Read Between the Lines: A Benchmark for Uncovering Political Bias in Bangla News Articles
作者: Nusrat Jahan Lia, Shubhashis Roy Dipta, Abdullah Khan Zehady, Naymul Islam, Madhusodan Chakraborty, Abdullah Al Wasif
分类: cs.CL
发布日期: 2025-10-04 (更新: 2025-11-17)
备注: Accepted to BLP at AACL-IJCNLP 2025
💡 一句话要点
构建孟加拉语政治倾向性新闻基准数据集,用于评估和提升LLM的偏见检测能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 政治倾向性检测 孟加拉语 新闻文章 基准数据集 大型语言模型 媒体偏见 立场检测
📋 核心要点
- 孟加拉语政治立场检测面临语言线索、文化背景、微妙偏见等多重挑战,缺乏标注数据集和计算研究。
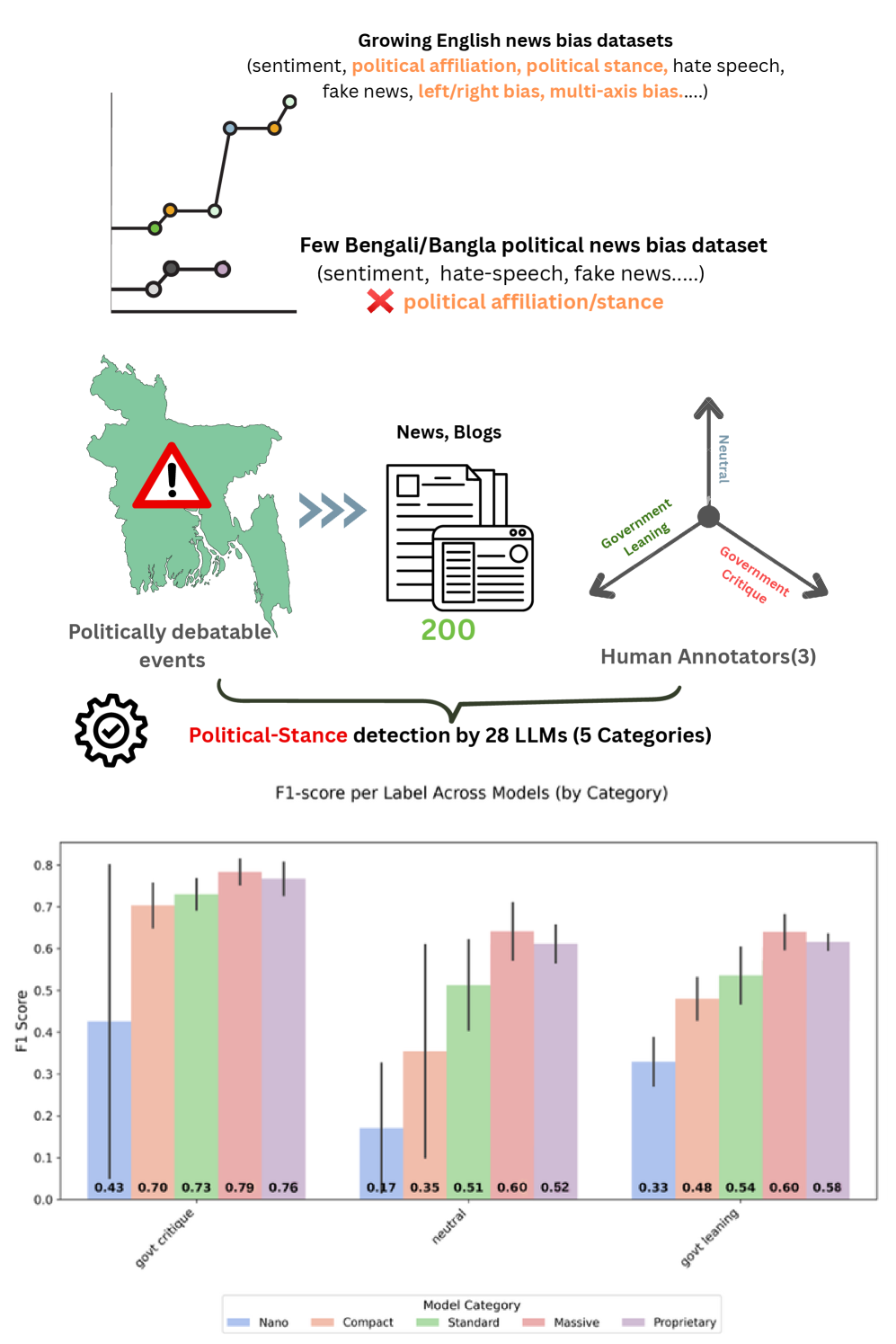
- 构建包含200篇新闻文章的基准数据集,标注政府倾向、政府批评和中立立场,并进行诊断分析。
- 实验表明,LLM在检测政府批评内容表现较好,但在识别中立文章方面存在困难,且易过度预测政府倾向。
📝 摘要(中文)
本文针对南亚地区媒体偏见检测的重要性,提出了首个孟加拉语政治倾向性新闻文章基准数据集。该数据集包含200篇具有政治意义且备受争议的孟加拉语新闻文章,并标注为政府倾向、政府批评和中立三种立场。同时,论文还对大型语言模型(LLM)进行了诊断分析。对28个专有和开源LLM的综合评估表明,模型在检测政府批评内容方面表现出色(F1值高达0.83),但在识别中立文章方面存在显著困难(F1值低至0.00)。模型还倾向于过度预测政府倾向立场,经常误解模糊叙述。该数据集及其相关诊断为推进孟加拉语媒体研究中的立场检测奠定了基础,并为提高LLM在低资源语言中的性能提供了见解。
🔬 方法详解
问题定义:该论文旨在解决孟加拉语新闻文章中政治倾向性检测的问题。现有方法缺乏针对孟加拉语的标注数据集,并且难以捕捉语言、文化和社会政治背景下的细微偏见,导致现有方法在孟加拉语政治立场检测中表现不佳。
核心思路:论文的核心思路是构建一个高质量的、包含多种政治立场标注的孟加拉语新闻文章数据集,并利用该数据集对现有的大型语言模型进行评估和诊断,从而发现模型在处理孟加拉语政治偏见检测任务中的不足,并为未来的研究提供基准和改进方向。
技术框架:该研究的技术框架主要包含两个部分:一是数据集的构建,包括新闻文章的收集、筛选和标注;二是基于该数据集对28个LLM进行评估,分析它们在不同政治立场上的表现。具体流程为:首先收集200篇具有政治意义的新闻文章,然后由人工标注团队对每篇文章进行立场标注(政府倾向、政府批评、中立),最后使用标注好的数据集对LLM进行微调或直接进行预测,并计算各项评估指标。
关键创新:该论文的关键创新在于构建了首个针对孟加拉语政治倾向性新闻文章的基准数据集。该数据集的构建考虑了孟加拉语的语言特点、文化背景和社会政治环境,能够更准确地反映孟加拉语新闻文章中的政治立场。此外,论文还对多个LLM进行了全面的评估和诊断,揭示了模型在处理孟加拉语政治偏见检测任务中的局限性。
