces with respect to faithfulness and safety.