LLM Microscope: What Model Internals Reveal About Answer Correctness and Context Utilization
作者: Jiarui Liu, Jivitesh Jain, Mona Diab, Nishant Subramani
分类: cs.CL
发布日期: 2025-10-05
🔗 代码/项目: GITHUB
💡 一句话要点
LLM Microscope:利用模型内部激活预测答案正确性与上下文利用率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 模型内部激活 答案正确性预测 上下文利用 早期审计 风险控制
📋 核心要点
- 大型语言模型的可信度是关键问题,模型常自信地生成错误信息,需要有效方法来评估其输出的正确性。
- 该研究通过分析LLM内部激活,训练分类器预测答案正确性,并评估外部上下文对模型决策的影响。
- 实验表明,基于模型内部激活的分类器能以较高准确率预测答案正确性,并有效区分正确与错误的上下文。
📝 摘要(中文)
大型语言模型(LLM)虽然功能强大,但其可信度仍然是一个主要问题:模型经常以很高的置信度生成不正确的信息。虽然上下文信息可以帮助指导生成,但识别何时查询会受益于检索到的上下文以及评估该上下文的有效性仍然具有挑战性。本文利用可解释性方法来确定是否可以仅从模型的激活中预测模型输出的正确性。同时,探索模型内部是否包含关于外部上下文有效性的信号。考虑正确、不正确和不相关的上下文,并引入指标来区分它们。在六个不同模型上的实验表明,在第一个输出token的中间层激活上训练的简单分类器可以预测输出正确性,准确率约为75%,从而实现早期审计。基于模型内部的指标在区分正确和不正确的上下文方面明显优于prompting基线,防止了受污染的上下文引入的不准确性。这些发现提供了一个视角,可以更好地理解LLM的底层决策过程。代码已公开。
🔬 方法详解
问题定义:大型语言模型虽然能力强大,但其输出的正确性难以保证,模型可能会自信地给出错误答案。此外,如何判断模型是否需要外部上下文信息,以及如何评估外部上下文的有效性,也是一个挑战。现有方法难以有效利用模型内部信息来预测答案正确性,也难以区分有效和无效的上下文信息。
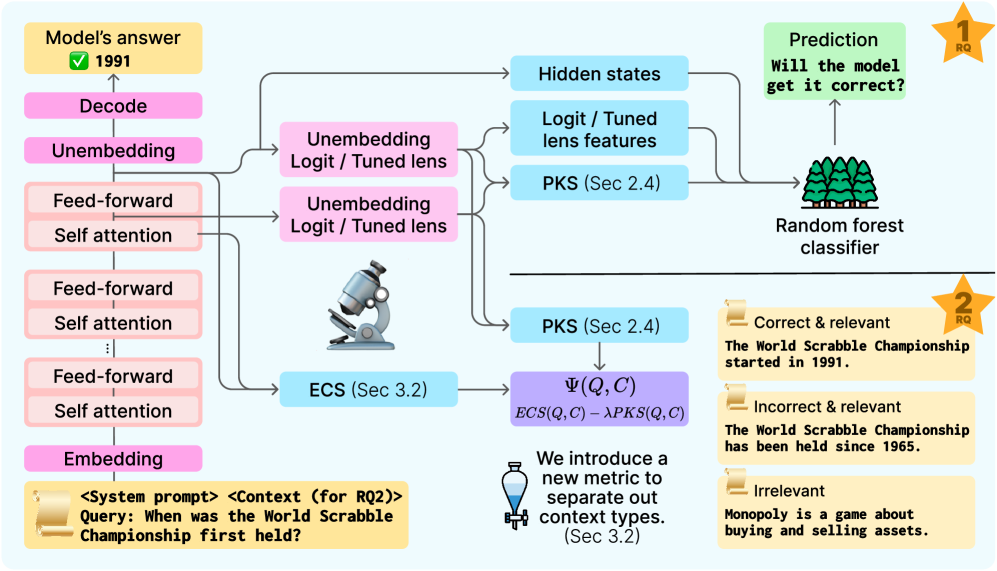
核心思路:该论文的核心思路是利用LLM的内部激活状态来预测答案的正确性,并评估外部上下文的有效性。通过分析模型在生成答案过程中的内部表征,可以了解模型对输入信息的理解程度,从而预测答案的正确性。同时,通过比较模型在不同上下文下的激活状态,可以判断上下文是否对模型的决策产生了积极影响。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集LLM在不同输入和上下文下的激活数据;2) 训练分类器,利用激活数据预测答案的正确性;3) 设计指标,评估外部上下文的有效性;4) 在多个LLM上进行实验,验证方法的有效性。具体来说,研究人员提取了LLM中间层的激活值,并将其作为分类器的输入。分类器的目标是预测答案的正确性,即判断模型生成的答案是否与真实答案一致。
关键创新:该论文的关键创新在于利用LLM的内部激活状态来预测答案的正确性,并评估外部上下文的有效性。与传统的黑盒方法不同,该研究深入分析了模型的内部表征,从而更好地理解模型的决策过程。此外,该研究还提出了一种新的指标,可以有效区分正确和错误的上下文信息,从而提高模型的可靠性。
关键设计:在实验中,研究人员使用了六个不同的LLM,包括GPT-3、GPT-J等。他们提取了模型在生成第一个token时的中间层激活值,并将其作为分类器的输入。分类器采用了简单的线性模型,并使用交叉熵损失函数进行训练。为了评估外部上下文的有效性,研究人员设计了一种基于激活值的相似度指标。该指标计算模型在不同上下文下的激活值的相似度,并将其作为判断上下文有效性的依据。
