Prompt Balance Matters: Understanding How Imbalanced Few-Shot Learning Affects Multilingual Sense Disambiguation in LLMs
作者: Deshan Sumanathilaka, Nicholas Micallef, Julian Hough
分类: cs.CL
发布日期: 2025-10-04
备注: Paper accepted at GlobalNLP 2025: Workshop on beyond English: Natural Language Processing for All Languages in an Era of Large Language Models" 9 pages, 3 figures, 2 Tables
💡 一句话要点
研究表明:LLM中不平衡的Few-Shot学习会影响多语言词义消歧
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 词义消歧 Few-Shot学习 大型语言模型 多语言处理 样本不平衡
📋 核心要点
- 现有Few-Shot学习方法在多语言词义消歧任务中,容易受到不平衡样本分布的影响,导致模型产生偏差。
- 通过分析不同语言在不平衡Few-Shot示例下的表现,揭示了LLM对样本分布的敏感性,并强调了平衡提示的重要性。
- 实验结果表明,不平衡的Few-Shot示例会导致多语言词义预测错误,但在英语中未观察到此现象,GPT-4o和LLaMA-3.1-70B均受影响。
📝 摘要(中文)
大型语言模型(LLM)的最新进展显著改变了自然语言处理(NLP)的格局。在各种提示技术中,Few-Shot提示因其使用的便捷性和有效性而备受关注。本研究调查了Few-Shot提示策略如何影响词义消歧(WSD)任务,特别关注由不平衡样本分布引入的偏差。我们使用GLOSSGPT提示方法(一种用于英语WSD的先进方法)来测试其在五种语言(英语、德语、西班牙语、法语和意大利语)中的有效性。结果表明,不平衡的Few-Shot示例可能导致多语言中的错误词义预测,但这个问题在英语中没有出现。为了评估模型行为,我们评估了GPT-4o和LLaMA-3.1-70B模型,结果突出了多语言WSD对Few-Shot设置中样本分布的敏感性,强调了平衡和具有代表性的提示策略的必要性。
🔬 方法详解
