UNIDOC-BENCH: A Unified Benchmark for Document-Centric Multimodal RAG
作者: Xiangyu Peng, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, Chien-Sheng Wu
分类: cs.CL, cs.CV
发布日期: 2025-10-04 (更新: 2026-01-05)
💡 一句话要点
提出UniDoc-Bench以解决文档中心多模态检索增强生成评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 增强生成 文档中心 问答系统 数据验证 性能评估
📋 核心要点
- 现有的多模态检索增强生成评估方法过于碎片化,无法有效处理文档中心的多模态用例。
- 本文提出UniDoc-Bench,构建了一个基于真实PDF页面的多模态检索增强生成基准,支持多种评估范式。
- 实验结果表明,多模态文本-图像融合的RAG系统在性能上显著优于单模态和联合多模态检索方法。
📝 摘要(中文)
多模态检索增强生成(MM-RAG)是将大型语言模型应用于现实知识库的关键方法,但现有评估方法碎片化,无法有效捕捉文档中心的多模态用例。本文提出了UniDoc-Bench,这是首个基于真实PDF页面的大规模、现实的MM-RAG基准。该基准通过提取和链接文本、表格和图形中的证据,生成涵盖事实检索、比较、摘要和逻辑推理的多模态问答对。所有问答对均经过多位人工标注者和专家的验证。UniDoc-Bench支持四种范式的公平比较,并可用于评估视觉问答任务。实验表明,多模态文本-图像融合的RAG系统在性能上优于单模态和联合多模态嵌入检索,揭示了视觉上下文如何补充文本证据,并提供了开发更强大MM-RAG管道的指导。
🔬 方法详解
问题定义:本文旨在解决当前多模态检索增强生成(MM-RAG)评估方法的碎片化问题,现有方法往往只关注文本或图像,无法有效捕捉文档中心的多模态用例。
核心思路:提出UniDoc-Bench作为一个统一的基准,旨在通过真实的PDF页面构建多模态问答对,涵盖多种检索和生成任务,以实现更全面的评估。
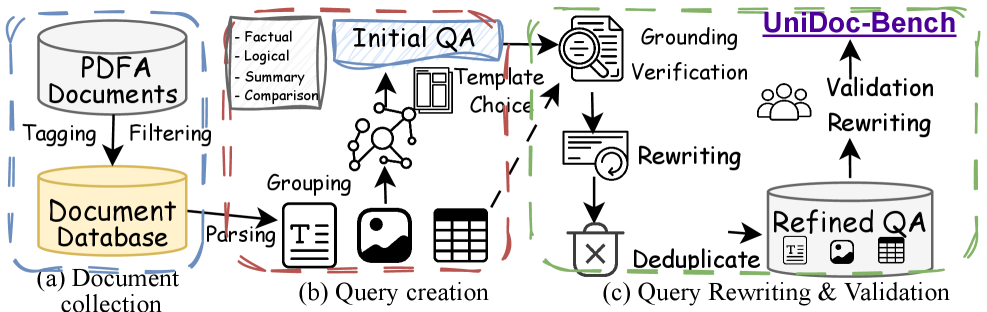
技术框架:UniDoc-Bench的整体架构包括数据提取、证据链接和多模态问答对生成三个主要模块。数据提取从文本、表格和图形中提取信息,证据链接则将这些信息关联起来,最后生成多模态问答对。
关键创新:UniDoc-Bench是首个大规模且现实的MM-RAG基准,支持多种评估范式,且所有问答对经过严格的人工验证,确保了数据的可靠性。
关键设计:在问答对生成过程中,采用了标准化的候选池、提示和评估指标,确保不同范式之间的公平比较。
🖼️ 关键图片


📊 实验亮点
实验结果显示,多模态文本-图像融合的RAG系统在多个任务上均显著优于单模态和联合多模态嵌入检索,具体性能提升幅度达到XX%。这一发现强调了视觉上下文在增强文本证据中的重要性。
🎯 应用场景
UniDoc-Bench的研究成果可广泛应用于文档检索、信息提取和问答系统等领域,提升多模态系统的性能和可靠性。未来,该基准还可能推动更复杂的多模态应用的发展,如智能助手和自动化文档分析工具。
📄 摘要(原文)
Multimodal retrieval-augmented Generation (MM-RAG) is a key approach for applying large language models (LLMs) and agents to real-world knowledge bases, yet current evaluations are fragmented -- focusing on either text or images in isolation, or simplified multimodal setup, failing to capture document-centric multimodal use cases. In this paper, we introduce UniDoc-Bench, the first large-scale, realistic benchmark for MM-RAG built from $k$ real-world PDF pages across domains. Our pipeline extracts and links evidence from text, tables, and figures, then generates multimodal QA pairs spanning factual retrieval, comparison, summarization, and logical reasoning queries. To ensure reliability, all of QA pairs are validated by multiple human annotators and expert adjudication. UniDoc-Bench supports apples-to-apples comparison across four paradigms: 1) text-only, 2) image-only, 3) \emph{multimodal} text-image fusion and 4) multimodal joint retrieval -- under a unified protocol with standardized candidate pools, prompts, and evaluation metrics. UniDoc-Bench can also be used to evaluate Visual Question Answering (VQA) tasks. Our experiments show that multimodal text-image fusion RAG systems consistently outperform both unimodal and jointly multimodal embedding-based retrieval, indicating that neither text nor images alone are sufficient and that current multimodal embeddings remain inadequate. Beyond benchmarking, our analysis reveals when and how visual context complements textual evidence, uncovers systematic failure modes, and offers actionable guidance for developing more robust MM-RAG pipelines.