Mechanistic Interpretability of Socio-Political Frames in Language Models
作者: Hadi Asghari, Sami Nenno
分类: cs.CL, cs.AI, cs.CY
发布日期: 2025-10-04
备注: Peer-reviewed and presented at Advances in Interpretable Machine Learning and Artificial Intelligence (AIMLAI) Workshop at ECML/PKDD 2024
💡 一句话要点
探索LLM中社会政治框架的机制可解释性,揭示模型内部认知表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机制可解释性 社会政治框架 认知表征 奇异值分解
📋 核心要点
- 现有方法难以理解LLM如何表征和处理复杂的社会政治认知框架,缺乏对模型内部机制的深入洞察。
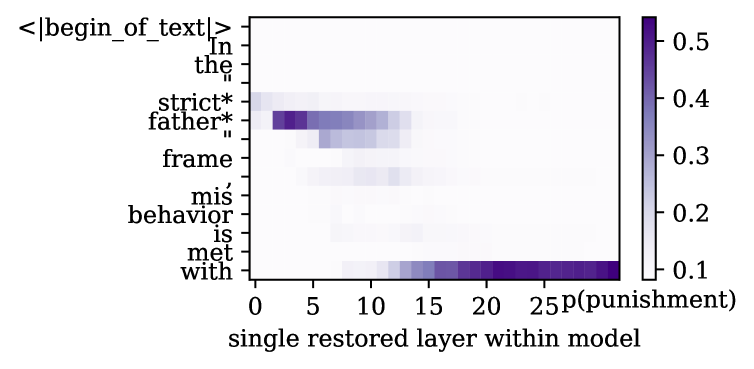
- 该研究通过机制可解释性方法,探索LLM中特定社会政治框架(如“严父”和“慈母”)的内部表征。
- 实验结果表明,LLM能够生成和识别特定框架的文本,并且在模型的隐藏层中存在与这些框架强相关的维度。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)生成和识别深层认知框架的能力,尤其是在社会政治语境中。研究表明,LLM能够流畅地生成唤起特定框架的文本,并且可以在零样本设置中识别这些框架。受到机制可解释性研究的启发,我们研究了模型隐藏层表示中“严父”和“慈母”框架的位置,识别出与这些框架的存在密切相关的奇异维度。我们的发现有助于理解LLM如何捕获和表达有意义的人类概念。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLM)如何理解和表示社会政治框架的问题。现有方法通常将LLM视为黑盒,缺乏对其内部认知过程的深入理解。因此,研究的痛点在于如何揭示LLM内部的机制,从而理解其如何捕获和表达复杂的社会政治概念。
核心思路:本文的核心思路是借鉴机制可解释性研究的方法,通过识别LLM隐藏层中与特定社会政治框架相关的神经元或维度,来理解模型如何表征这些框架。这种方法旨在将抽象的社会政治概念与模型内部的具体计算过程联系起来,从而实现对LLM的更深入理解。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建包含不同社会政治框架(如“严父”和“慈母”)的文本数据集;2) 使用LLM生成和识别这些框架的文本;3) 分析LLM隐藏层表示,识别与特定框架相关的奇异维度;4) 评估这些维度与框架之间的相关性。
关键创新:该研究的关键创新在于将机制可解释性方法应用于社会政治框架的理解。与传统的黑盒方法不同,该研究试图揭示LLM内部的机制,从而理解其如何捕获和表达复杂的社会政治概念。此外,该研究还识别出与特定框架相关的奇异维度,为进一步研究LLM的认知能力提供了新的视角。
关键设计:研究的关键设计包括:1) 选择具有代表性的社会政治框架(“严父”和“慈母”);2) 构建高质量的文本数据集,确保数据集中包含清晰的框架信号;3) 使用奇异值分解(SVD)等方法分析LLM隐藏层表示,识别与框架相关的维度;4) 使用相关性分析等方法评估维度与框架之间的关联强度。
🖼️ 关键图片

📊 实验亮点
该研究最重要的实验结果是识别出LLM隐藏层中与“严父”和“慈母”框架强相关的奇异维度。这些维度能够有效地预测文本中框架的存在,表明LLM确实能够捕获和表达这些复杂的社会政治概念。此外,研究还发现,不同的LLM模型在表征这些框架时可能存在差异,这为进一步研究LLM的认知能力提供了新的线索。
🎯 应用场景
该研究的潜在应用领域包括:1) 提高LLM在社会政治领域的应用能力,例如情感分析、舆情监控等;2) 增强LLM的透明度和可解释性,使其更易于理解和信任;3) 为开发更具社会意识和道德责任感的LLM提供理论基础。未来的影响在于促进人与AI之间的更有效沟通,并减少AI在社会政治领域产生负面影响的风险。
📄 摘要(原文)
This paper explores the ability of large language models to generate and recognize deep cognitive frames, particularly in socio-political contexts. We demonstrate that LLMs are highly fluent in generating texts that evoke specific frames and can recognize these frames in zero-shot settings. Inspired by mechanistic interpretability research, we investigate the location of the
strict father' andnurturing parent' frames within the model's hidden representation, identifying singular dimensions that correlate strongly with their presence. Our findings contribute to understanding how LLMs capture and express meaningful human concepts.