问题定义:论文旨在研究在使用Few-Shot提示时,样本分布的不平衡性如何影响大型语言模型在多语言词义消歧(WSD)任务中的表现。现有方法在处理多语言WSD时,没有充分考虑样本分布对模型预测的影响,容易导致模型产生偏差,尤其是在数据资源匮乏的语言中。
核心思路:论文的核心思路是探究不平衡的Few-Shot示例对LLM在多语言WSD任务中的影响。通过控制不同词义的样本数量,人为制造不平衡的数据集,观察模型在不同语言上的表现差异,从而揭示模型对样本分布的敏感性。
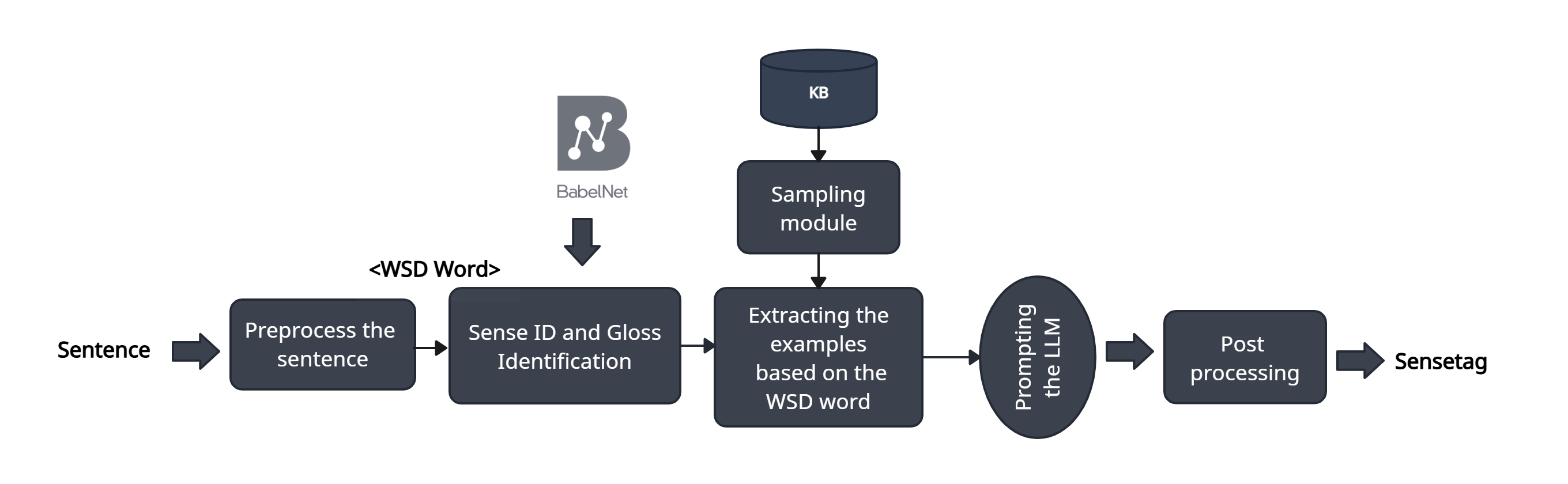
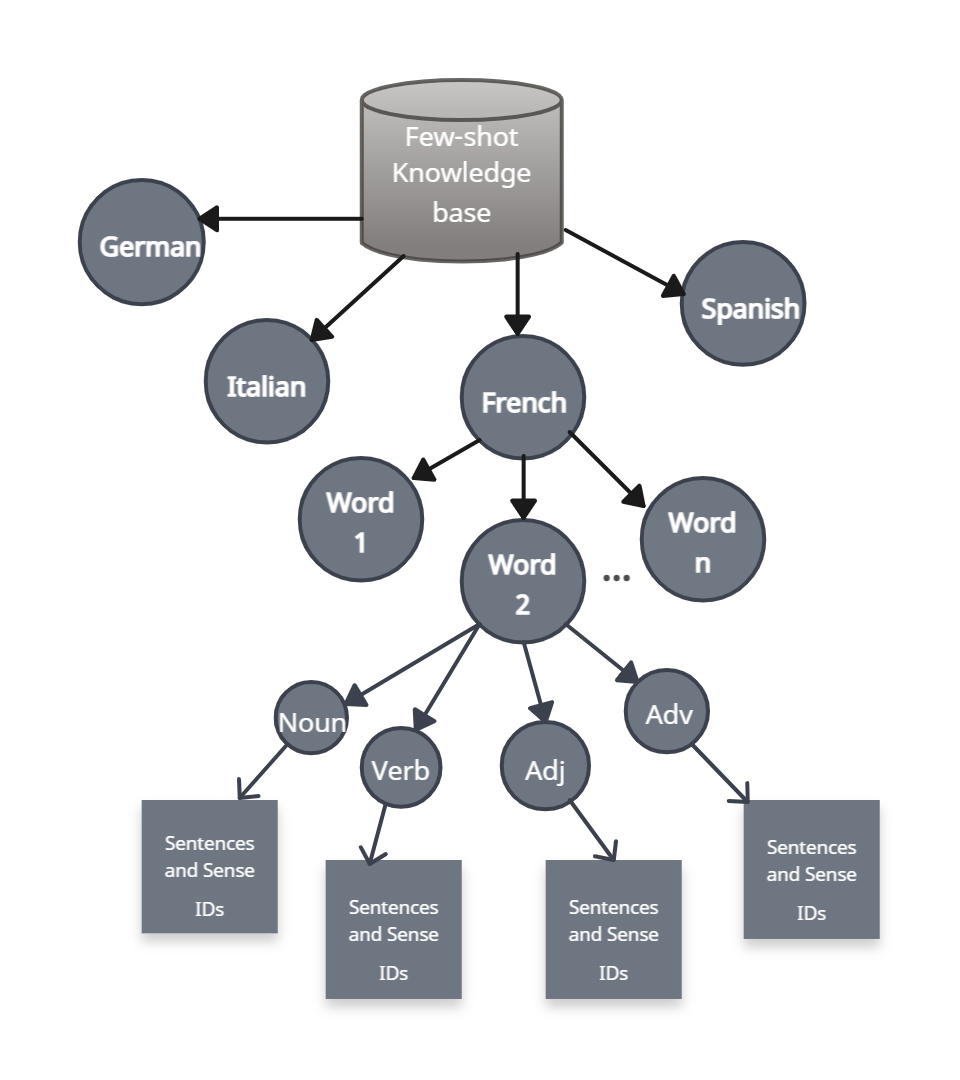
技术框架:该研究主要采用GLOSSGPT提示方法,并将其应用于五种语言(英语、德语、西班牙语、法语和意大利语)的WSD任务。研究首先构建了平衡和不平衡的Few-Shot示例集,然后使用GPT-4o和LLaMA-3.1-70B模型进行实验,最后分析模型在不同语言和不同样本分布下的预测结果。
关键创新:该研究的关键创新在于发现了不平衡的Few-Shot示例会对多语言WSD任务产生显著影响,而这种影响在英语中并不明显。这表明LLM在处理多语言WSD时,对样本分布的敏感性存在差异。
关键设计:研究的关键设计包括:1)使用GLOSSGPT作为基线方法;2)构建平衡和不平衡的Few-Shot示例集,通过控制不同词义的样本数量来模拟不平衡情况;3)选择GPT-4o和LLaMA-3.1-70B作为评估模型;4)采用准确率作为评估指标,比较模型在不同语言和不同样本分布下的表现。
🖼️ 关键图片
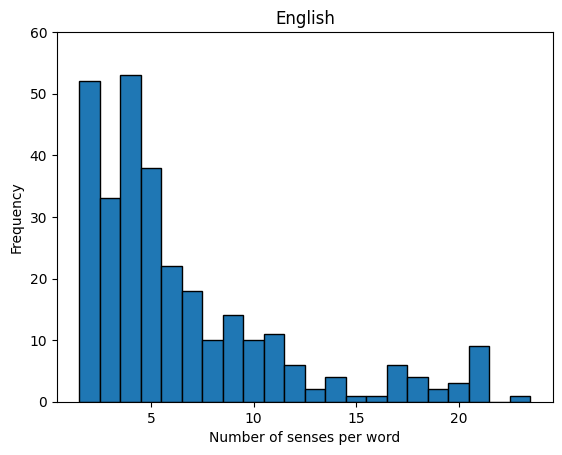
📊 实验亮点
实验结果表明,不平衡的Few-Shot示例会导致多语言词义预测错误,但在英语中未观察到此现象。具体来说,GPT-4o和LLaMA-3.1-70B模型在处理不平衡的Few-Shot示例时,在德语、西班牙语、法语和意大利语上的WSD准确率显著下降,表明模型对样本分布的敏感性。该研究强调了在多语言WSD任务中采用平衡提示策略的重要性。
🎯 应用场景
该研究成果可应用于提升多语言自然语言处理系统的性能,尤其是在资源匮乏的语言中。通过采用平衡的Few-Shot提示策略,可以减少模型偏差,提高词义消歧的准确性。此外,该研究也为LLM在多语言环境下的应用提供了指导,有助于开发更可靠、更公平的跨语言NLP系统。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have significantly reshaped the landscape of Natural Language Processing (NLP). Among the various prompting techniques, few-shot prompting has gained considerable attention for its practicality and effectiveness. This study investigates how few-shot prompting strategies impact the Word Sense Disambiguation (WSD) task, particularly focusing on the biases introduced by imbalanced sample distributions. We use the GLOSSGPT prompting method, an advanced approach for English WSD, to test its effectiveness across five languages: English, German, Spanish, French, and Italian. Our results show that imbalanced few-shot examples can cause incorrect sense predictions in multilingual languages, but this issue does not appear in English. To assess model behavior, we evaluate both the GPT-4o and LLaMA-3.1-70B models and the results highlight the sensitivity of multilingual WSD to sample distribution in few-shot settings, emphasizing the need for balanced and representative prompting strategies.