AgriGPT-VL: Agricultural Vision-Language Understanding Suite
作者: Bo Yang, Yunkui Chen, Lanfei Feng, Yu Zhang, Xiao Xu, Jianyu Zhang, Nueraili Aierken, Runhe Huang, Hongjian Lin, Yibin Ying, Shijian Li
分类: cs.CL
发布日期: 2025-10-05 (更新: 2025-12-07)
💡 一句话要点
AgriGPT-VL:农业视觉-语言理解套件,解决领域模型稀缺问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 农业视觉语言理解 多模态学习 大规模数据集 农业AI 视觉问答 领域自适应 课程学习
📋 核心要点
- 农业领域缺乏专门的多模态大语言模型、高质量的视觉-语言数据集以及严格的评估标准,限制了相关应用的发展。
- AgriGPT-VL套件通过构建大规模农业视觉-语言数据集,并采用渐进式课程学习方法训练农业专用视觉-语言模型,提升多模态理解能力。
- 实验表明,AgriGPT-VL在农业基准测试中优于通用VLM,同时保持了良好的文本处理能力,证明了该方法的有效性。
📝 摘要(中文)
本文提出了AgriGPT-VL套件,一个用于农业的统一多模态框架,旨在解决农业领域定制模型、高质量视觉-语言语料库和严格评估的稀缺问题。主要贡献包括:构建了迄今为止最大的农业视觉-语言语料库Agri-3M-VL,包含100万图像-标题对、200万图像-VQA对、5万专家级VQA实例和1.5万GRPO强化学习样本;开发了农业专用视觉-语言模型AgriGPT-VL,通过文本对齐、多模态浅层/深层对齐和GRPO优化进行训练,实现了强大的多模态推理能力,同时保留了纯文本能力;建立了AgriBench-VL-4K,一个紧凑但具有挑战性的评估套件,包含开放式和图像相关的问答,以及多指标评估和LLM-as-a-judge框架。实验表明,AgriGPT-VL在AgriBench-VL-4K上优于领先的通用VLM,并在LLM-as-a-judge评估中获得了更高的成对胜率。同时,在纯文本AgriBench-13K上保持了竞争力,语言能力没有明显下降。消融研究进一步证实了对齐和GRPO优化阶段的一致收益。所有资源将开源,以支持可重复的研究和在低资源农业环境中的部署。
🔬 方法详解
问题定义:农业领域缺乏专门针对农业场景的视觉-语言模型,现有的通用视觉-语言模型在处理农业相关任务时表现不佳。同时,缺乏大规模、高质量的农业视觉-语言数据集以及针对农业场景的评估基准,限制了农业视觉-语言模型的发展和评估。
核心思路:通过构建大规模农业视觉-语言数据集,并采用渐进式课程学习方法训练农业专用视觉-语言模型,从而提升模型在农业场景下的多模态理解能力。核心在于数据驱动和针对性训练,弥补通用模型在特定领域的不足。
技术框架:AgriGPT-VL套件包含三个主要组成部分:1) Agri-3M-VL数据集:通过多智能体数据生成器构建大规模农业视觉-语言数据集,包含图像-标题对、图像-VQA对等多种数据类型。2) AgriGPT-VL模型:采用渐进式课程学习方法训练农业专用视觉-语言模型,包括文本对齐、多模态浅层/深层对齐和GRPO优化等阶段。3) AgriBench-VL-4K评估基准:构建包含开放式和图像相关问答的评估基准,并采用多指标评估和LLM-as-a-judge框架进行评估。
关键创新:主要创新点在于构建了大规模农业视觉-语言数据集Agri-3M-VL,并提出了针对农业场景的渐进式课程学习方法,包括文本对齐、多模态浅层/深层对齐和GRPO优化等阶段。与现有方法相比,AgriGPT-VL更专注于农业领域,能够更好地理解和处理农业相关任务。
关键设计:在数据构建方面,采用了多智能体数据生成器,以提高数据生成效率和多样性。在模型训练方面,采用了渐进式课程学习方法,逐步提升模型的多模态理解能力。GRPO (Generative Reward Policy Optimization) 强化学习用于进一步提升模型的生成质量。具体参数设置和网络结构细节未在摘要中详细描述,需要参考论文全文。
🖼️ 关键图片


📊 实验亮点
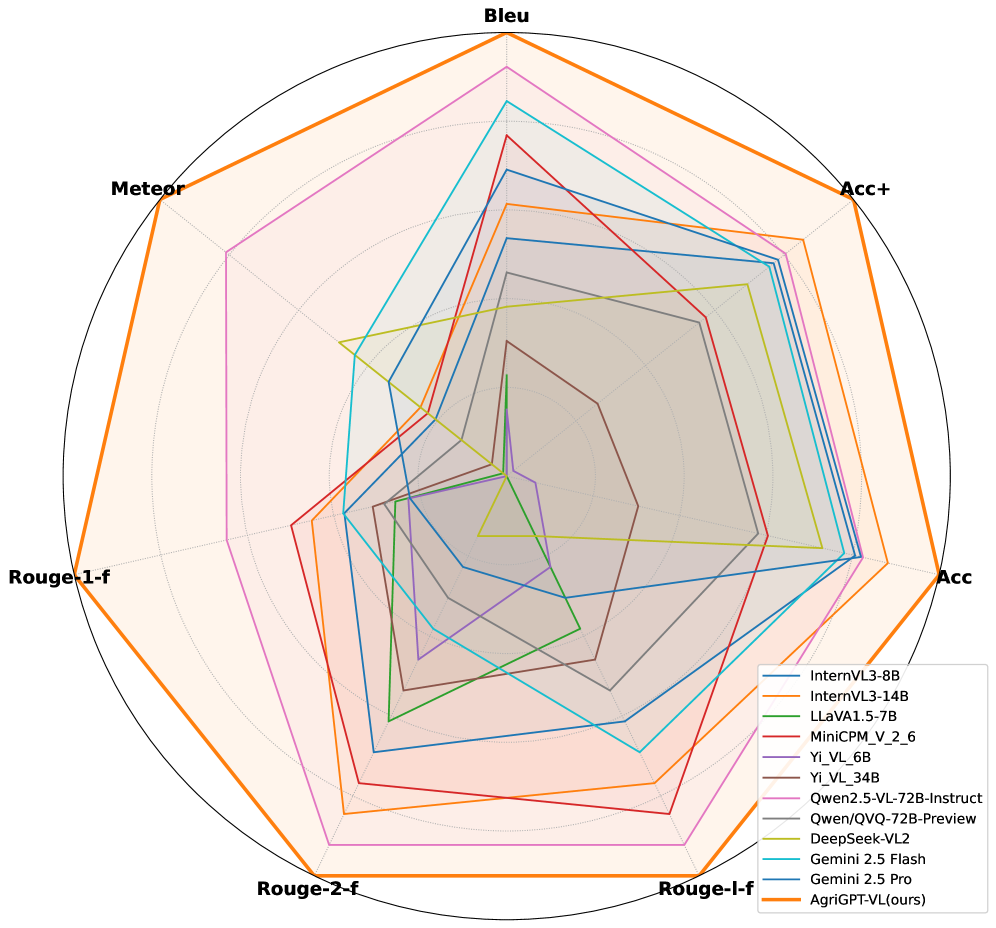