🖼️ 关键图片

📊 实验亮点
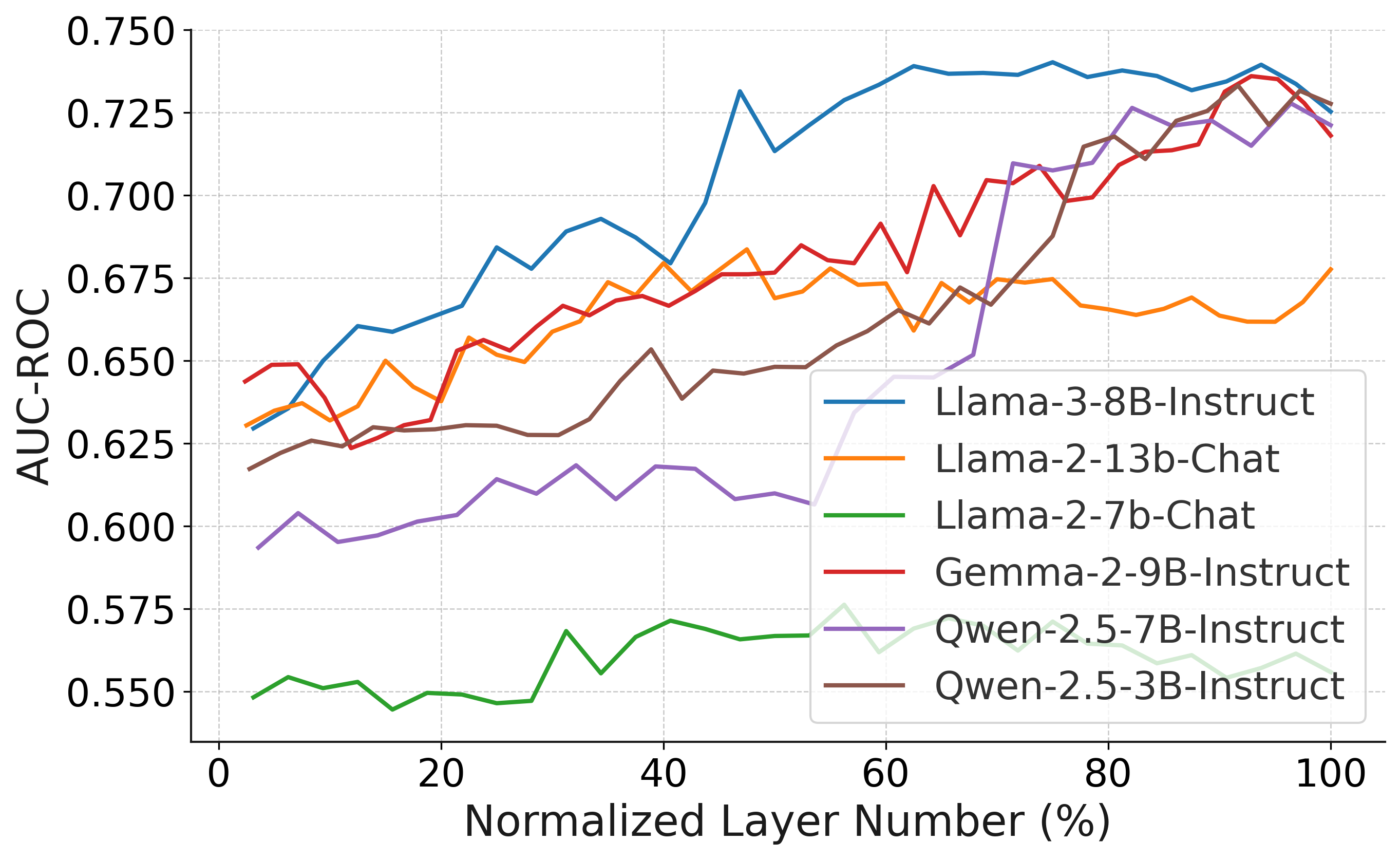
实验结果表明,基于模型内部激活的简单分类器可以以约75%的准确率预测输出的正确性。此外,该研究提出的基于模型内部的指标在区分正确和不正确的上下文方面明显优于prompting基线,能够有效防止受污染的上下文引入的不准确性。这些结果表明,模型内部信息蕴含着丰富的关于模型决策过程的信息。
🎯 应用场景
该研究成果可应用于LLM的早期审计和风险控制,帮助识别模型可能出错的情况,并及时采取干预措施。此外,该方法还可以用于评估外部上下文的质量,选择最有效的上下文信息,提高模型的生成质量和可靠性。未来,该研究可以扩展到其他类型的LLM和任务,并与其他可解释性方法相结合,进一步提高LLM的可信度。
📄 摘要(原文)
Although large language models (LLMs) have tremendous utility, trustworthiness is still a chief concern: models often generate incorrect information with high confidence. While contextual information can help guide generation, identifying when a query would benefit from retrieved context and assessing the effectiveness of that context remains challenging. In this work, we operationalize interpretability methods to ascertain whether we can predict the correctness of model outputs from the model's activations alone. We also explore whether model internals contain signals about the efficacy of external context. We consider correct, incorrect, and irrelevant context and introduce metrics to distinguish amongst them. Experiments on six different models reveal that a simple classifier trained on intermediate layer activations of the first output token can predict output correctness with about 75% accuracy, enabling early auditing. Our model-internals-based metric significantly outperforms prompting baselines at distinguishing between correct and incorrect context, guarding against inaccuracies introduced by polluted context. These findings offer a lens to better understand the underlying decision-making processes of LLMs. Our code is publicly available at https://github.com/jiarui-liu/LLM-Microscope