关键设计:数据集的标注采用了三分类体系(政府倾向、政府批评、中立),标注人员需要具备相关的政治背景知识和语言理解能力。在评估LLM时,采用了F1值等指标来衡量模型在不同立场上的表现。此外,论文还分析了模型容易出错的案例,例如模型容易将模糊叙述误判为政府倾向。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有LLM在检测政府批评内容方面表现较好(F1值高达0.83),但在识别中立文章方面存在显著困难(F1值低至0.00)。模型还倾向于过度预测政府倾向立场。这些结果揭示了LLM在处理孟加拉语政治偏见检测任务中的局限性,为未来的研究提供了改进方向。
🎯 应用场景
该研究成果可应用于舆情监控、新闻内容分析、虚假信息检测等领域。通过自动检测新闻文章的政治倾向性,可以帮助用户更好地了解新闻报道的立场,从而做出更明智的判断。此外,该数据集还可以用于训练和评估新的自然语言处理模型,提高模型在低资源语言上的性能。
📄 摘要(原文)
Detecting media bias is crucial, specifically in the South Asian region. Despite this, annotated datasets and computational studies for Bangla political bias research remain scarce. Crucially because, political stance detection in Bangla news requires understanding of linguistic cues, cultural context, subtle biases, rhetorical strategies, code-switching, implicit sentiment, and socio-political background. To address this, we introduce the first benchmark dataset of 200 politically significant and highly debated Bangla news articles, labeled for government-leaning, government-critique, and neutral stances, alongside diagnostic analyses for evaluating large language models (LLMs). Our comprehensive evaluation of 28 proprietary and open-source LLMs shows strong performance in detecting government-critique content (F1 up to 0.83) but substantial difficulty with neutral articles (F1 as low as 0.00). Models also tend to over-predict government-leaning stances, often misinterpreting ambiguous narratives. This dataset and its associated diagnostics provide a foundation for advancing stance detection in Bangla media research and offer insights for improving LLM performance in low-resource languages.