AgriGPT-VL在AgriBench-VL-4K评估基准上优于领先的通用VLM,并在LLM-as-a-judge评估中获得了更高的成对胜率。同时,在纯文本AgriBench-13K上保持了竞争力,语言能力没有明显下降。消融研究表明,对齐和GRPO优化阶段对性能提升有显著贡献。
🎯 应用场景
AgriGPT-VL可应用于智慧农业领域,例如农作物病虫害识别、农田环境监测、农业知识问答等。该研究有助于提升农业生产效率、降低生产成本、提高农产品质量,并为农业可持续发展提供技术支持。未来可进一步扩展到农业机器人、精准农业等领域。
📄 摘要(原文)
Despite rapid advances in multimodal large language models, agricultural applications remain constrained by the scarcity of domain-tailored models, curated vision-language corpora, and rigorous evaluation. To address these challenges, we present the AgriGPT-VL Suite, a unified multimodal framework for agriculture. Our contributions are threefold. First, we introduce Agri-3M-VL, the largest vision-language corpus for agriculture to our knowledge, curated by a scalable multi-agent data generator; it comprises 1M image-caption pairs, 2M image-grounded VQA pairs, 50K expert-level VQA instances, and 15K GRPO reinforcement learning samples. Second, we develop AgriGPT-VL, an agriculture-specialized vision-language model trained via a progressive curriculum of textual grounding, multimodal shallow/deep alignment, and GRPO refinement. This method achieves strong multimodal reasoning while preserving text-only capability. Third, we establish AgriBench-VL-4K, a compact yet challenging evaluation suite with open-ended and image-grounded questions, paired with multi-metric evaluation and an LLM-as-a-judge framework. Experiments show that AgriGPT-VL outperforms leading general-purpose VLMs on AgriBench-VL-4K, achieving higher pairwise win rates in the LLM-as-a-judge evaluation. Meanwhile, it remains competitive on the text-only AgriBench-13K with no noticeable degradation of language ability. Ablation studies further confirm consistent gains from our alignment and GRPO refinement stages. We will open source all of the resources to support reproducible research and deployment in low-resource agricultural settings.