Beyond Token Length: Step Pruner for Efficient and Accurate Reasoning in Large Language Models
作者: Canhui Wu, Qiong Cao, Chang Li, Zhenfang Wang, Chao Xue, Yuwei Fan, Wei Xi, Xiaodong He
分类: cs.CL, cs.AI
发布日期: 2025-10-04 (更新: 2025-11-29)
备注: 21 pages, 9 figures
💡 一句话要点
提出Step Pruner,通过紧凑推理步骤提升大语言模型效率与准确性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 推理效率 步骤剪枝 奖励函数 动态停止 过度思考
📋 核心要点
- 现有方法通过惩罚token数量来提升大语言模型推理效率,但忽略了推理步骤的实际数量,易导致模型“作弊”。
- Step Pruner (SP)框架通过步骤感知的奖励函数,奖励正确且紧凑的推理步骤,避免模型通过减少token数量来作弊。
- 实验表明,SP在四个推理基准上显著减少了token使用,并在AIME24上减少了69.7%的token使用,同时保持了高准确率。
📝 摘要(中文)
大型推理模型(LRMs)在复杂任务上表现出色,但常因过度冗长而出现“过度思考”。现有的强化学习(RL)解决方案通常通过惩罚生成的token来促进简洁性。然而,这些方法面临两个挑战:token数量少的响应并不总是对应于更少的推理步骤,并且模型可能在训练后期通过丢弃推理步骤来最小化token使用,从而产生“作弊”行为。本文提出了Step Pruner (SP),一个RL框架,通过偏好紧凑的推理步骤来引导LRM进行更高效的推理。我们的步骤感知奖励函数在惩罚冗余步骤的同时,优先考虑正确性,并对不正确的响应不予奖励,以防止错误推理的强化。此外,我们提出了一种动态停止机制:当模型的输出不再缩短时,训练停止,以防止步骤合并导致的作弊行为。在四个推理基准上的大量实验表明,SP在显著减少响应长度的同时,实现了最先进的准确性。例如,在AIME24上,SP减少了69.7%的token使用。
🔬 方法详解
问题定义:大型语言模型在复杂推理任务中表现出强大的能力,但常常产生冗长的输出,即“过度思考”。现有的通过强化学习减少token数量的方法存在问题:一是token数量少并不等同于推理步骤少;二是模型可能通过合并或删除推理步骤来减少token,从而影响推理的正确性。因此,如何引导模型进行更高效、更准确的推理,避免“过度思考”和“作弊”行为,是本文要解决的核心问题。
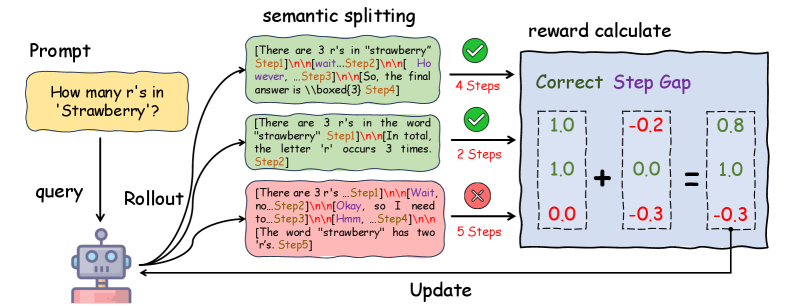
核心思路:本文的核心思路是通过强化学习,设计一种步骤感知的奖励函数,引导模型生成更紧凑的推理步骤。具体来说,奖励函数不仅考虑最终答案的正确性,还对冗余的推理步骤进行惩罚,并对错误的答案不予奖励。这种方式鼓励模型在保证正确性的前提下,尽可能减少推理步骤,从而提高推理效率。
技术框架:Step Pruner (SP) 框架主要包含以下几个关键模块:1) 大语言模型 (LRM):作为推理的主体,负责生成推理步骤和最终答案。2) 步骤感知奖励函数:根据推理步骤的正确性和紧凑性,为模型提供奖励信号。3) 强化学习算法:利用奖励信号优化LRM的策略,使其倾向于生成更高效的推理步骤。4) 动态停止机制:当模型的输出不再缩短时,停止训练,防止模型通过合并步骤来减少token数量。
关键创新:本文最重要的技术创新在于提出了步骤感知的奖励函数和动态停止机制。步骤感知的奖励函数能够更准确地评估推理过程的质量,避免了简单惩罚token数量带来的问题。动态停止机制则有效防止了模型为了减少token而合并推理步骤,保证了推理的正确性。
关键设计:步骤感知奖励函数的设计是关键。它包含三个部分:1) 正确性奖励:如果最终答案正确,则给予奖励。2) 步骤惩罚:对每个推理步骤进行惩罚,鼓励模型减少步骤数量。3) 错误惩罚:如果最终答案错误,则不给予奖励。动态停止机制的实现方式是:在训练过程中,持续监测模型输出的token数量,当token数量不再减少时,停止训练。具体的奖励函数和惩罚系数等超参数需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
Step Pruner (SP) 在四个推理基准上进行了广泛的实验,结果表明 SP 能够显著减少 token 使用量,同时保持或提高准确率。例如,在 AIME24 数据集上,SP 减少了 69.7% 的 token 使用量,并且达到了 state-of-the-art 的准确率。实验结果证明了 SP 在提高大语言模型推理效率和准确性方面的有效性。
🎯 应用场景
Step Pruner 有潜力应用于各种需要高效推理的大语言模型应用场景,例如问答系统、对话生成、代码生成等。通过减少推理过程中的冗余步骤,可以显著降低计算成本,提高响应速度,并提升用户体验。该方法还有助于提高模型的可解释性,使其推理过程更加清晰透明。
📄 摘要(原文)
Large Reasoning Models (LRMs) demonstrate strong performance on complex tasks but often suffer from excessive verbosity, known as "overthinking." Existing solutions via reinforcement learning (RL) typically penalize generated tokens to promote conciseness. However, these methods encounter two challenges: responses with fewer tokens do not always correspond to fewer reasoning steps, and models may develop hacking behavior in later stages of training by discarding reasoning steps to minimize token usage. In this work, we introduce \textbf{Step Pruner (SP)}, an RL framework that steers LRMs toward more efficient reasoning by favoring compact reasoning steps. Our step-aware reward function prioritizes correctness while imposing penalties for redundant steps, and withholds rewards for incorrect responses to prevent the reinforcement of erroneous reasoning. Moreover, we propose a dynamic stopping mechanism: when the model's output no longer shortens, training is halted to prevent hacking behavior caused by the merging of steps. Extensive experiments across four reasoning benchmarks demonstrate that SP achieves state-of-the-art accuracy while significantly reducing response length. For instance, on AIME24, SP reduces token usage by \textbf{69.7\%}.