Less Diverse, Less Safe: The Indirect But Pervasive Risk of Test-Time Scaling in Large Language Models
作者: Shahriar Kabir Nahin, Hadi Askari, Muhao Chen, Anshuman Chhabra
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-04 (更新: 2026-01-29)
💡 一句话要点
揭示大语言模型测试时缩放中候选多样性不足导致不安全输出的风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时缩放 安全性 多样性 对抗攻击 RefDiv 安全防护
📋 核心要点
- 现有测试时缩放(TTS)方法依赖候选答案的多样性来保证安全性,但缺乏对多样性不足情况的考量。
- 论文提出参考引导的多样性降低协议(RefDiv),通过降低候选答案的多样性来诊断TTS的安全性。
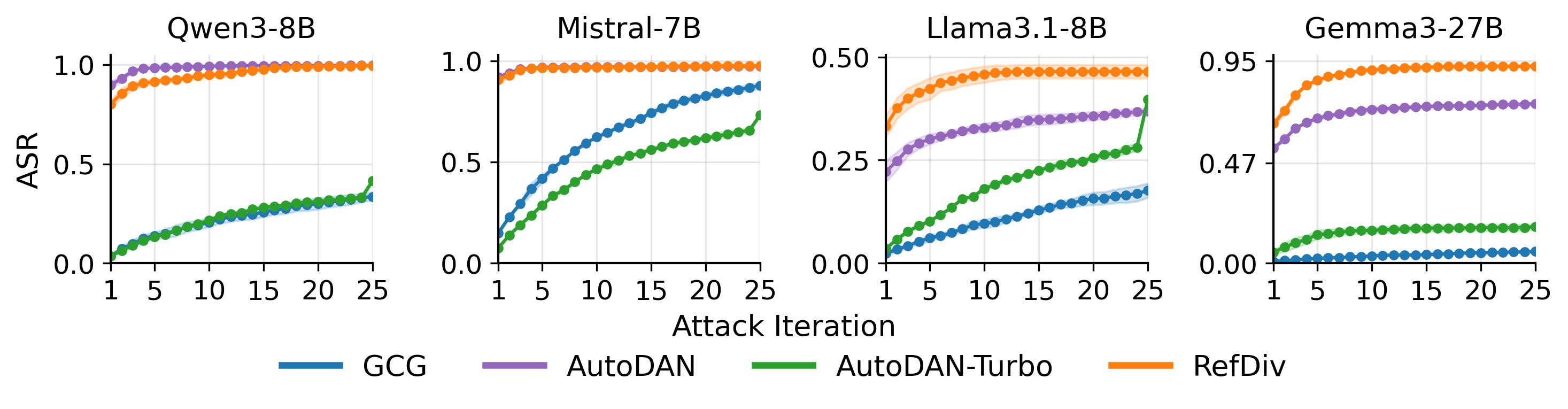
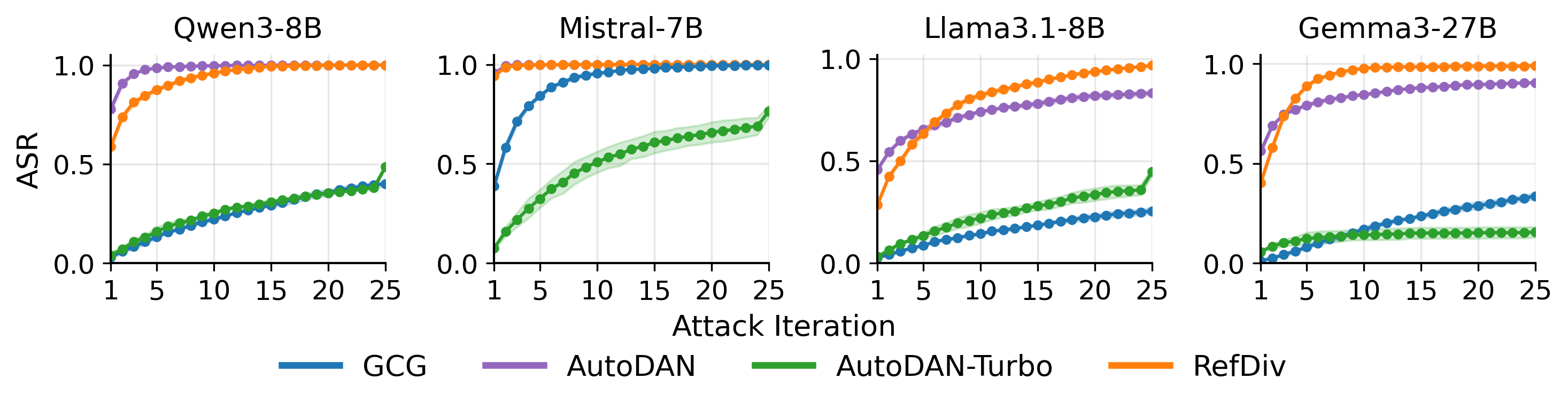
- 实验表明,降低多样性会显著增加TTS产生不安全输出的概率,且现有安全防护措施难以有效防御。
📝 摘要(中文)
测试时缩放(TTS)通过探索多个候选响应并从中选择最佳输出来提高大型语言模型的推理能力。TTS背后一个默认的假设是,足够多样化的候选池可以增强可靠性。本文表明,TTS中的这一假设引入了一种先前未被识别的失效模式。即使候选多样性受到少量限制,TTS也更有可能产生不安全的输出。我们提出了一种参考引导的多样性降低协议(RefDiv),作为一种诊断攻击来压力测试TTS流程。通过对开源模型(如Qwen3、Mistral、Llama3.1、Gemma3)和两种广泛使用的TTS策略(蒙特卡洛树搜索和Best-of-N)进行的大量实验,限制多样性始终表明TTS产生不安全结果的速率。这种影响通常比直接使用具有高对抗意图分数的提示所产生的影响更强。这种观察到的现象也转移到TTS策略和闭源模型(如OpenAI o3-mini和Gemini-2.5-Pro),表明这是一种普遍存在的TTS属性,而不是特定于模型的伪像。此外,我们发现许多广泛使用的安全防护分类器(如Llama-Guard)无法标记由RefDiv生成的对抗性输入提示,表明现有的防御措施对这种多样性驱动的失效模式提供的保护有限。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在使用测试时缩放(TTS)策略时,由于候选答案多样性不足而导致产生不安全输出的问题。现有TTS方法依赖于候选答案的多样性来提高安全性,但缺乏对多样性不足情况的有效评估和防御。
核心思路:论文的核心思路是通过主动降低候选答案的多样性,来评估TTS的安全性。如果降低多样性会导致不安全输出的概率显著增加,则表明该TTS方法对多样性不足的情况非常敏感。
技术框架:论文提出了一个参考引导的多样性降低协议(RefDiv)。RefDiv通过引入参考答案,并鼓励模型生成与参考答案相似的候选答案,从而降低候选答案的多样性。然后,使用这些多样性降低的候选答案来测试TTS的安全性。整体流程包括:1)生成初始候选答案集;2)使用RefDiv降低候选答案的多样性;3)使用TTS策略从多样性降低的候选答案集中选择最终答案;4)评估最终答案的安全性。
关键创新:论文的关键创新在于提出了RefDiv,这是一种新颖的诊断攻击方法,可以有效地评估TTS对候选答案多样性不足的敏感性。与直接使用对抗性提示相比,RefDiv能够更有效地暴露TTS的潜在安全漏洞。
