Investigating LLM Variability in Personalized Conversational Information Retrieval
作者: Simon Lupart, Daniël van Dijk, Eric Langezaal, Ian van Dort, Mohammad Aliannejadi
分类: cs.IR, cs.CL
发布日期: 2025-10-04
备注: 11 pages, 5 figures, SIGIR-AP'25 Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (SIGIR-AP 2025), December 7--10, 2025, Xi'an, China
💡 一句话要点
研究LLM在个性化对话信息检索中的变异性,强调多轮评估和方差报告的重要性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化对话信息检索 大型语言模型 变异性分析 多轮评估 方差报告
📋 核心要点
- 现有研究在个性化对话信息检索中,基于LLM的单次实验结果,对PTKB的有效性得出有争议的结论,缺乏对LLM输出变异性的充分考虑。
- 本研究通过多轮实验,评估不同LLM在TREC iKAT 2024数据集上的表现,并与人工选择的PTKB进行对比,分析LLM输出的变异性。
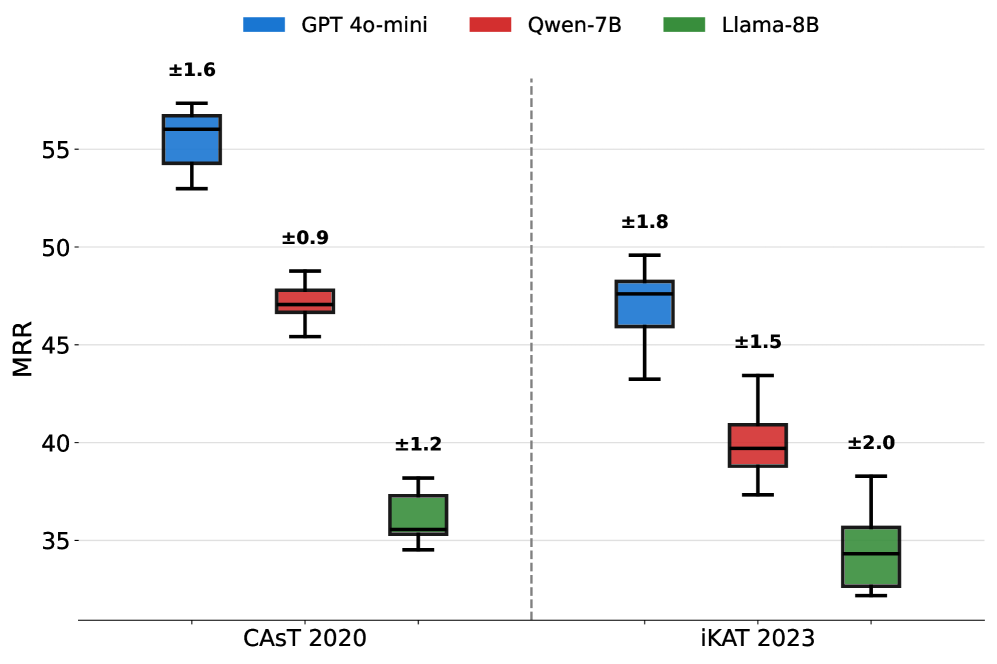
- 实验结果表明,人工选择的PTKB始终能提高检索性能,而LLM选择的PTKB效果不稳定。同时,研究强调了多轮评估和方差报告在评估LLM-based CIR系统中的重要性。
📝 摘要(中文)
近年来,大型语言模型(LLM)的发展推动了个性化对话信息检索(CIR)的快速进步。个性化CIR旨在通过利用用户特定的信息(如偏好、知识或约束)来增强文档检索,从而为个人需求定制响应。TREC iKAT 2023数据集是评估CIR管道中个性化的关键资源。Mo等人基于此资源,探索了将个人文本知识库(PTKB)纳入基于LLM的查询重构的几种策略。他们的发现表明,来自PTKB的个性化可能是有害的,并且人工标注通常存在噪声。然而,这些结论是基于使用GPT-3.5 Turbo模型的单次运行实验得出的,引发了对输出变异性和可重复性的担忧。在这项可重复性研究中,我们严格地重现并扩展了他们的工作,重点关注LLM输出变异性和模型泛化。我们将原始方法应用于新的TREC iKAT 2024数据集,并评估了包括Llama(1B-70B)、Qwen-7B、GPT-4o-mini在内的各种模型。我们的结果表明,人工选择的PTKB始终能提高检索性能,而基于LLM的选择方法并不能可靠地优于人工选择。我们进一步比较了不同数据集之间的方差,并观察到iKAT上的变异性高于CAsT,突出了评估个性化CIR的挑战。值得注意的是,面向召回率的指标比面向精确率的指标表现出更低的方差,这是对第一阶段检索器的重要见解。最后,我们强调在评估基于LLM的CIR系统时,需要进行多轮评估和方差报告。通过扩大跨模型、数据集和指标的评估,我们的研究有助于更稳健和可推广的个性化CIR实践。
🔬 方法详解
问题定义:论文旨在解决个性化对话信息检索(CIR)中,如何更可靠地评估基于大型语言模型(LLM)的个性化方法的问题。现有方法,特别是基于单次实验的评估,无法充分考虑LLM输出的变异性,导致对个性化文本知识库(PTKB)有效性的评估结果不一致。
核心思路:论文的核心思路是通过进行多轮实验,并评估不同LLM在多个数据集上的表现,来更全面地分析LLM在个性化CIR中的变异性。通过对比人工选择和LLM选择的PTKB,以及不同评估指标的方差,来揭示评估个性化CIR的挑战,并提出更稳健的评估方法。
技术框架:整体框架包括以下几个主要阶段:1) 数据集准备:使用TREC iKAT 2023和2024数据集,以及CAsT数据集。2) 模型选择:选择包括Llama (1B-70B), Qwen-7B, GPT-4o-mini等多种LLM。3) PTKB选择:对比人工选择的PTKB和基于LLM选择的PTKB。4) 实验评估:进行多轮实验,并使用多种评估指标(包括面向召回率和面向精确率的指标)来评估检索性能。5) 方差分析:分析不同数据集和评估指标的方差,以评估LLM输出的变异性。
关键创新:最重要的技术创新点在于对LLM在个性化CIR中的变异性进行了深入分析,并强调了多轮评估和方差报告的重要性。与现有方法相比,该研究不仅关注检索性能的平均值,更关注性能的稳定性,从而为评估个性化CIR系统提供了更可靠的依据。
关键设计:关键设计包括:1) 多轮实验:对每个实验设置进行多次运行,以评估LLM输出的变异性。2) 多样化的模型选择:选择不同规模和架构的LLM,以评估模型泛化能力。3) 多种评估指标:使用面向召回率和面向精确率的指标,以全面评估检索性能。4) 方差分析:计算不同数据集和评估指标的方差,以量化LLM输出的变异性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,人工选择的PTKB始终能提高检索性能,而LLM选择的PTKB效果不稳定。在iKAT数据集上的变异性高于CAsT数据集,表明评估个性化CIR的挑战性。面向召回率的指标比面向精确率的指标表现出更低的方差,这对于第一阶段检索器至关重要。研究强调了多轮评估和方差报告在评估LLM-based CIR系统中的重要性。