关键设计:RefDiv的关键设计在于参考答案的选择和相似度度量。参考答案可以是安全的或不安全的,用于引导模型生成相应类型的候选答案。相似度度量用于衡量候选答案与参考答案之间的相似程度,并用于调整生成过程,以确保候选答案的多样性得到有效控制。论文使用了余弦相似度等常用度量方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用RefDiv降低候选答案的多样性后,TTS产生不安全输出的概率显著增加。例如,在某些模型上,不安全输出的概率增加了50%以上。此外,实验还表明,现有的安全防护分类器(如Llama-Guard)无法有效检测由RefDiv生成的对抗性输入,表明现有防御措施存在局限性。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的安全性,特别是在使用测试时缩放策略的场景下。通过使用RefDiv等方法,可以更有效地发现和修复潜在的安全漏洞,从而提高LLM在实际应用中的可靠性和安全性。此外,该研究也为开发更有效的安全防护机制提供了新的思路。
📄 摘要(原文)
Test-Time Scaling (TTS) improves LLM reasoning by exploring multiple candidate responses and then operating over this set to find the best output. A tacit premise behind TTS is that sufficiently diverse candidate pools enhance reliability. In this work, we show that this assumption in TTS introduces a previously unrecognized failure mode. When candidate diversity is curtailed, even by a modest amount, TTS becomes much more likely to produce unsafe outputs. We present a reference-guided diversity reduction protocol (RefDiv) that serves as a diagnostic attack to stress test TTS pipelines. Through extensive experiments across open-source models (e.g. Qwen3, Mistral, Llama3.1, Gemma3) and two widely used TTS strategies (Monte Carlo Tree Search and Best-of-N), constraining diversity consistently signifies the rate at which TTS produces unsafe results. The effect is often stronger than that produced by prompts directly with high adversarial intent scores. This observed phenomenon also transfers across TTS strategies and to closed-source models (e.g. OpenAI o3-mini and Gemini-2.5-Pro), thus indicating that this is a general and extant property of TTS rather than a model-specific artifact. Additionally, we find that numerous widely used safety guardrail classifiers (e.g. Llama-Guard), are unable to flag the adversarial input prompts generated by RefDiv, demonstrating that existing defenses offer limited protection against this diversity-driven failure mode.