🎯 应用场景
该研究成果可应用于智能客服、个性化推荐系统、智能助手等领域。通过更可靠地评估LLM在个性化信息检索中的表现,可以提升用户体验,并为开发更有效的个性化信息服务提供指导。未来的影响在于推动个性化信息检索技术的进步,并促进LLM在实际应用中的更广泛应用。
📄 摘要(原文)
Personalized Conversational Information Retrieval (CIR) has seen rapid progress in recent years, driven by the development of Large Language Models (LLMs). Personalized CIR aims to enhance document retrieval by leveraging user-specific information, such as preferences, knowledge, or constraints, to tailor responses to individual needs. A key resource for this task is the TREC iKAT 2023 dataset, designed to evaluate personalization in CIR pipelines. Building on this resource, Mo et al. explored several strategies for incorporating Personal Textual Knowledge Bases (PTKB) into LLM-based query reformulation. Their findings suggested that personalization from PTKBs could be detrimental and that human annotations were often noisy. However, these conclusions were based on single-run experiments using the GPT-3.5 Turbo model, raising concerns about output variability and repeatability. In this reproducibility study, we rigorously reproduce and extend their work, focusing on LLM output variability and model generalization. We apply the original methods to the new TREC iKAT 2024 dataset and evaluate a diverse range of models, including Llama (1B-70B), Qwen-7B, GPT-4o-mini. Our results show that human-selected PTKBs consistently enhance retrieval performance, while LLM-based selection methods do not reliably outperform manual choices. We further compare variance across datasets and observe higher variability on iKAT than on CAsT, highlighting the challenges of evaluating personalized CIR. Notably, recall-oriented metrics exhibit lower variance than precision-oriented ones, a critical insight for first-stage retrievers. Finally, we underscore the need for multi-run evaluations and variance reporting when assessing LLM-based CIR systems. By broadening evaluation across models, datasets, and metrics, our study contributes to more robust and generalizable practices for personalized CIR.